With rewards / punishment. - agents decides which actions were most responsible for it.
supervised learning
Input-output pairs that agent learns a function from.
semi-supervised learning
A back and forth between supervised and unsupervised learning - agent is given a few labeled examples that it must guess the unlabeled
examples of a large collection from.
Mix of labeled and unlabeled examples but not all the given labels are correct - there is systematic noise in the data, that agent must
detect and consider without supervision.
Supervised Learning
the aim is to find a simple hypothesis that is approximately consistent with training examples
Training set (of data points)
Example input-output pairs:
(x1,y1),(x2,y2),...,(xn,yn)
Where each
yi
was generated by an
unknown functionf(x)=y
Task of agent
Discover a function
hhypothesis
that approximates the true function
f
.
Learning: search through the
hypothesis spaceH
for one that performs well even for examples beyond the training set.
We say a problem is
realizable
if the
f∈H
. (We dont always know because the true function is unknown).
Variations
If function is stochastic we have to learn a
conditional probability distributionP(Y∣x).
If output is out of a finite / discrete set of values then the problem is called
boolean / binary classification.
If output is a number the problem is called
regression
.
Test set
Measures the accuracy of the hypothesis.
If it performed well one says it
generalized
well.
If the hypothesis agrees with all the data then it is called a
consistent hypothesis
.
Choosing hypotheses
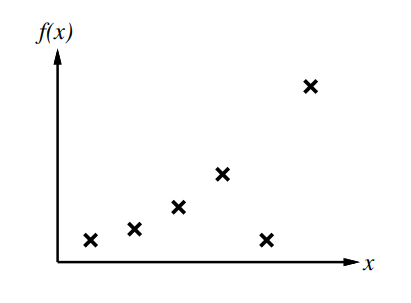
Curve fitting
Were searching a hypothesis function for this example.
No consistent straight line for this data set.
6 data points → 5th degree polynomial for exact fit but does not generalize well.
Ockham's Razor: "Maximize simplicity under consistency"
How do we choose among all the consistent hypothesis in the hypothesis space? → We choose the most simple one.
h
is consistent if it agrees with
f
on all examples.
Tradeoff between complexity and simplicity
precision, fitting training data
vs.
generalizing, finding patterns
complex hypotheses - fit the data well
vs.
simpler hypotheses- might generalize better
Choosing hypothesis spaces
Why not choose the space of all possible turing machine instructions? Then we would cover every possible computable function.
We want our hypothesis
h(x)
to be useful and fast to compute.
Fitting a straight line to data is an easy computation but fitting turing machines is impossible.
Tradeoff between expressiveness and complexity
expressiveness of the hypothesis space (quanitity)
vs.
finding a good hypothesis in it (quality)
Generalization and overfitting
The DTL algorithm will use any pattern it finds in the examples even if they are not correlated.
Overfitting
occurs when a function is too closely aligned to training set - then it does not generalize well.
↑
likelyhood of overfitting if
↑
hypothesis space,
↑
number of inputs / attributes (hypothesis may consider irrelevant attributes ie. color of dices)
↓
likelyhood of overfitting if
↑
examples.
To lower likelyhood of overfitting:
Ockham's Razor: "Maximize simplicity under consistency"
We choose the most simple consistent hypothesis. - simpler hypotheses might generalize better
Choose hypothesis space with lower expressiveness
remove unneccessary attributes from input
use more examples
Cross-Validation
: Use part of the data for training, part for testing
Overfitting
occurs when a function is too closely aligned to training set - then it does not generalize well.
↑
likelyhood of overfitting if
↑
hypothesis space,
↑
number of inputs / attributes (hypothesis may consider irrelevant attributes ie. color of dices)
↓
likelyhood of overfitting if
↑
examples.
To lower likelyhood of overfitting:
Ockham's Razor: "Maximize simplicity under consistency"
We choose the most simple consistent hypothesis. - simpler hypotheses might generalize better
Choose hypothesis space with lower expressiveness
remove unneccessary attributes from input
use more examples
Cross-Validation
: Use part of the data for training, part for testing
Decision tree pruning
Combats overfitting, eliminates nodes that are not clearly relevant after tree got generated.
How do we detect nodes that is testing an irrelevant attribute?
Imagine being at a node with
pk
positive and
nk
negative examples, if the attribute is irrelevant we would expect it to split the examples into subsets that have roughly the
same proportion of positive examples as the whole set.
Now we know what amount of gain is insufficient, but what information gain is suffucient for splitting on a particular attribute? →
statistical
significance test
.
Measuring Learning Performance
How do we know that
h≈f
? (Hume’s Problem of Induction)
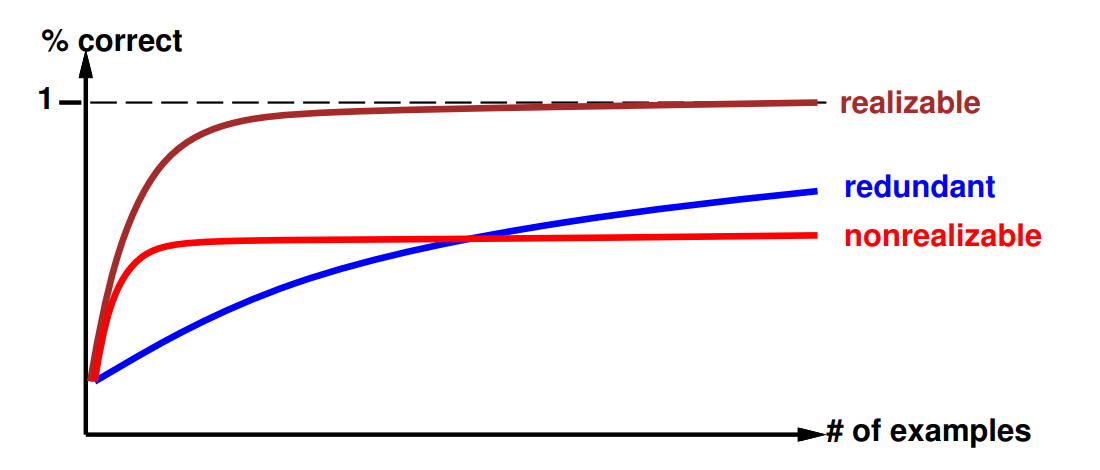
Learning curve
= % correct on test set when using
h
Learning curve depends on
realizability
of the target function.
Non-realizability can be due to
missing attributes
too restrictive hypothesis space (e.g.,linear function)
redundant expressiveness (e.g., loads of irrelevant attributes)