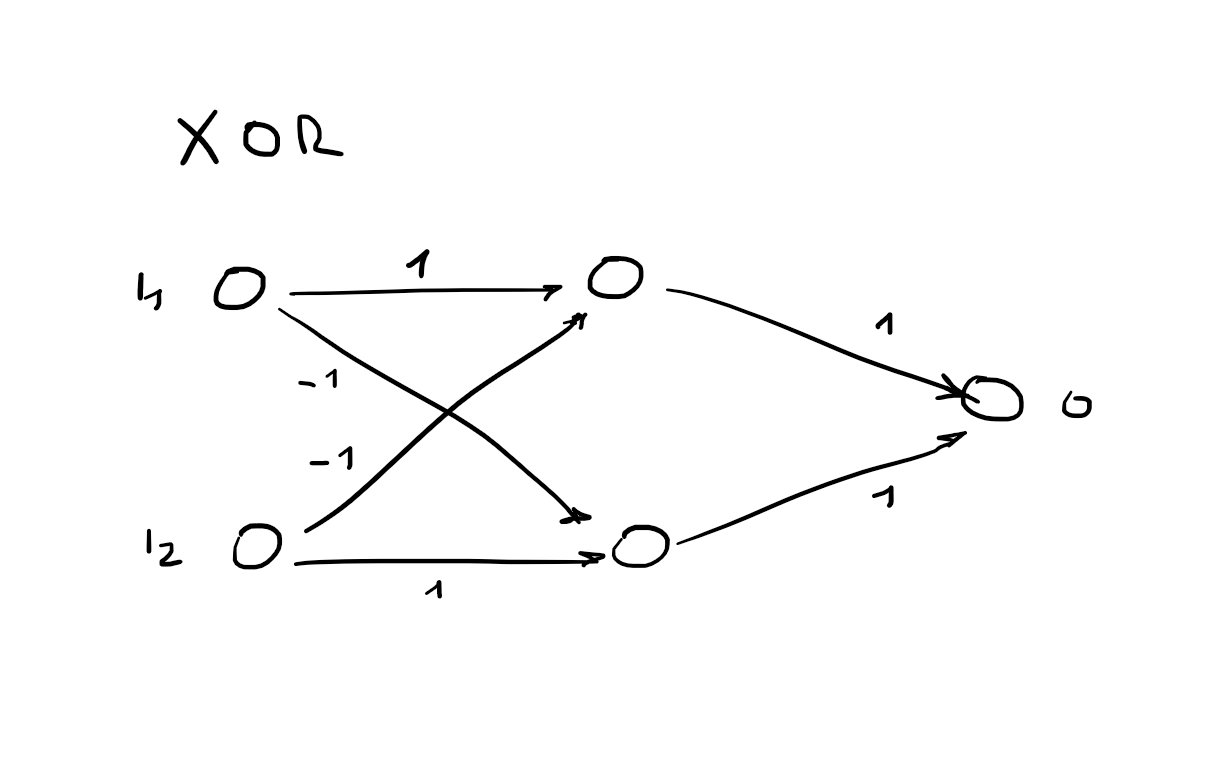
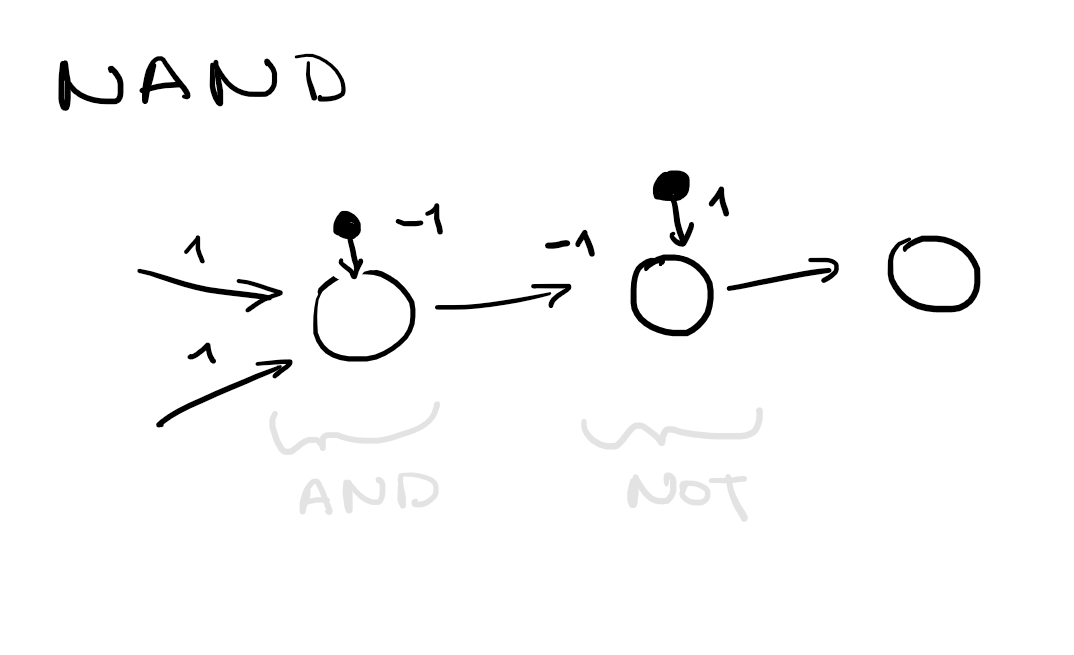
Exam on 2016-06-28
1. Construct a neural network
2 inputs
2 outputs: nand, xor
Activation function:
2. Explain the local beam search and mention its advantages / disadvantages
Idea keep states instead of just
Not the same as running searches in parallel: Searches that find good states recruit other searches to join them - choose top of all their successors
Problem often, all states end up on same local hill
Solution choose successors randomly, biased towards good ones
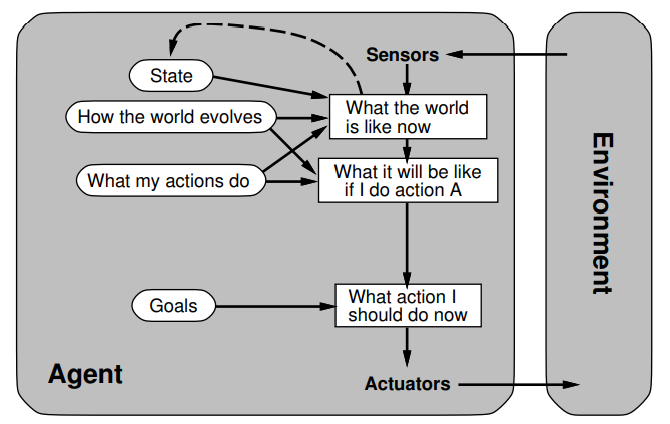
3. Describe the components of the goal-based agent
Add on: explicit goals , ability to plan into the future, model outcomes for predictions
- model the world , goals, actions and their effects explicitly
- more flexible, better maintainability
