Linear Classification
Hard threshold
A decision boundary is a line (or a surface, in higher dimensions) that separates two classes. Then line then is called a linear separator.
Example
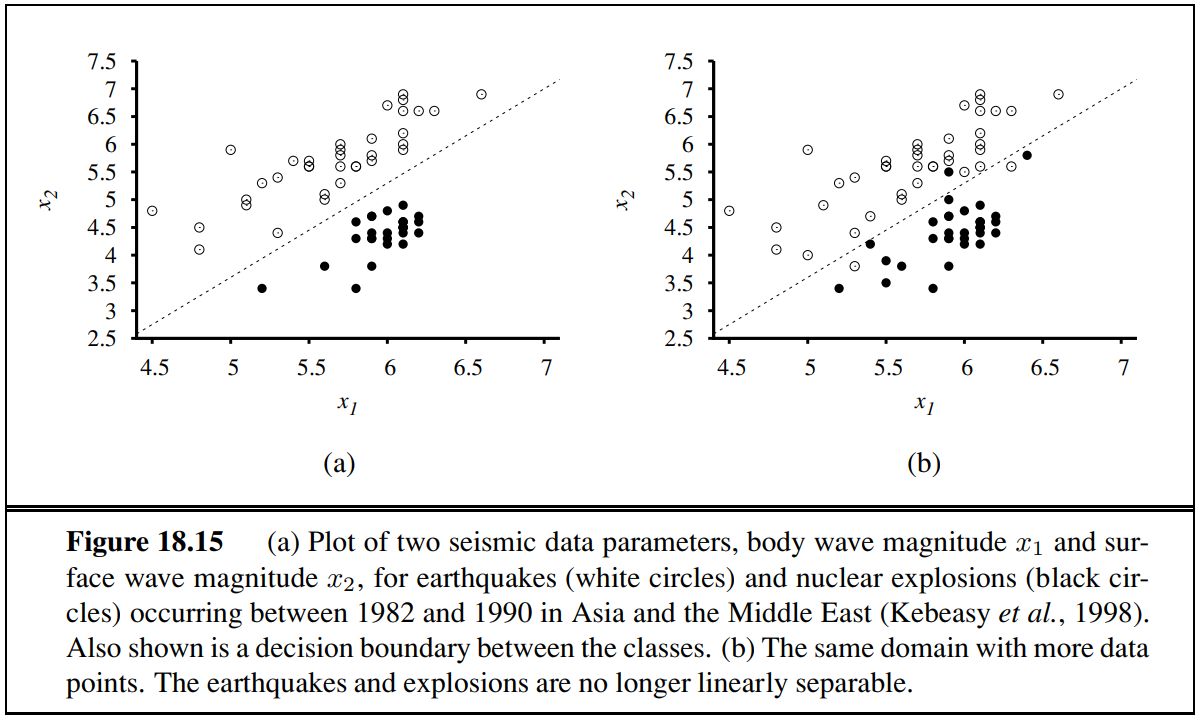
Given these training data, the task of classification is to learn a hypothesis that will take new points and return either for earthquakes or for explosions.
Using the convention of a dummy input we can write the classification hypothesis as:
Alternatively one could see it as a threshold function where is the threshold .
We want to choose the weights to minimize the loss.
Previously in linear regression we did this both in closed form (by setting the gradient to zero and solving for the weights) and by gradient descent in weight space (hill climb algorithm).
Now we cannot do either of those things because the gradient is zero almost everywhere in weight space except at those points where , and at those points the gradient is undefined.
Perceptron learning rule
Weight update rule that converges to the optimal solution most of the time (a linear separator that classifies the data perfectly if data is linearly seperable) - but very slowly.
For multiple examples: Applied like in stochastic gradient decent for each individual weight:
We only consider a single randomly chosen example at a time with the equation for single training examples.
More efficient, can be done online with data constantly coming in - however, it does not guarantee convergence. It can oscillate around the minimum without settling down.
How does exactly it work?
We have our currect output and the output of the examples with a given .
-
Our weights are correct. stays unchanged.
-
and
Our weights are incorrect. We want to make
If is positive gets increased
If is negative gets decreased
-
and
Our weights are incorrect. We want to make
If is positive gets decreased
If is negative gets increased
Soft threshhold
The previous hypothesis is not differentiable, discontinuous, very unpredictable.
It also always announces a completely confident prediction of 1 or 0, even for examples that are very close to the boundary - we often want more granularity in predictions.
We therefore now want to use the sigmoid funcion . It converges slower than the hard threshold but behaves a lot more predictable.
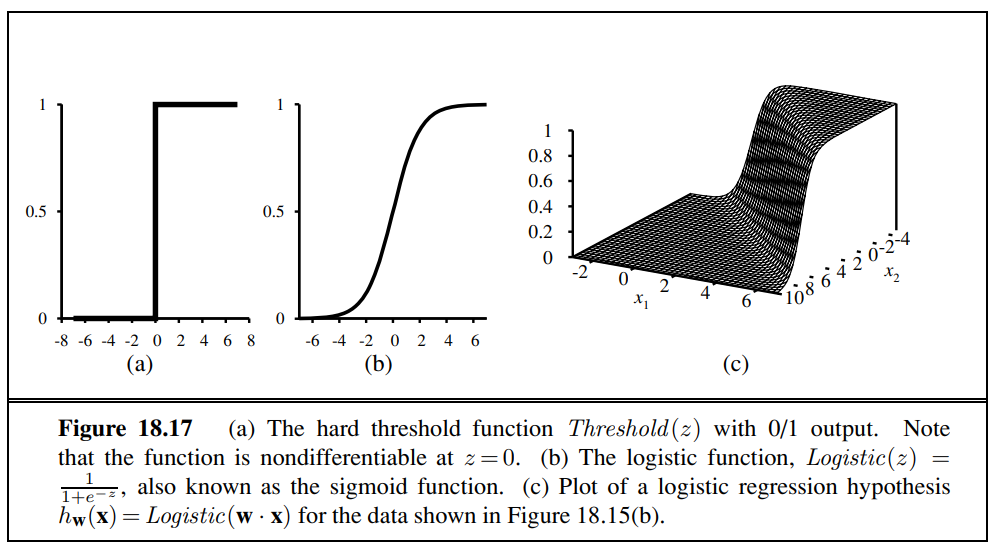
Notice that the output, being a number between 0 and 1, can be interpreted as a probability of belonging to the class labeled 1.
Logistic Regression
The process of fitting the weights of this model to minimize loss on a data set is called logistic regression.
There is no easy closed-form solution to find the optimal value of → Search for minimal loss by gradient descent:
We can use the function again because our hypotheses .
One training example
Because of the chain rule for:
The derivative of the logistic function satisfies
so we have
so the weight update for minimizing the loss is