Exam on 2017-06-27
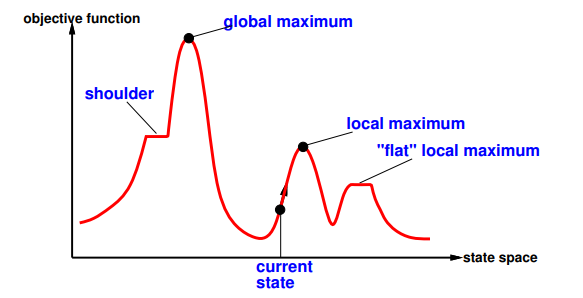
1. Explain the hill climbing algorithm
Also called "hill-climbing":
escaping shoulders
getting stuck in loop at local maximum
Solution: Random-restart hill climbing: restart after step limit overcomes local maxima
Pseudocode
function HILL-CLIMBING(problem) returns a state that is a local maximum inputs: problem // a problem local variables: current, // a node neighbor // a node current ← MAKE-NODE(INITIAL-STATE[problem]) loop do neighbor ← a highest-valued successor of current if VALUE[neighbor] ≤ VALUE[current] then return STATE[current] current ← neighbor
2. What is an order constraint and when does it lead to problems?
Action must be executed before action .
Must be free of contradictions/cycles :
else we have a problem.
3. What does it mean for a heuristic to be consistent?
What properties do the constants need to have if and are consistent?
definition of consistency
Every consistent heuristic is also admissible. Consistency is stricter than admissibility.
Implies that -value is non-decreasing on every path .
For every node and its successor :
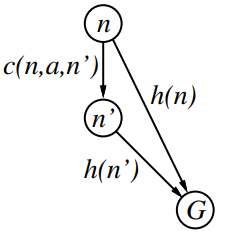
This is a form of the general triangle inequality.
is then non-decreasing along every path:
(because of consistency)
We want the following inequality to be true so that stays consistent as the sum of two consistent heuristics with weights :
Then is consistent with any .
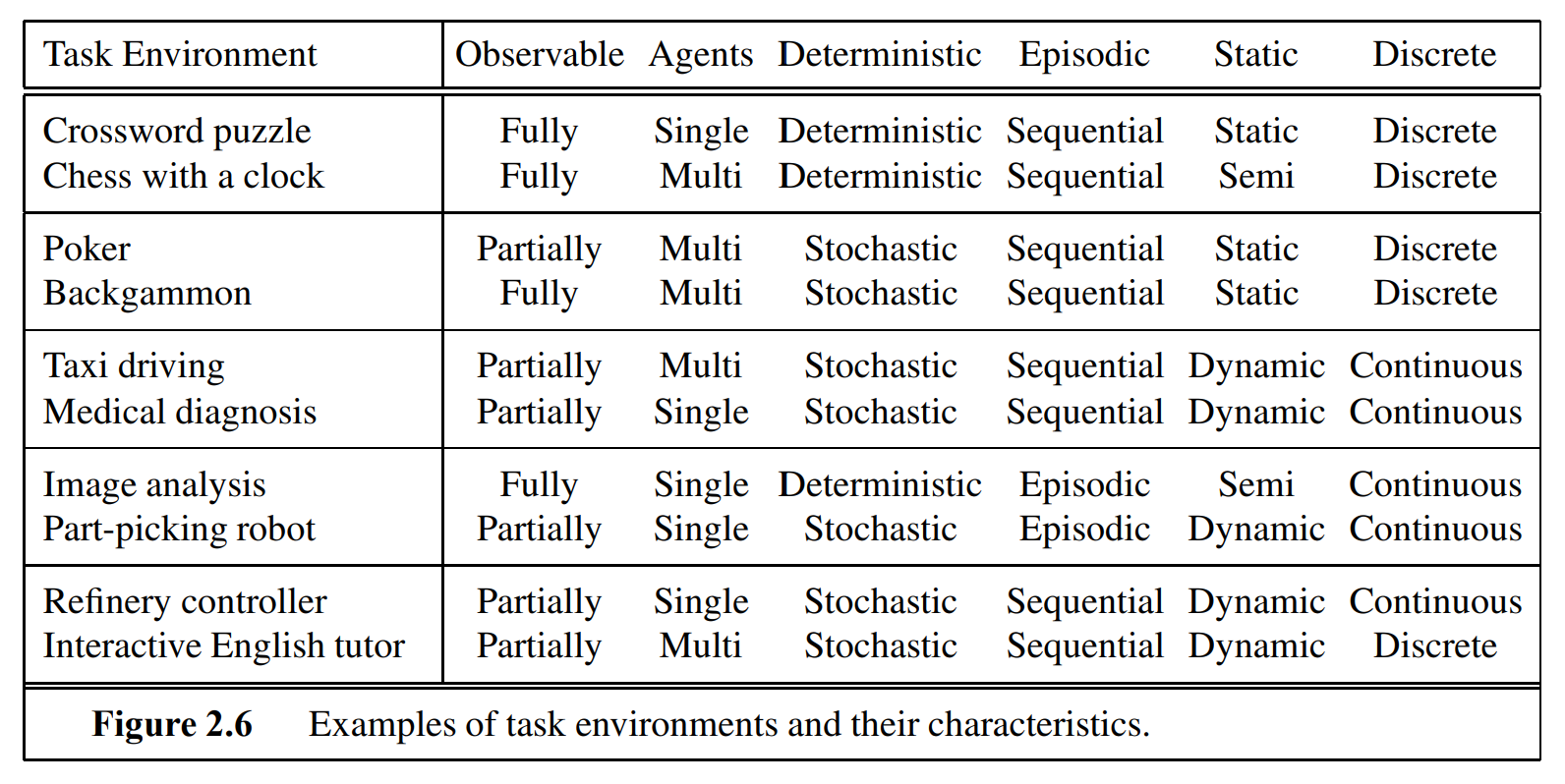
4. Describe 4 different types of environments that agents can be situated in.
fully observable vs. partly observable
whether sensors can detect all relevant properties
single-agent vs. multi-agent
single agent, or multiple with cooperation, competition
deterministic vs. non deterministic
whether the next state can be determined by current state + the performed action or is fully independent and can't be foreseen (multiple possible following states).
stochastic
whether we know the probabilities of occurences
episodic vs. sequential