- Search and planning of actions to achieve a goal
4. Use the A* search
on a small graph
-
which nodes get expanded?
nodes where
-
what do the costs look like?
where heuristic must be admissible.
-
Is BFS a special case of A*?
No it isnt, BFS uses a queue but A* search uses a priority queue.
A* Search
Solves non-optimality and possibility of non-termination of greedy search.
Just like UCS - but for the priority queue.
where heuristic must be admissible.
completeness Yes - with finite nodes and , costs , step-costs
time complexity where is the effective branching factor with rel. error .
space complexity Exponential, keeps all nodes in memory
optimality of solution Yes
non admissible for tree-search is not optimal (proof)
start node
goal nodes
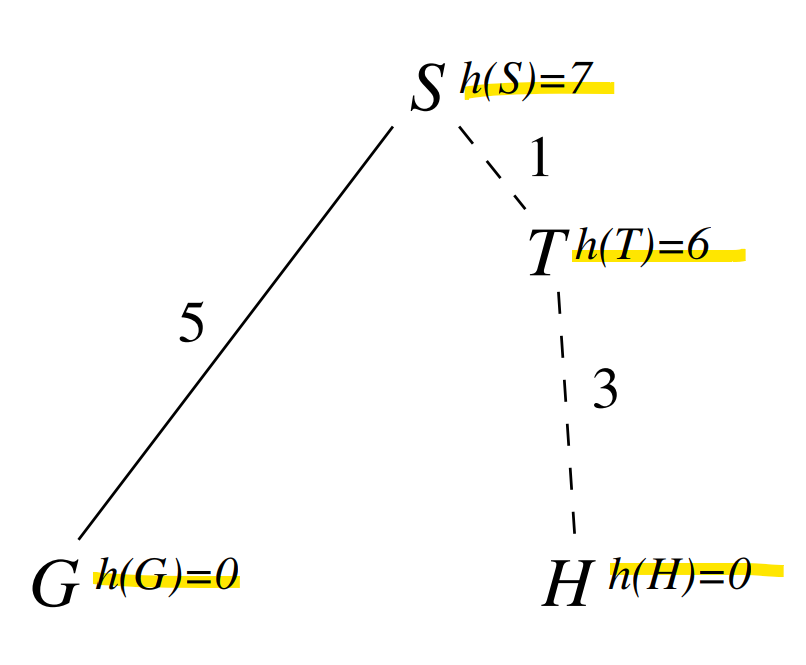
We immedeately expand non-optimal goal because although .
