Decision Trees
Decision Trees
Can be seen multipe ways:
- As a function
Both input and output can be discrete or continuous.
vector of attribute values a single output value called decision
Can be any function of the input attributes.
- As a binary tree
decision is reached by performing a sequence of tests (from root to leaf).
Edges: possible value of the input attributes
Leafs: possible decisions
Goal: Finding a tree that is consistent with the examples and as small as possible.
Each training set has a consistent decision tree: one path to leaf for each example but it won’t generalize to new examples.
We want to learn the most compact tree.
We can not efficiently search through trees.
But there are simple heuristics to find a good approximate solution.
A more expressive hypothesis space :
increases the chance that target function can be expressed
but the hypotheses consistent with the training set may get worse predictions.
Learning a good hypothesis
We want a small, flat decision tree with subsets that are all positive or negative.
Examples (Training Set)
Set of pairs where are the input attributes and are the decisions (boolean output).
Decision-Tree-Learning DTL
Greedy divide-and-conquer algorithm: queue sorted by the "most important attribute".
/*
- examples: (x, y) pairs
- attributes: attributes of values x_1, x_2, ... x_n in x in example
- classification: y_j = true / false
*/function DTL(examples, attributes, parent_examples) returns a decision tree
if examples is empty then return MAJORITY(parent_examples.classifications)
else if all examples have the same classification then return the classification
else if attributes is empty then return MAJORITY(examples.classification)
else
A = empty
for each Attribute A' do
A ← maxImportance(A, A', examples)tree ← a new decision tree with root test Afor each (value v of A) do //all possible values from domain of A
exs ← {e : e ∈ examples | e.A = v} //all examples where this value occured
subtree ← DTL(exs, attributes\{A}, examples) //recursive call
add a new branch to tree with label "A = v" and subtree subtreereturn treeThe algorithm is recursive, every sub tree is an independent problem with fewer examples and one less attribute.
The returned tree is not identical to the correct function / tree . It is a hypothesis based on examples.
- no examples left
then it means that there is no example with this combination of values → We return a default value: the majority function on examples in the parents.
- Remaining examples are all positive or negative
we are done
- no attributes left but both positive and negative examples
These examples have the same description but different classifications, we return the plurality-classification (Reasons: noise in data, non determinism)
