Recovery
Transaktionsverwaltung
Transaktion und ACID Eigenschaften
Folge von Datenbank-Operationen mit den Eigenschaften
Atomicity
Atomare Ausführung (ohne logische Unterbrechung)
Consistency
Datenbank davor und danach in einem konsistenten Zustand sein muss (während der Operation aber nicht zwingend)
Isolation
Parallel laufende Transaktionen dürfen sich nicht gegenseitig beeinflussen.
Durability
Persistenz, auch nach Systemfehler oder Stromausfall (dann verliert man alles im Arbeitsspeicher)
Atomicity, Durability durch Recovery in DBMS.
Isolation durch Concurrency / Mehrbenutzersynchronisation in DBMS.
Operation
→ wobei eine lokale Variable ist
Transaktionskontrolle
Begin of transaction
Von Arbeitsspeicher zu Festspeicher
Operationen aus Transaktion zurücksetzen aus Arbeitsspeicher
ermöglicht rollback bis savepoint (zusätzlich zu vollständigem)
Mögliche Abschlüsse einer Transaktion
- commit
- abort Aufruf
- Fehler → abort durch DBMS
Speicherverwaltung
Zweistufige Speicherhierarchie
Hauptspeicher / RAM schnell, aber flüchtig
Festplatte / Storage langsam, aber persistent, billiger
Speicherorganisation mit Pages
Einheit zum Verschieben von Datensätzen zwischen Speichern.
Auslagern RAM Storage
Einlagern RAM Storage
Datensatz kann mehrere pages umfassen.
Annahme: nur ein Datensatz per Seite
Fixierung von pages
Während page access sind sie fixiert mit fixed-bit und dürfen nicht ausgelagert werden.
Auslagerungs-Strategie
Auslagern von Pages: RAM
Auslagern vor
alle nicht fixierte pages dürfen ausgelagert werden.
zusätzlich dürfen sie in keiner aktiven Transaktion verändert worden sein.
ansonsten muss man sie bei einem rollback auch in der storage überschreiben.
Auslagern nach
erzwungenes Auslagern am Ende jeder Transaktion.
teuer, vor allem bei "hot-spots"
pages am Transaktionsende mit dirty-bit markieren - auslagern optional.
bessere performance, wenn page beliebt - nicht immer neu einlagern.
Beimuss Transaktion gesamte page sperren und nicht einzelne Datensätze.
Auslagern von Pages: Storage
Update-in-Place (direkte Strategie)
Jede page hat einen eindeutigen Platz im storage die überschrieben wird
Twin-block-verfahren (indirekte Strategie)
Jede page hat 2 Kopien im storage + bit dass sagt welche aktuell ist
aktuelle kopie wird überschrieben
Schattenspeicherkonzept (indirekte Strategie)
nur jede mindestens 1x veränderte hat 2 Kopien im storage
Auslagerungs-Strategie Recovery-Art
Fehlerkategorien
-
Fehler mit Verlust von Storage
Nur mit backup / archiv wiederherstellbar
-
Fehler mit Verlust von RAM
Abgeschlossene Transaktionen (Winner) müssen rekonstruiert werden (globales redo)
Abgebrochene Transaktionen (Loser) müssen zurückgesetzt werden (globales undo)
-
Lokale Fehler in einer Transaktion
Eigentlich ein Spezialfall vom oberen Fehler (lokales undo)
Es gilt:
Angenommene Systemkonfiguration:
Auslagerungsstrategie
Update-In-Place
Write-ahead-log WAL
Wird durch obere Konfiguration erfordert.
Alle Log-Einträge müssen vor + Auslagerung der page ausgeschrieben werden.
Chronologische Reihenfolge der Logs muss erhalten bleiben.
Kleine Sperrgranulate
Zugriffsmatrix erweitert mit mehr Locks
Logging
LSN Logs
LSN Log Sequence Number: ID von log
TransaktionsID ID von Transaktion
PageID ID von page die von operation betroffen ist -ein log pro page
Redo
Undo
PrevLSN Pointer zur vorherigen Log-ID vondieserTransaktion
Logging in pages
Jede page erhält auch die LSN vom Log der jüngsten Operation die auf sie ausgeführt wurde.
Physische Protokollierung vs. Logische Protokollierung
Physisch
In der Praxis verwendet
Redo und Undo enthalten ganze Zustände "images": "after image", "before image"
Dienen auch als zusätzliche Redundanz.
Logisch
Operationen
Implementierung
Logs in Hauptspeicher als Ringbuffer (getrennt vom restlichen Speicherbereich).
Kontinuierliches Ausschreiben für gleichmäßige Lastverteilung.
Log-storage kann zusätzlich auch ein backup haben.
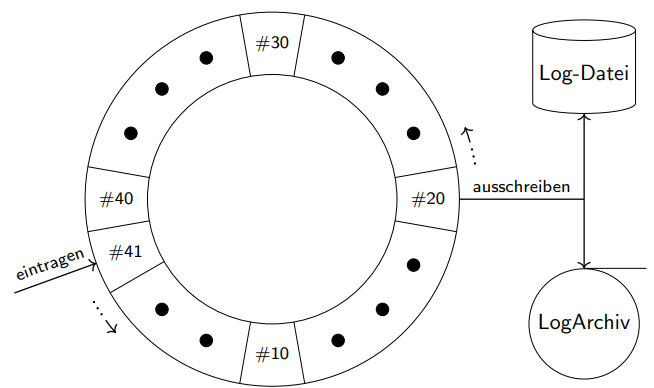
CLR Logs
Compensation log record
LSN
TransaktionsID
PageID
Redo Hat keine undo Information
PrevLSN Älteste LSN von Transaktion welche hiermit rückgängig gemacht wurde
UndoNxtLSN LSN welche als nächstes rückgängig gemacht werden soll (bis)
Recovery-Algorithmus
Winner müssen rekonstruiert werden
Loser müssen rückgängig gemacht werden
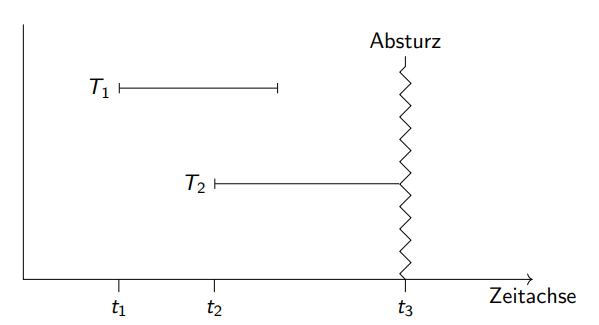
Ablauf
- Analyse
Aus der Log Datei Loser (ohne ) finden.