Episodic: the choice of action only depends on the current episode - percept history divided into independent episodes.
Sequential: storing entire history (accessing memories lowers performance)
static vs. dynamic vs. semi-dynamic
Static: world does not change during the reasoning / processing time of the agent (waits for agents response)
Semi-dynamic: environment is static, but performance score decreases while processing time.
discrete vs. continuous
property values of the world
known vs. unknown
state of knowledge about the "laws of physics" of the environment
Examples
5. Perceptron learning rule
- Inputs
- Output
- Bias
- Learning rate
- Identity function
The perceptron learning rule:
We need the derivative of the identity function :
Therefore
6. CSP Problem
4 variables with different domains
...
with domain
with domain
....
5 constraints
Draw a constraint graph.
How would you pick the next variable / value with <heuristic name> if we assign the value to ?
7. Construct a STRIPS action
We want to transfer a file between 2 harddrives.
is on
is a file
is a harddrive
is empty
Preconditions:
- contains file
- is empty
- both are harddrives
Effect:
- is not empty anyymore
- both contain the data
8. Formal description of a search problem
Real World → Search problem → Search Algorithm
We define states, actions, solutions (= selecting a state space) through abstraction.
Then we turn states into nodes for the search algorithm.
Solution
A solution is a sequence of actions leading from the initial state to a goal state.
- Initial state
- Successor function
- Goal test
- path cost (additive)
9. Ramification problem, qualification problem - describe and give an example
Reasoning about the results of actions
frame problem ... what are things that stay unchanged after action?
would require a lot of axioms to describe.
ramification problem ... what are the implicit effects?
ie.: passengers of a car move with it
qualification problem ... what are preconditions for actions?
deals with a correct conceptualisation of things (no answer).
ie.: finding the right formalization of a human conversation
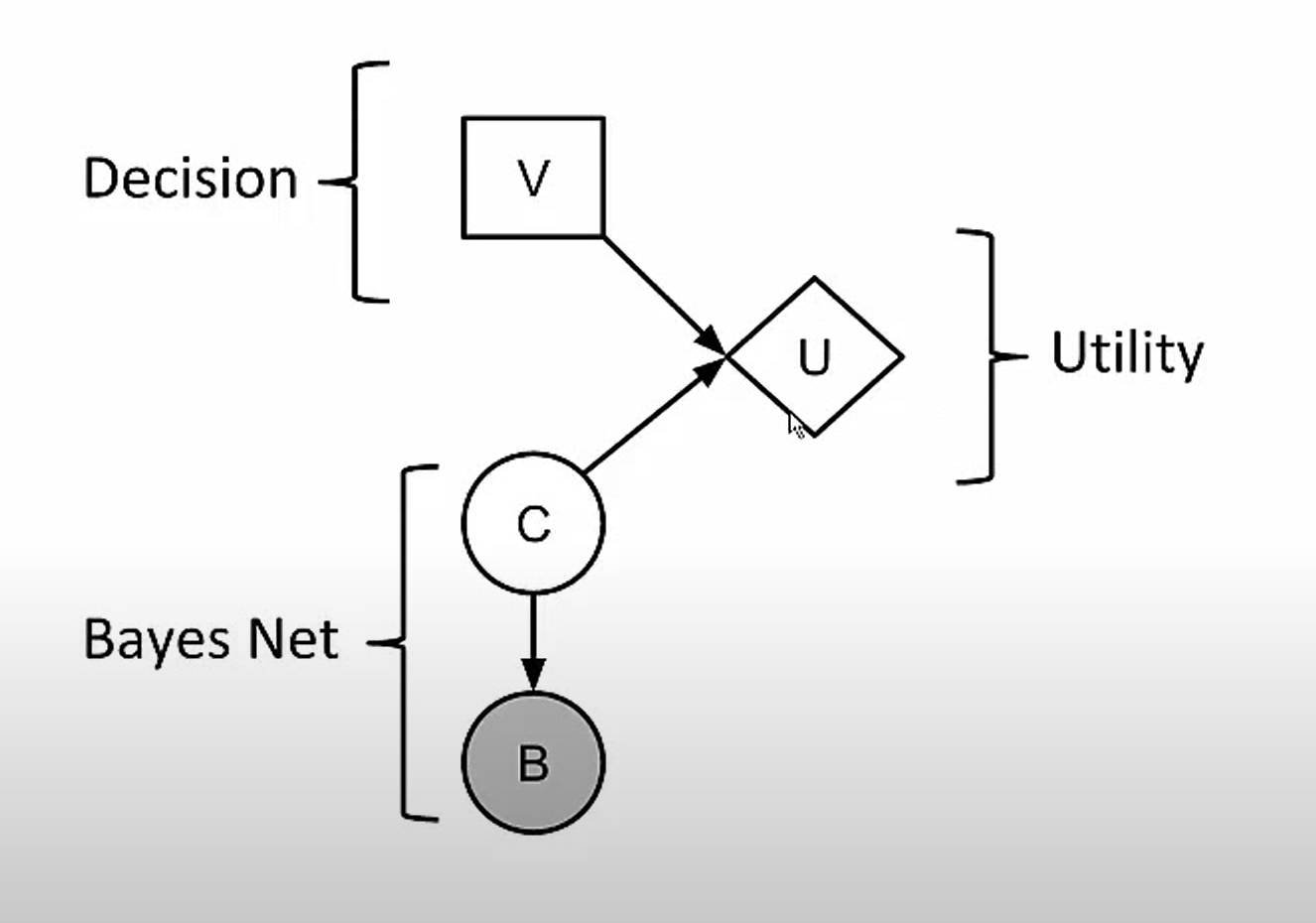
10. Decision Network, define node types
<Example containing something about the weather>
= influence diagrams.
General framework for rational decisions - return the action with highest utility.
Decision networks are an extension of Bayesian networks.
Presents:
- current state
- possible actions
- resulting state from actions
- utility of each state
Node types:
- Chance nodes (ovals)
Random variables, uncertainty - Bayes Network
- Decision nodes (rectangles)
Decision maker has choice of action
- Utility nodes (diamonds)
Utility function
11. Why is entropy relevant for decision trees? How is defined?
Information gain measured with entropy
Entropy measures uncertainty of the occurence of a random variable in [shannon] or [bit].
Entropy of a random variable with values each with probability is defined as:
Entropy is at its maximum when all outcomes are equally likely.
