Exam on 2013-07-01
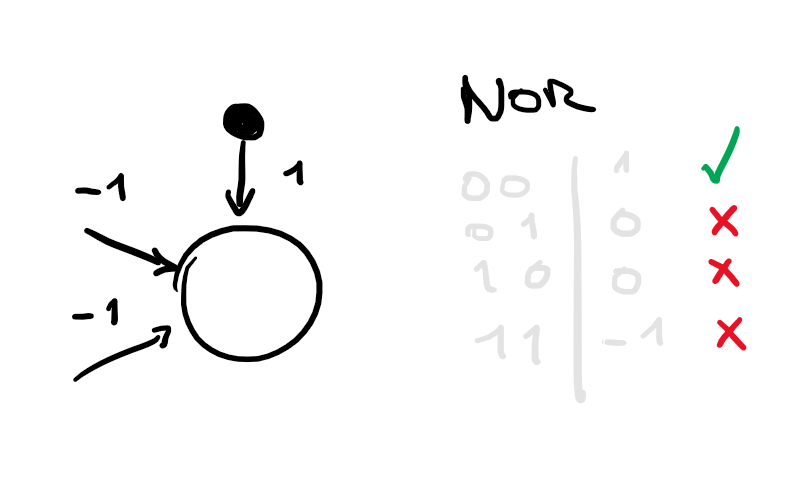
1. Construct a neural network for NOR
Activation function:
2. What is backwards propagation? How does it work for inner nodes?
Used for multilayer feed-forward neural networks:
We want to minimize the loss (= the sum of gradient losses for all output nodes).
Problem: dependency
We can not learn the weights the same way we did for the single layer network.
The multilayer network has a hidden layer and the output functions are nested functions that contain the nodes behind them.
The error for the hidden layers is not clear - we want to be able to push errors back.
output nodes
Each term in the final summation is computed as if the other outputs did not exist.
Same rule as in the single-layer perceptron.
the th component of the vector
hidden nodes: Back-propagation
We back propagate the errors from the output to the hidden layers.
3. What does the mathematical model of a neuron look like?
McCulloch and Pitts (1943)
The inputs stay the same, only the weights are changed.
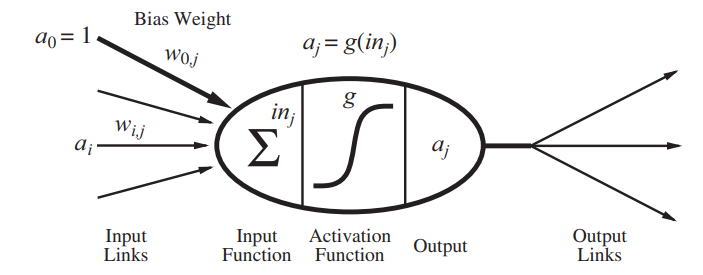
Each unit has a dummy input with the weight .
The unit 's output activation is
Where is an activation function :
perceptron hard threshhold
sigmoid perceptron logistic function
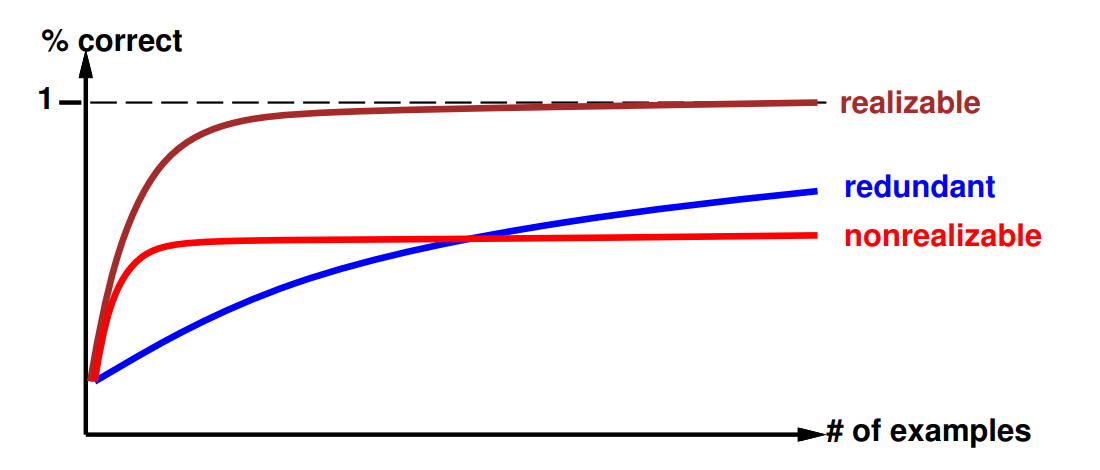
4. What is a learning curve? In which 2 cases is it not optimal?
How do we know that ? (Hume’s Problem of Induction)
Learning curve = % correct on test set when using
Learning curve depends on realizability of the target function.