Älteste LSN für alle Transaktionen finden.
- Redo: aller Transaktionen
alle logs werden von Anfang an inkl. CLRs durchgegangen:
rekonstruiert wenn log-LSN > page-LSN in storage
In der Praxis hat man mit physischen logs die after-images vom ältesten log.
- Undo: aller Loser-Transaktionen
zusätzlich CLR-logs machen (sollte System währenddessen nochmals abstürzen)
Ablauf:
In umgekehrter Reihenfolge alle Logs durchgehen.
-
Älteste LSN der Transaktion zurücksetzen
Bzw aus der Liste entfernen wenn die Operation war.
-
CLR erstellen mit
CLR-PrevLSN:= ältesteLSNder Transaktion welche gerade zurückgesetzt wird (kann auch von einer CLR sein)CLR-UndoNxtLSN:= entnommeneLog-PrevLSNaus dem zurückgesetzten Log-Eintrag
page-LSNaufCLR-LSNsetzen
-
Älteste LSN der Transaktion zurücksetzen
Lokales Zurücksetzen
,
Erhöhte Effizienz, indem Log-Einträge die noch im RAM sind benutzt werden können
Ablauf:
- Älteste LSN bestimmen von Transaktion
- Lokale Änderungen rückgängig machen
Checkpoints
Savepoint
Zeitpunkt bis zu der man lokal zurücksetzt
Checkpoint / Sicherungspunkt
Zeitpunkt bei der man alle Transaktionen commited (damit die Analyse vom aller ersten log anfangen muss)
Checkpoint-Arten
bestimmt die älteste benötigte LSN
Transaktions-Konsistente checkpoints
Blockiert gesamtes System.
Kein redo/undo ab checkpoint notwendig.
Ablauf:
- Checkpoint anmelden
- Neue Transaktionen blockieren und warten lassen, alle anderen Transaktionen commiten
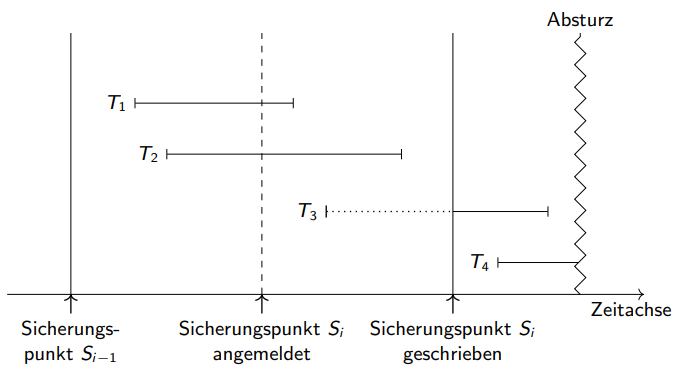
Aktions-Konsistente checkpoints
Es werden nur alle Schreiboperationen blockiert - Leseoperationen werden zugelassen.
Undo nötig bis zur kleinsten LSN
MinLSN
von allen Transaktionen die während checkpoint aktiv waren.
Ablauf:
- Checkpoint anmelden (strichlierte Linie)
- Neue Änderungsoperationen blockieren und warten lassen, alle pages ausschreiben.
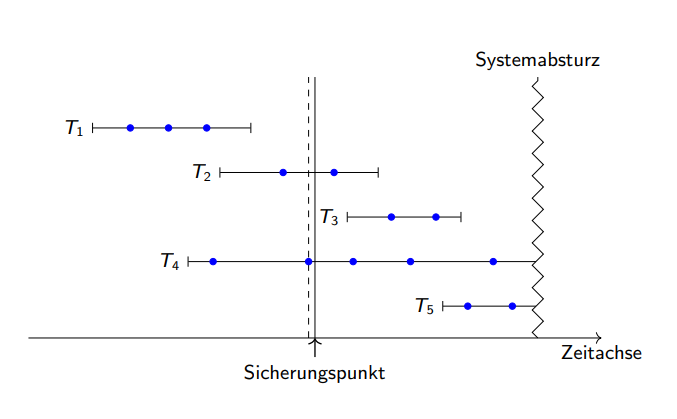
Fuzzy checkpoints
Es gibt gleichmäßig verteilte checkpoints.
Alle pages mit
dirty-bit=1
werden kontinuiertlich ausgeschrieben.
Gleichmäßige Lastverteilung.
Redo ab
MinDirtyPageLSN
Wird immer mitgespeichert: älteste LSN an dirty-pages die noch nicht ausgeschrieben wurden.
Undo nötig bis zur kleinsten LSN
MinLSN
von allen Transaktionen die während checkpoint aktiv waren.
Hot-Spot s können lange nicht ausgeschrieben werden da sie fixiert sind → Deshalb wird ein counter geführt um pages die mehrmals bearbeitet wurden zum Ausschreiben zu zwingen.