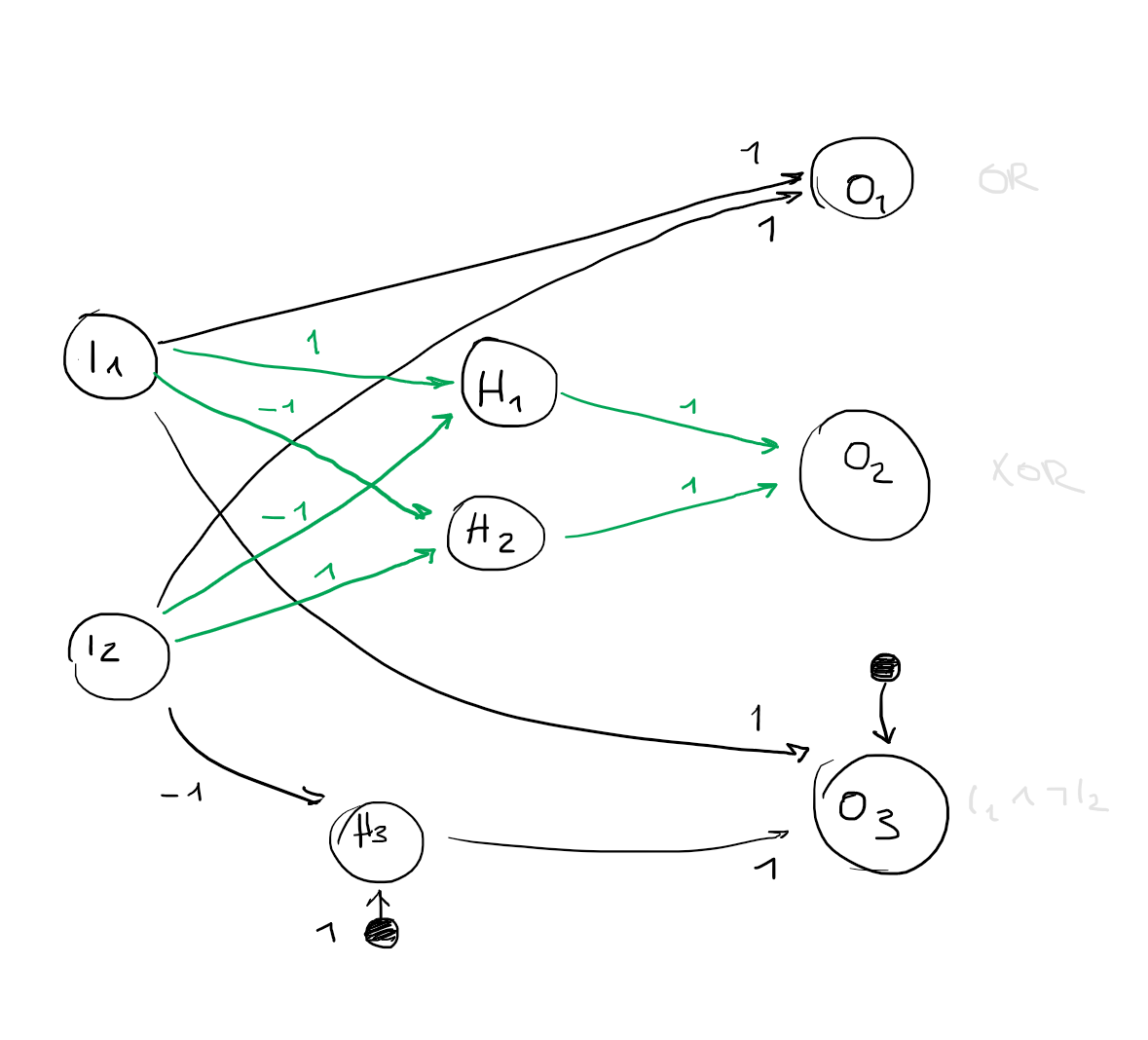
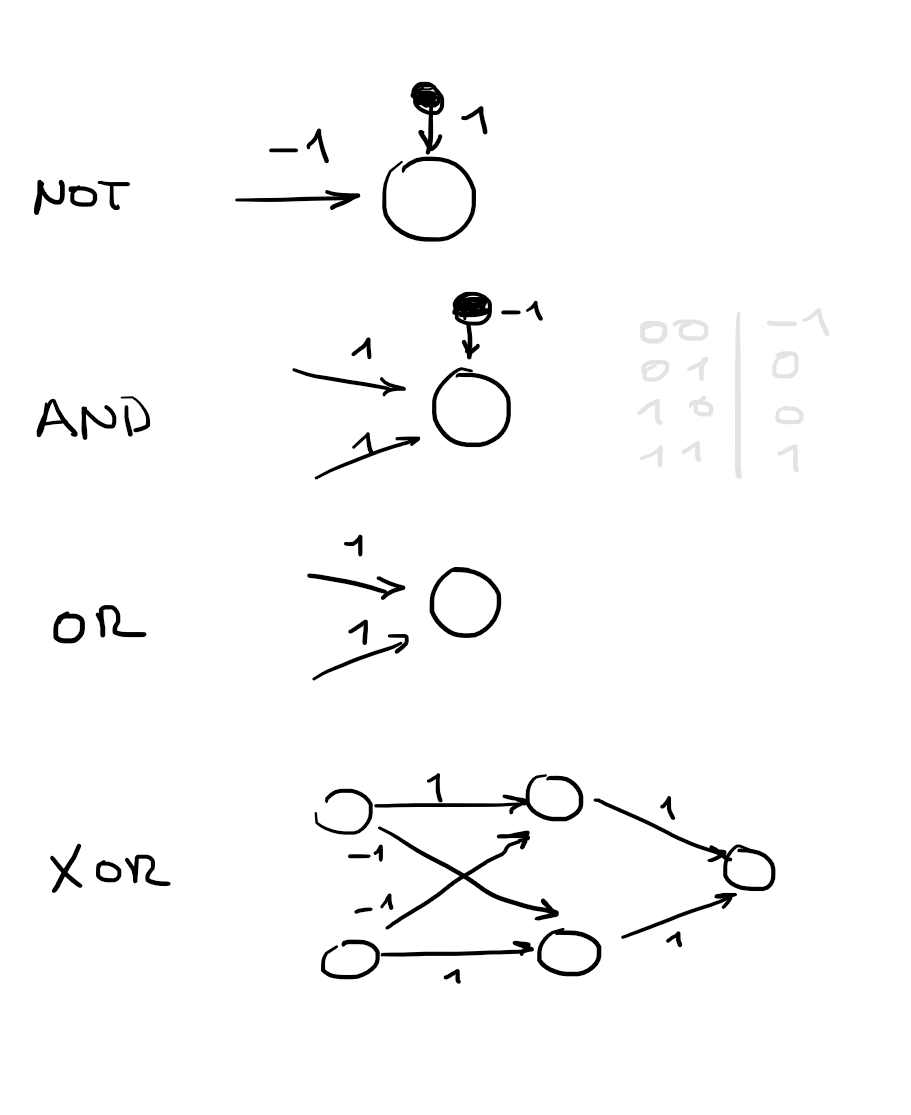
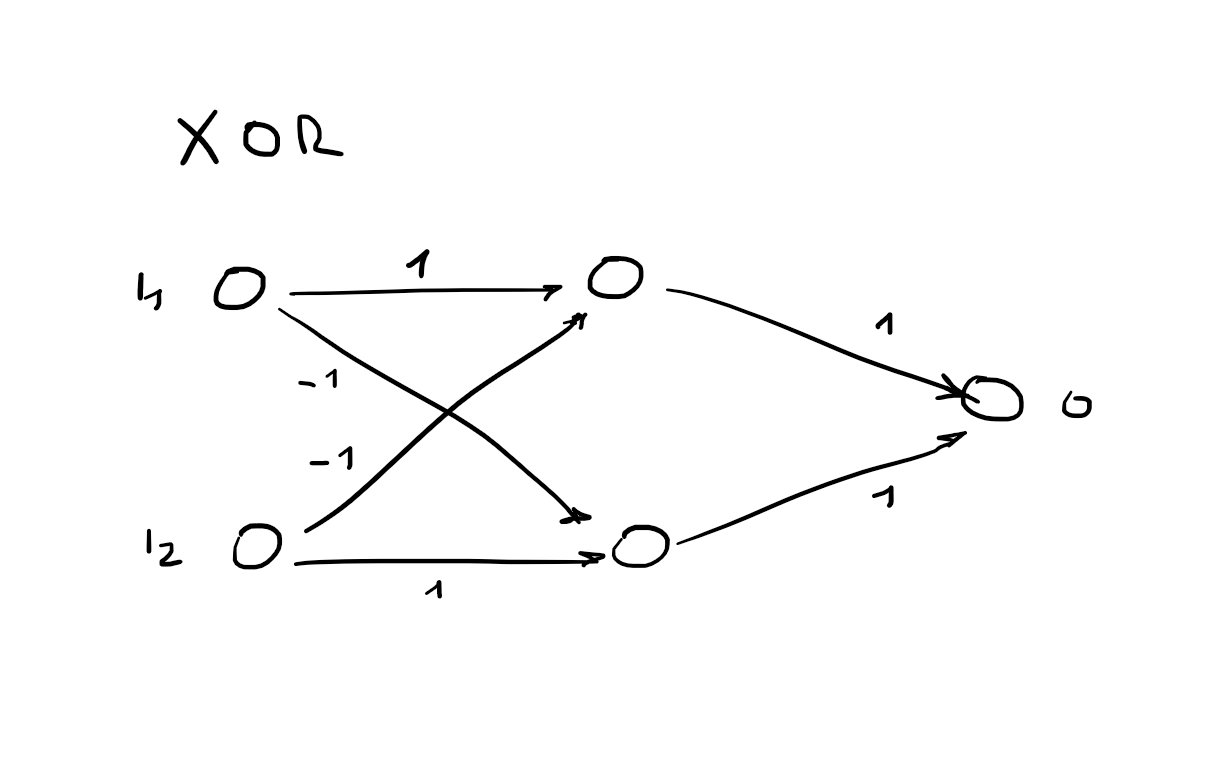
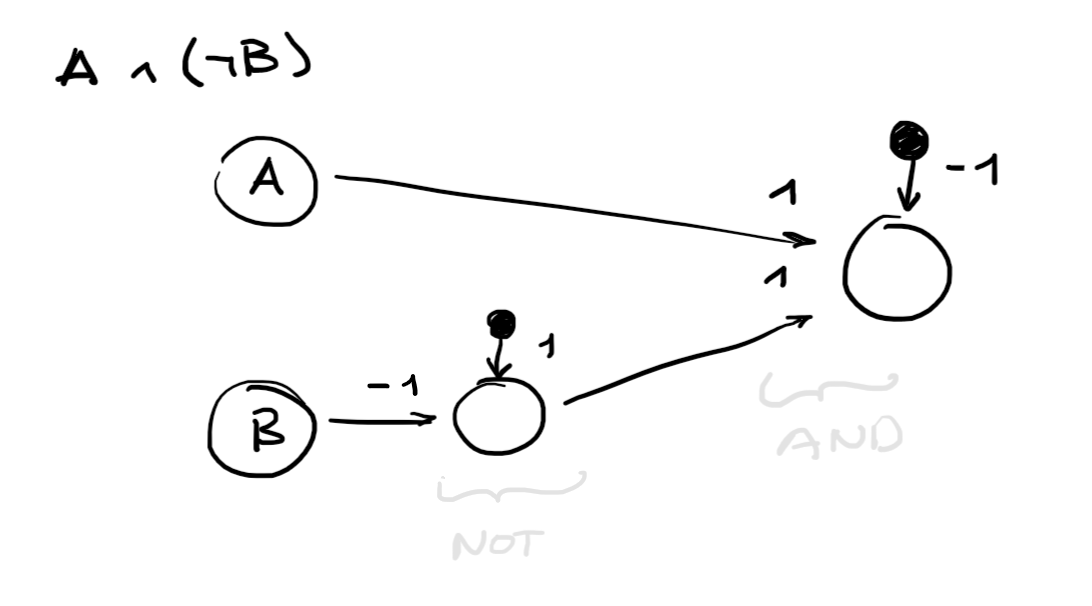
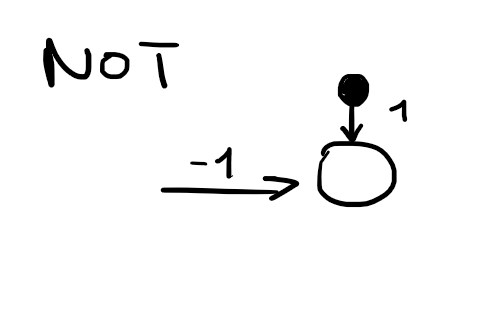I
1
0011
I
2
0101
O
1
0111
O
2
0110
O
3
0010
Activation function:
g(x)={10 if x≥1, otherwise
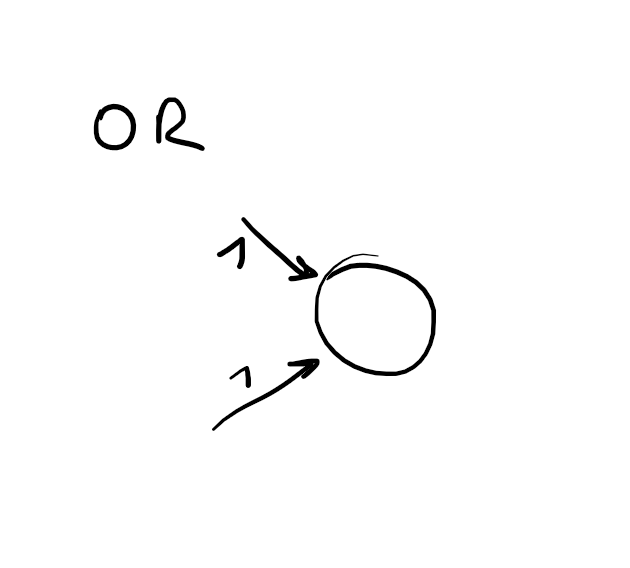
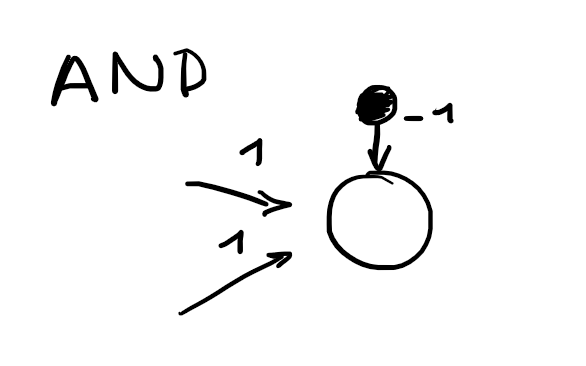
Boolean functions explained for
g(x)
in depth
b) Describe the properties of DFIDS and DFS
Depth-first search DFS
Fronier as stack.
Much faster than BFS if solutions are dense.
completeness
No - only with explored set and in finite spaces.
time complexityO(bm)
- Terrible results if
m≥d
.
space complexityO(bm)