Then we check and terminate search.
admissible for tree-search is optimal (proof)
start node
optimal goal node
non goal node
unexpanded node on optimal path to
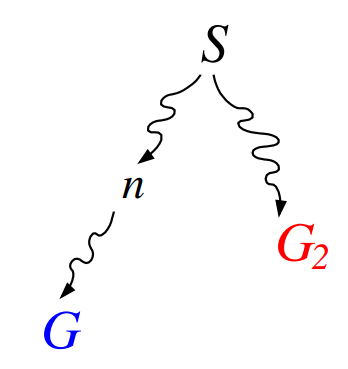
Since there are no unexpanded nodes to
Because is suboptimal
(cost to , and to goal)
Because the heuristic is admissible
Therefore A* will never select
consistent for graph search is optimal
If decreases during optimal path to goal it is discarded by graph-search.
(But in tree search it is not a problem since there is only a single path to the optimal goal).
Solutions to problem:
- consistency of (non decreasing on every path)
- additional book-keeping
optimal efficiency Yes
A* expands the fewest nodes possible - no other optimal algorithm can expand fewer nodes than A* because not expanding nodes with runs the risk of missing the optimal solution.
5. Multiple choice
What are the decisions of an rational agent based on?
Decisions based on evidence:
- percept history
- built-in knowledge of the environment - ie. fundamental knowledge laws like physics
BFS expands as many nodes as DFS
No - BFS uses a queue and DFS uses a stack.
BFS time complexity
Goal test at generation time:
Goal test at expansion time:
DFS time complexity - where maximum depth may be
IDS is optimal for limited tree depth
Yes- but also for unknown tree depths
it has solution optimality if step cost ≥ 1
In general IDS is very attractive and prefered when the search space is large and the depth of the solution is unknown.
It is usually only a little more expensive than BFS.
STRIPS only allows disjunctions in goals
No it doesnt - only conjunctions
ADL supports the notation for equaliy / inequality
Yes
6. Constraint graphs
3 coloring problem - geographical map - draw a constraint graph
7. Heuristics for backtracking search
Variable ordering: fail first
- Minimum remaining (legal) values MRV
- degree heuristic - (used as a tie breaker), variable that occurs the most often in constraints
Value ordering: fail last
- least-constraining-value - a value that rules out the fewest choices for the neighbouring variables in the constraint graph.
8. Explain the value of information - Can it be calculated without additional information?
Value of Information
Value of perfect information VPI(= expected value of information)
Can be used if we do not have additional information - we then just use averages
Lets say the exact evidence (= perfect information) of the random variable is currently unknown.
We define:
Best actionbefore learningunder all actions
Best actionafter learningunder all actions
Value of learning the exact evidence is the cost of discovering it for ourselves under by averaging over all possible values of .
9. Explain the estimated utility, maximum estimated utility
Utility function
desireability of state
Expected Utility (average utility value)
Its impicit that can follow from the current state .
Sum of: Probability of state occuring after action times its utility
Principle of maximum expected utility MEU
rational agent should choose the action that maximizes the agents expected utility
10. Construct a STRIPS action
Install a software
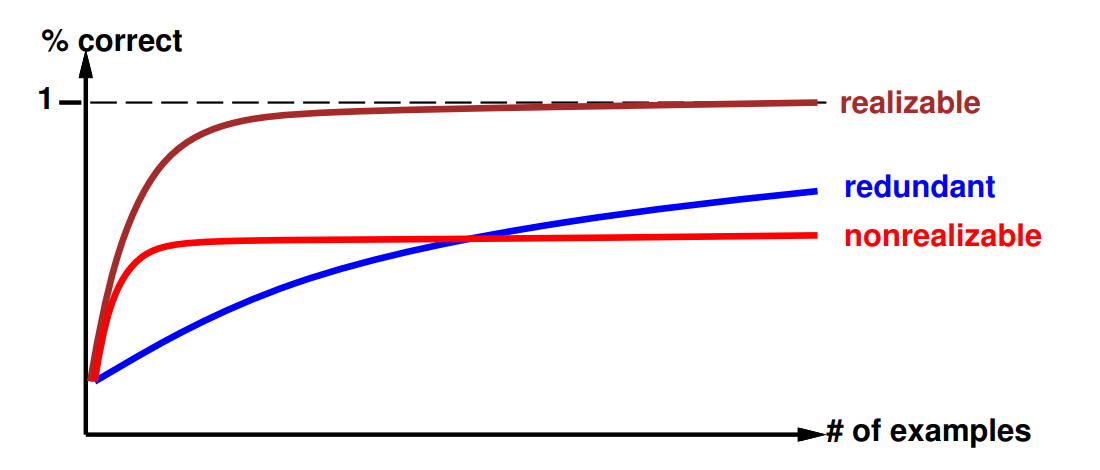
11. Explain the learning curve and mention reasons for its non-optimality
How do we know that ? (Hume’s Problem of Induction)
Learning curve = % correct on test set when using
Learning curve depends on realizability of the target function.
Non-realizability can be due to
- missing attributes
- too restrictive hypothesis space (e.g.,linear function)
- redundant expressiveness (e.g., loads of irrelevant attributes)