- some positive or negative examples
choose the most important attribute to split and repeat this process for subtree
Defining importance
We choose the attribute with most importance - Which attribute is the best predictor for the classification?
The one with the highest information gain.
Entropy
Information gain measured with entropy
Entropy measures uncertainty of the occurence of a random variable in [shannon] or [bit].
Entropy of a random variable with values each with probability is defined as:
Entropy is at its maximum when all outcomes are equally likely.
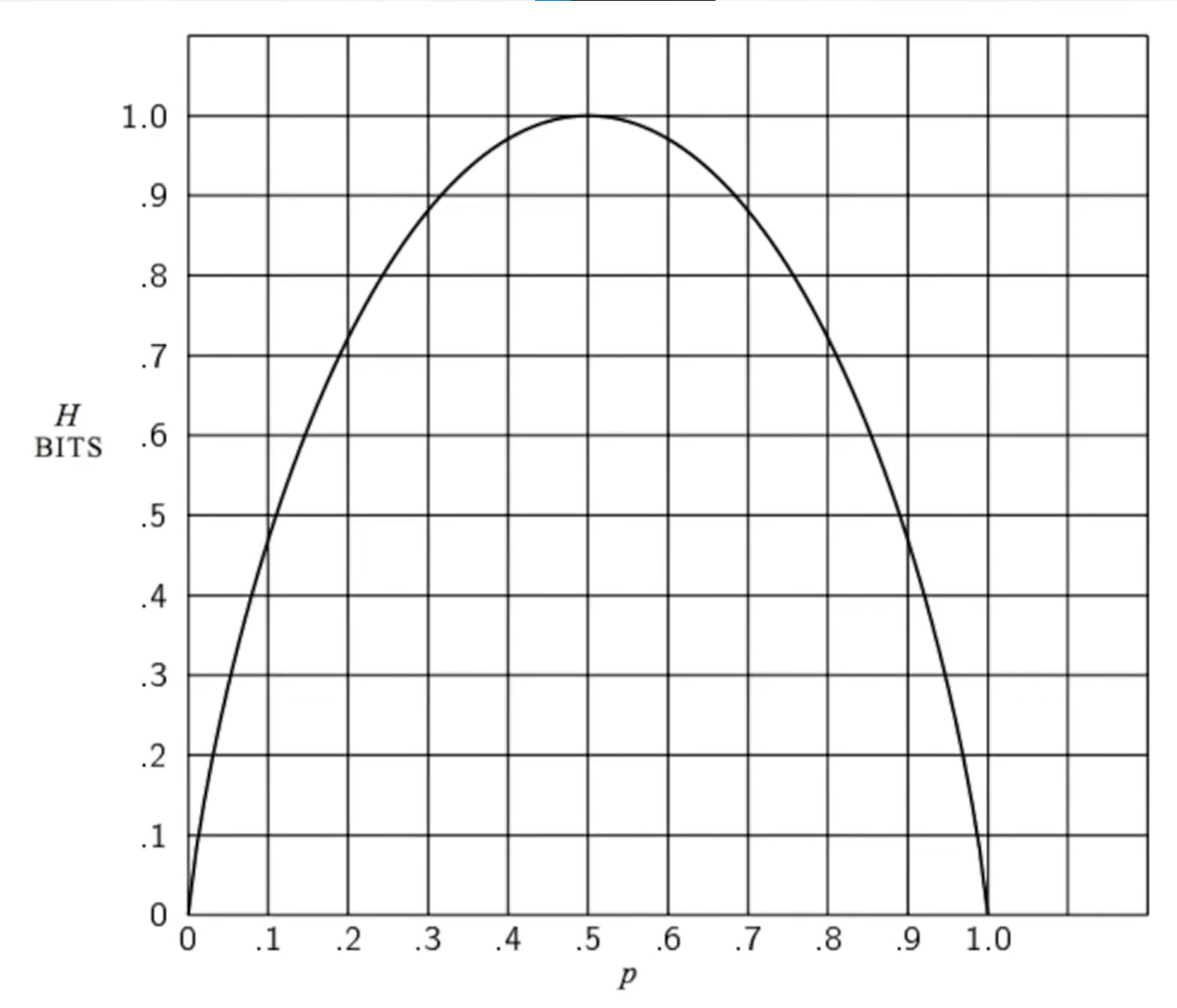
Entropy of a boolean random variable
Boolean random variable : Variable is true with probability and false with .
Same formula as above.
Entropy of the goal attribute
If a training set contains positive and negative examples then the entropy of the goal attribute on the whole set is
Remainder
Entropy remaining after testing a single attribute.
We treat each attribute like a random variable with possible subsets for each value.
Each value occurs in positive and negative training set examples. (index stands for the subset we are currently in).
The probability that specific value occuring (based on our the training set):
Therefore the expected entropy remaining after testing the attribute is:
Gain
Information gain from an attribute → defines importance.
The information gain from an attribute is the reduction of its entropy after testing.
Where defines how many questions we need to ask on average until we reach a decision.
Rem vs. Gain
Rem and gain contradict eachother
Rem tells us the randomness / distribution of data
Gain tells us the usefulness of data
Our goal is to reach a decision with the fewest number of required tests.
Broadening the applicability of decision trees
While extending the applicability of decision trees a number of issues arise.
Missing data
Often not all the attributes are known in every example. → consider all possible values, weighted with frequency to reach the test node (by the examples)
Multivalued attributes
When an attribute has many possible values, then the information gain measure gives an inappropriate indication of the usefulness. → use gain ratio, test different values at different tree heights, normalize the gain with the entropy of
Continuous and integer-valued input attributes
Instead of branching infinitely use split points (Age > 35) with the highest information gain.
(Splitting is the most expensive part of real-world decision tree learning applications)
Continuous-valued output attributes
For numerical predictions like prices: regression trees whose leaves are functions of a subset of the attributes.