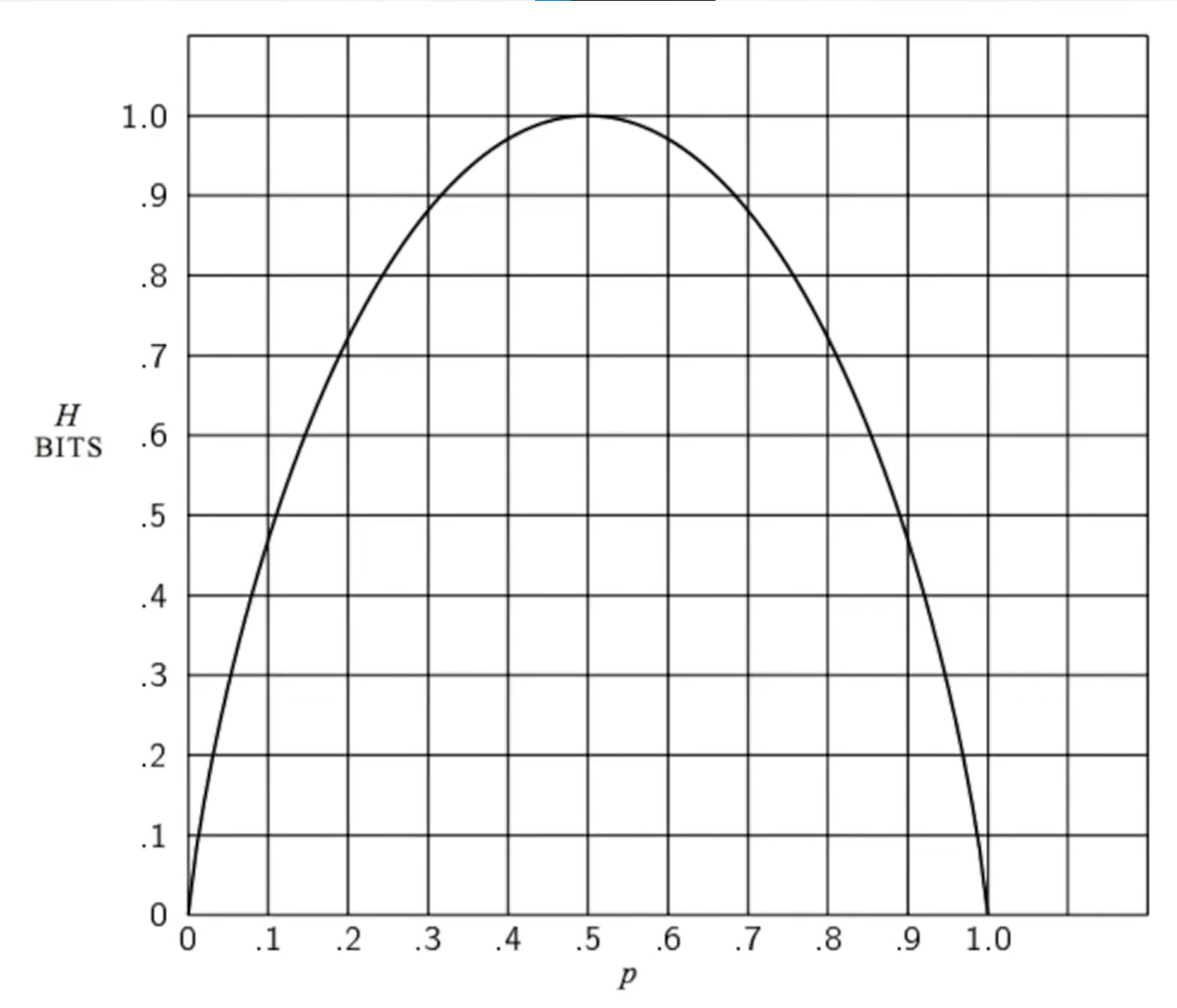
Entropy of a boolean random variable
Boolean random variable : Variable is true with probability and false with .
Same formula as above.
12. Multiple Choice part
Does BFS expand as least as often as it has nodes?
This depends on whether we test our goals on generation or on expansion.
Goal test at generation time:
Goal test at expansion time:
Can BFS be solved with a special case of A*?
No because BFS does not use a priority queue while A* does so.
Is local beam search a modification of the generic algorithm with cross-over?
No - Genetic algorithms GA is a modification of local beam search.
It uses Stochastic local beam search + successors from pairs of states.
Does STRIPS support the notation for equality?
No it doesn't - ADL does.
Does the POP algorithm only produce consistent plans?
Yes - because only consistent plans are generated the goal test is checking if any preconditions are open. If the goal is not reached it adds successor states.