- backtracking variant: store one successor node at a time
solution optimality
No
Depth-limited search DLS
DFS limited with
ℓ
- returns a
cutoff
subtree/subgraph.
Pseudocode
function DEPTH-LIMITED-SEARCH(problem, limit) returns a solution, or failure/cutoff
return RECURSIVE-DLS(MAKE-NODE(problem.INITIAL-STATE), problem, limit)function RECURSIVE-DLS(node, problem, limit) returns a solution, or failure/cutoff
if problem.GOAL-TEST(node.STATE) then return SOLUTION(node)
else if limit = 0 then return cutoff
else
cutoff occurred? ← false
for each action in problem.ACTIONS(node.STATE) do
child ← CHILD-NODE(problem, node, action)
result ← RECURSIVE-DLS(child, problem, limit − 1)
if result = cutoff then cutoff occurred? ← true
else if result != failure then return result
if cutoff occurred? then return cutoff else return failure
completeness
No - May not terminate (even for finite search space)
time complexityO(bℓ)
space complexityO(bℓ)
solution optimality
No
Iterative deepening search IDS
Iteratively increasing
ℓ
in DLS to gain completeness.
Pseudocode
function ITERATIVE-DEEPENING-SEARCH(problem) returns a solution, or failure
for depth = 0 to ∞ do
result ← DEPTH-LIMITED-SEARCH(problem, depth)
if result 6= cutoff then return result
completeness
Yes
time complexityO(bd)
in depth
Only
b−1b
times more inefficient than BFS therefore
O(bd)
The total number of nodes generated in the worst case is:
(d)b+(d−1)b+...+(1)b=O(db)
Most of the nodes are in the bottom level, so it does not matter much that the upper levels are generated multiple times. In
IDS, the nodes on the bottom level (depth
d
) are generated once, those on the next-to-bottom level are generated twice, and so on, up to the children of the root,
which are generated
d
times.
Therefore asymptotically the same as DFS.
solution optimality
yes, if step cost ≥ 1
c) Name the 4 components of an agents task description.
PEAS: Task description of Agents.
ie. Autonomous taxi
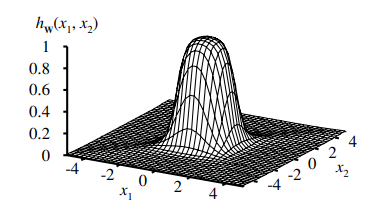
No hidden layers: Always represents a linear separator in the input space - therefore can not represent the XOR function.
Multilayer feed-forward neural networks
With a single, sufficiently large hidden layer (2 layers in total), it is possible to represent any continuous function of the inputs with
arbitrary accuracy.
in depth
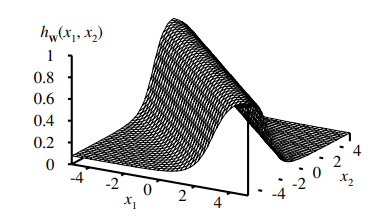
Above we see a nested non-linear function as the solution to the output.
With the sigmoid function as
g
and a hidden layer, each output unit computes a soft-thresholded linear combination of several sigmoid functions.
For example, by adding two opposite-facing soft threshold functions and thresholding the result, we can obtain a "ridge"
function.
Combining two such ridges at right angles to each other (i.e., combining the outputs from four hidden units), we obtain a
"bump".
With more hidden units, we can produce more bumps of different sizes in more places.
With two hidden layers, even discontinuous functions can be represented.
f) Prove or contradict the following
h(n)
is consistent for all consistent heuristics
h1,h2
if:
h(n):=max{h1(n),h2(n)}
Consistency
For all neighbours
n′
of
n
:
h(n)≤c(n,a,n′)+h(n′)
This also implies admissibility and that
f
is non decreasing along every path
We pick the neighbour with the highest value until there are no higher values left - then we can't climb anymore. Then we return the highest
found state.
We can get stuck in local maxima but can escape shoulders.
Part 2)
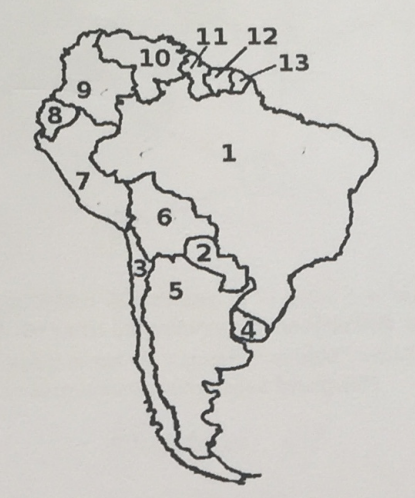
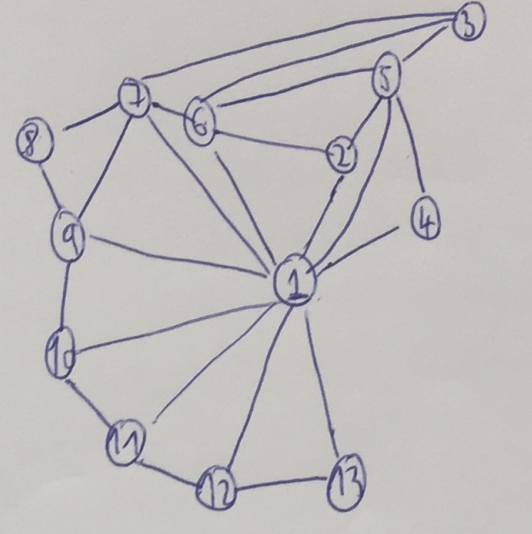
a) Three-colorability problem CSP → Constriant Graph
Variables
{1,2,3,4,5,6,7,8,9,10,11,12,13}
Domains
Di={ red, green, blue },1≤i≤3
Constraints Adjacent states shall have different colors.
Because we only have binary constrains we can construct the graph as follows:
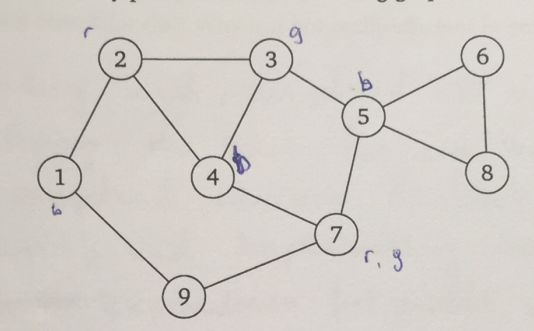
b) Three-colorability problem
Same variables, domains, constraints as before.
Explaination
Different general-purpose methods help improving the performance of the backtracking search.
Variable ordering: fail first
Choose variable with
Minimum remaining (legal) values MRV
.
Alternatively (as a tie breaker) choose variable that occurs the most often in constraints -
degree heuristic
.
Value ordering: fail last
least-constraining-value
- Choose value that has the least constraints in child nodes
Least-constraining-value heuristic
Partial assignment:
3
= green,
4
= blue — which value would
5
get?
The value
blue
would be the least constraining for all neighbours.