at generation → better performance, only storing necessary nodes
Tree-Search algorithm TS
Offline, simulated exploration of state space.
The
frontier / open list
set contains all child nodes that can be expanded.
Pseudocode
function TREE-SEARCH(problem) returns a solution, or failure
initialize the frontier using the initial state of problem
loop do
if the frontier is empty then return failure
choose a leaf node and remove it from the frontier
if the node contains a goal state then return the corresponding solution
expand the chosen node, adding the resulting nodes to the frontier
Graph-Search algorithm GS
Same as tree search but also stores all visited nodes in an
explored set / closed list
of already considered states to prevent endless looping.
Can be exponentially more efficient than tree search.
Pseudocode
function GRAPH-SEARCH(problem) returns a solution, or failure
initialize the frontier using the initial state of problem
initialize the explored set to be empty
loop do
if the frontier is empty then return failure
choose a leaf node and remove it from the frontier
if the node contains a goal state then return the corresponding solution
add the node to the explored set
expand the chosen node, adding the resulting nodes to the frontier
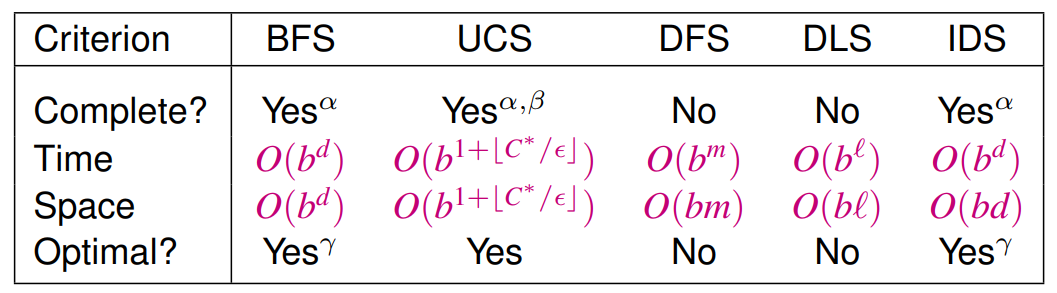
Uninformed search algorithms
completeness
always finds existing solutions
space complexity
max number of nodes in memory
time complexity
max number of nodes generated/expanded.
solution optimality
always finds the least-cost solution
b
maximum branching factor of search tree
d
depth of shallowest solution
m
maximum depth (may be
∞
)
ℓ
depth limit
Overview
under the conditions:
α-
if
b
is finite
β-
if step costs
≥ε
for positive
ε
γ-
optimal with identical step costs
1) