Exam on 2012-10-02
1. Formalize a STRIPS action
2. What is a consistent plan? What is a solution?
Solution
The solution to a declared planning-problem is a plan:
Any action sequence that when executed in the initial state - results in a state that satisfies the goal.
Every action sequence that maintains the partial order is a solution.
(The in POP algorithm the goal is therefore only defined by not having open preconditions)
Consistent actions
Chosen actions should not undo the progress made.
Consistent plans (in partial order planning)
Must be free of contradictions / cycles in the ordering constraint set :
Must be free of conflicts in the casual links set : precondition must remain if .
3. Describe the two possible ways to search in the state space search
-
Totally ordered plan searches
Search in strictly linear order.
- progression planing: initial stategoal
-
regression planing:
initial stategoal
(possible because of declarative representation of PDDL and STRIPS)
-
Partial-order planning
Order is not specified.
4. What are the differences between ADL and STRIPS?
STRIPS
- only positive literals in states
- closed-world-assumption: unmentioned literals are false
- Effect means add and delete
- only ground atoms in goals
- Effects are conjunctions
- No support for equality or types
ADL
- positive and negative literals in states
- open-world-assumption: unmentioned literals are unknown
- Effect means add and delete and
- goals contain quantor
- goals allow conjunction and disjunction
- conditional effects are allowed: means is only an effect if is satisfied
- equality and types built in
5. Risk aversion
Given:
- lottery
- the expected monetary value
- Utility function
What would the risk averse agent prefer or ?
Answer:
as we gain more money, its utility does not rise proportionally.
The Utility for getting your first million dollars is very high, but the utility for the additional million is smaller.
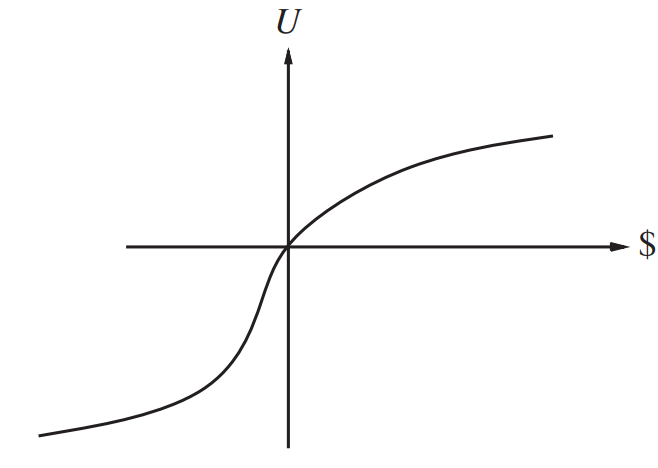
For the risk averse agent:
the utility of being faced with that lottery than the utility of being handed the expected monetary value of the lottery with absolute certainty
6. The axioms of utility theory
- Orderability
The agent must have a preference.
- Transivity
- Continuity
If there is a probability for which the agent would be indifferent to
getting with absolute certainty
or with probability and with
- Substitutability
If agent is indifferent to and then agent is indifferent to complex lotteries with same probabilities.
- Monotonicity
Agent prefers a higher probability of the state that it prefers.
- Decomposability
Compound lotteries can be reduced to simpler ones.
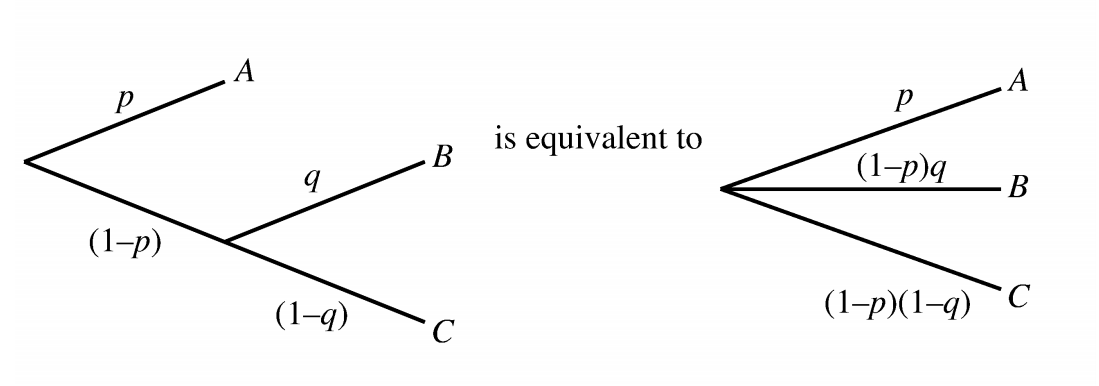
If an agent violates these axioms it will exhibit irrational behaviour.
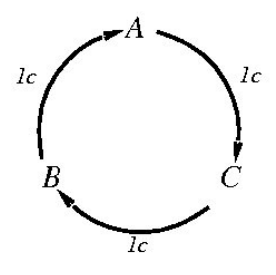
Example: intransitive preferences
Agent can be induced to give away all its money:
Agent has
- We offer + 1 cent for (agent accepts)
- We offer + 1 cent for (agent accepts)
- We offer + 1 cent for (agent accepts)
We repeat all over again.
7. Components of a decision network
Chance nodes (ovals) random variables
Decision nodes (rectangles) points where decision maker has a choice of actions
Utility nodes (diamonds) agent’s utility function
8. How do the nodes get expanded in uninformed search algorithms?
The node expansion is definied by the goal testing (at expansion / at generation) and the used datastructure for the frontier-set.
- Breadth-first search BFS Frontier as queue.
- Uniform-cost search UCS Frontier as priority queue ordered by costs.
- Depth-first search DFS Frontier as stack.
- Depth-limited search DLS DFS limited with - returns a subtree/subgraph.
- Iterative deepening search IDS Iteratively increasing in DLS to gain completeness.
9. Given admissible heuristics . Which one is the best?
Admissibility
Optimistic, never overestimating, never negative.
goals: (follows from the above)
Dominance
For two admissible heuristics, we say dominates , if:
Then is better for search.
Therefore we must choose the admissible heuristic that dominates all the others.
10. Admissible heuristics have a problem with graph search. Which one is it? How can this problem be solved?
For the optimality of the A* solution in graphs the heuristic must be consistent.
If decreases during optimal path to goal it is discarded by graph-search.
(But in tree search it is not a problem since there is only a single path to the optimal goal).
Solutions to problem:
- consistency of (non decreasing on every path)
- additional book-keeping
11. What is inductive learning?
Types of learning
analytical / deductive learning : going from general rule to more specific and efficient rule
Inductive Learning : discovering the general rule from examples
- Ignores prior knowledge
- Assumes a deterministic, observable "environment"
- Assumes examples are given (selection of examples for training set is challenging)
- In its simplest form: learning a function from examples
- Assumes agent wants to learn
Learning a function from examples (= supervised learning)
the aim is to find a simple hypothesis that is approximately consistent with training examples
Training set (of data points)
Example input-output pairs:
Where each was generated by an unknown function
Task of agent
Discover a function hypothesis that approximates the true function .
Learning: search through the hypothesis space for one that performs well even for examples beyond the training set.
We say a problem is realizable if the . (We dont always know because the true function is unknown).
Variations
- If function is stochastic we have to learn a conditional probability distribution.
- If output is out of a finite / discrete set of values then the problem is called boolean / binary classification.
- If output is a number the problem is called regression .
Test set
Measures the accuracy of the hypothesis.
If it performed well one says it generalized well.
If the hypothesis agrees with all the data then it is called a consistent hypothesis .
12. What is a learning curve?
How do we know that ? (Hume’s Problem of Induction)
Learning curve = % correct on test set when using
Learning curve depends on realizability of the target function.
Non-realizability can be due to
- missing attributes
- too restrictive hypothesis space (e.g.,linear function)
- redundant expressiveness (e.g., loads of irrelevant attributes)
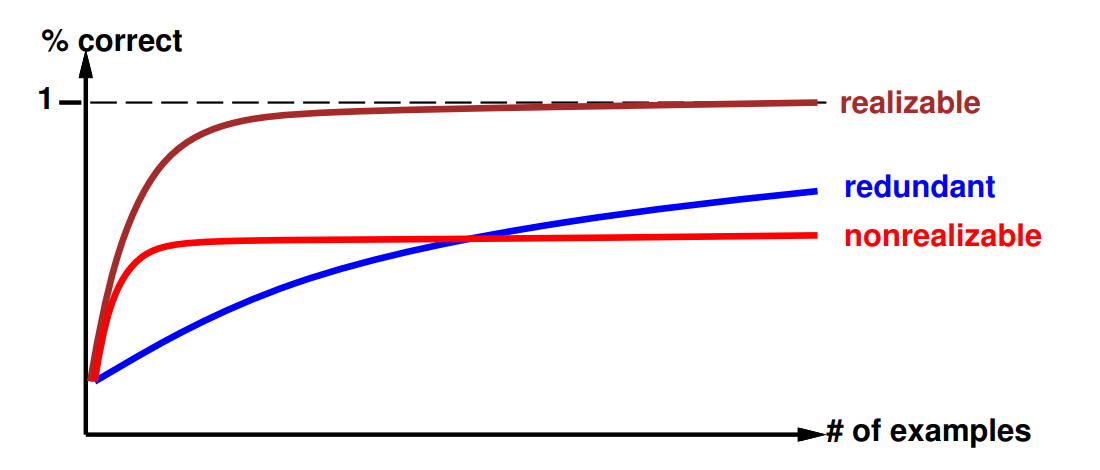
13. Learning agents and their components
Goal: making agents improve themselves by studying their own experiences
Learning Agent = performance element + learning element
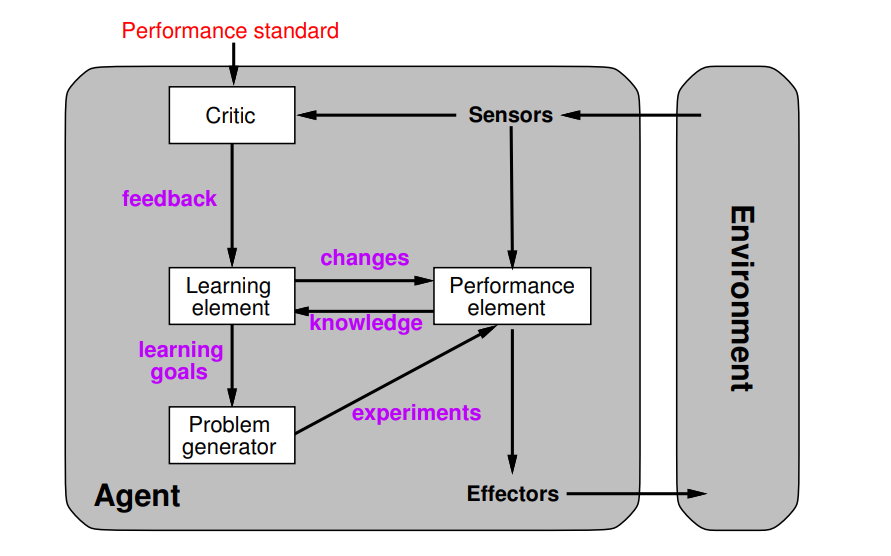
Performance element
Everything in between sensors and actuators abstracted away.
Takes in percepts and chooses actions.
Critic
Feedback on performance (based on a fixed performance standard).
Learning element LE
Change performance element for improvement.
Change "knowledge components" of agent (problem generator and performance element - independent of agents architecture).
Problem generator
suggest actions for new experiences to learn from - based on learning goals
Example: Taxi
Performance element knowledge about driving
Critic reactions of customer / other drivers / pedestrians / bikers / police
Learning element create rules - ie. not to turn steering wheel to quickly, break softly etc.