Non-realizability can be due to
- missing attributes
- too restrictive hypothesis space (ie. linear function)
- redundant expressiveness (ie. loads of irrelevant attributes)
5. What is an admissible or consistent heuristic?
Admissibility
Optimistic, never overestimating, never negative.
goals: (follows from the above)
Consistency / Monotonicity
Every consistent heuristic is also admissible. Consistency is stricter than admissibility.
Implies that -value is non-decreasing on every path .
For every node and its successor :
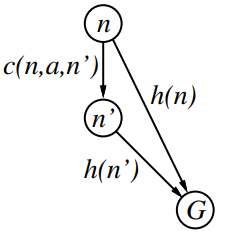
6. Prove the following:
If the heuristic is consistent and is the neighbour of , then
For every node and its successor :
This is a form of the general triangle inequality.
is then non-decreasing along every path:
(because of consistency)
7. From a set of admissible heuristics, which one is optimal for search?
For two admissible heuristics, we say dominates , if:
Then is better for search.
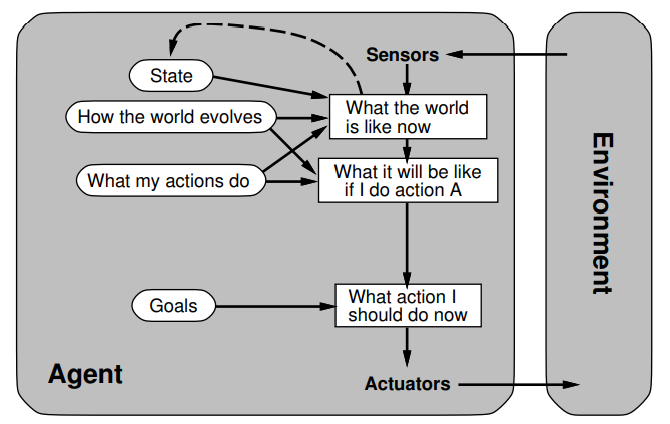
8. What are the components of a goal-based agent?
Goal-based agents
Add on: explicit goals , ability to plan into the future, model outcomes for predictions
- model the world , goals, actions and their effects explicitly
- more flexible, better maintainability
- Search and planning of actions to achieve a goal
9. Draw a CSP from a geographical map
Constraint graph
Can only be used for binary CSPs (only have binary constraints)
10. Define the following heuristics:
General-purpose methods for backtracking search: Since plain backtracking search is an uninformed algorithm, it is not effective for large problems - we need heuristics.
Variable ordering: fail first
- Minimum remaining (legal) values MRV
- degree heuristic - (used as a tie breaker), variable that occurs the most often in constraints
Value ordering: fail last
- least-constraining-value - a value that rules out the fewest choices for the neighbouring variables in the constraint graph.
11. Are nonlinear CSPs always decidable?
No they are undecidable.
Infinite Domain CSPs
no enumeration possible.
requires constraint language for linear constraints.
solved with linear programming in polynomial time (non-linear constraints are undecidable).
ie. construction job scheduling
Continuous Domains CSPs
Linear / Quadratic Programming Problems.
12. Does a CSP with variables and values in its domain have possible assignemnts?
Yes - this is because we are considering the commutativity of operatins and pick a single variable to assign for each tree level.
13. Construct a STRIPS action
A cyclist wants to move from A to B.
14. STRIPS vs. ADL
STRIPS: conjunctions in goals supported?
Yes - but only non-negative literals
ADL: Are non-occuring predicates wrong?
No - closed-world-assumption means unmentioned literals are false
But ADL supports the open-world-assumption: unmentioned literals are unknown
ADL: is the equiality symbol supported?
Yes - equality and types built in
15. What is the qualification problem?
qualification problem ... what are preconditions for actions?
The inability to capture everything in a set of logical rules
Deals with a correct conceptualisation of things (no answer).
Restrictions of ADL and STRIPS
- cant derive other effects from more complex ones
- classical planning systems do not attempt to address the qualification problem