Problem generator try brakes on slippery road, push back with side (wing) mirror only
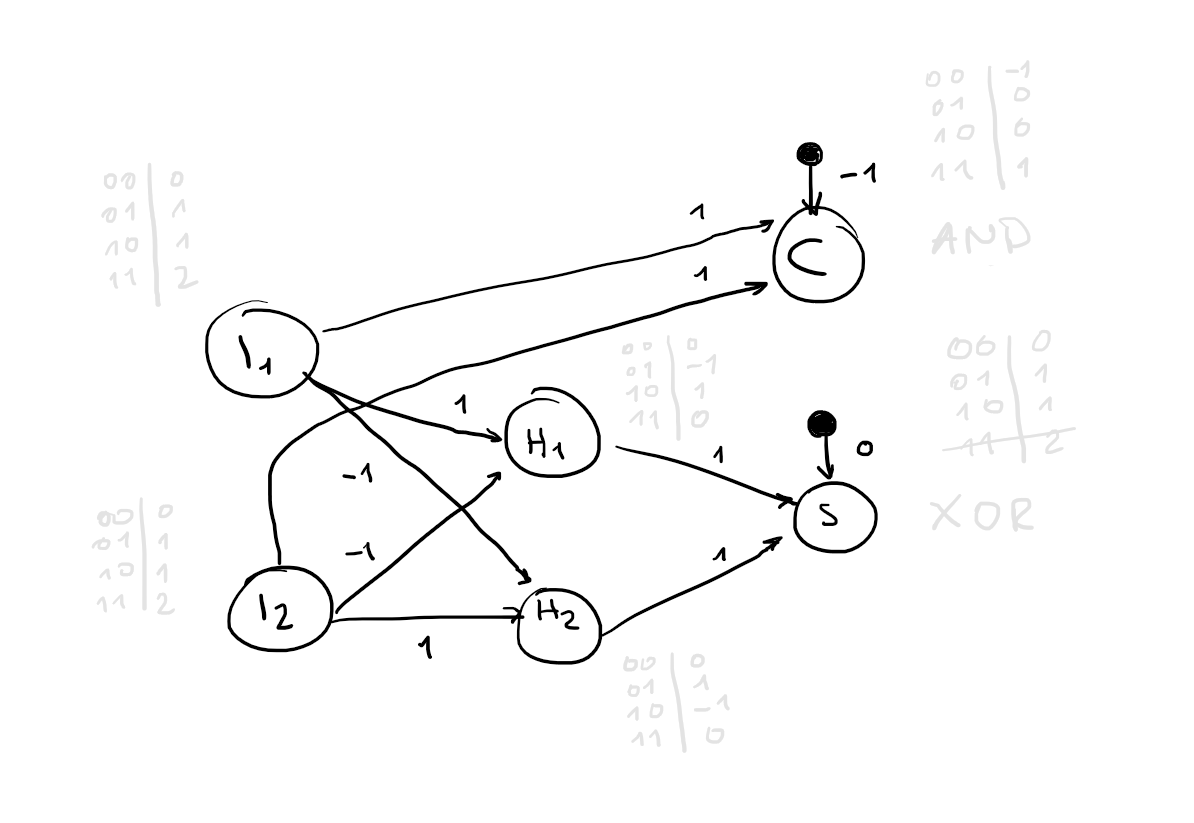
14. Construct a neural network that represents a half adder
- two inputs
-
two outputs
where
Version 1:
Activation function:
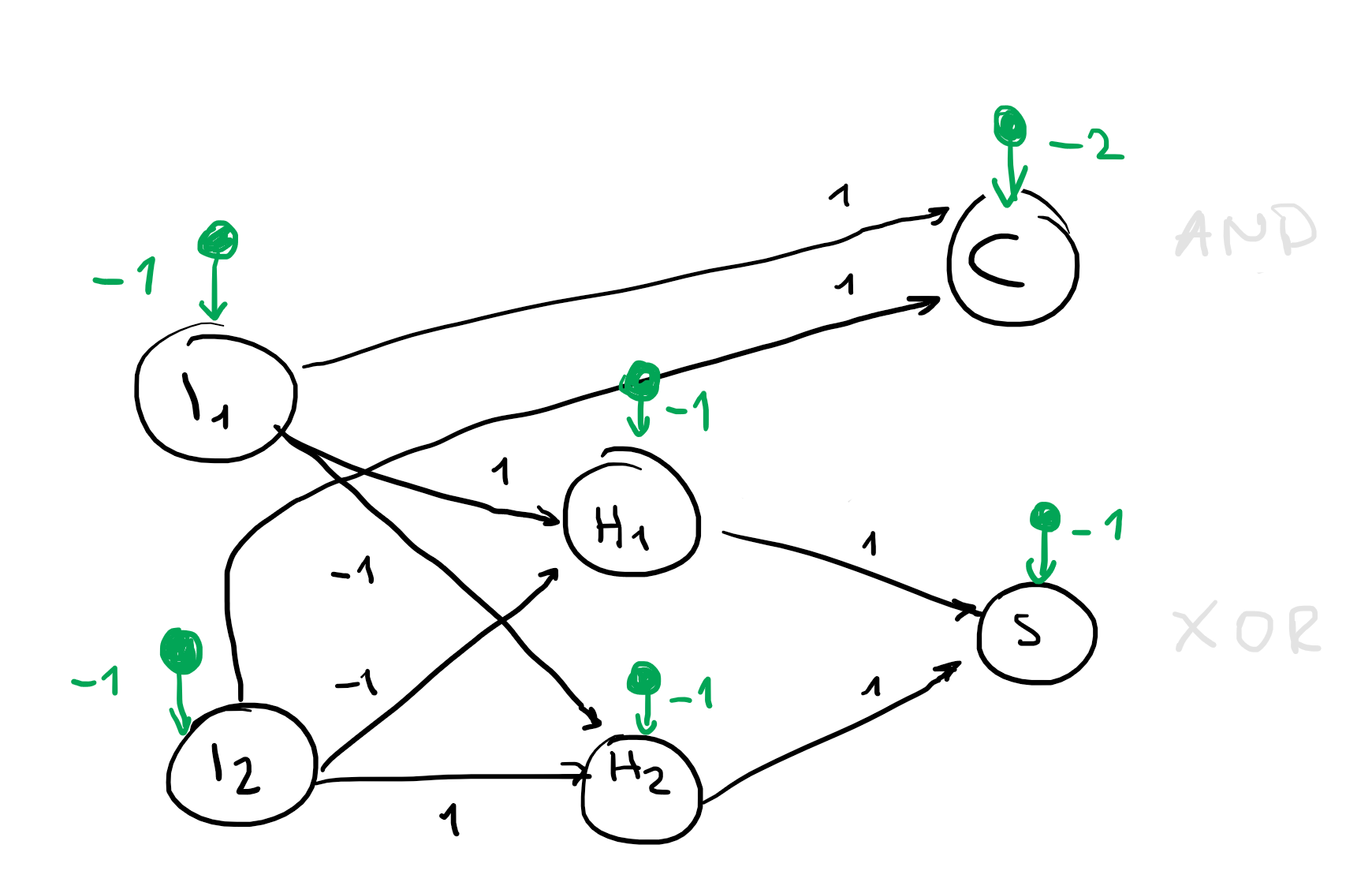
Version 2:
Activation function:
This could be done more elegantly but we just took the previous solution and subtracted from every nodes weight to be able to copy the previous solution.
15. Advantages and disadvantages of neural networks / learning by observation
Advantages and Disadvantages of Neural Networks
Pros
- Less need for determining relevant input factors
- Inherent parallelism
- Easier to develop than statistical methods
- Capability to learn and improve
- Useful for complex pattern recognition tasks, "unstructured" and "difficult" input (e.g., images)
- Fault tolerance
Cons
Challenges
- Interpretability
- Explainability
- Trustworthiness
- Robustness (adversarial examples)
- Combining symbolic and subsymbolic approaches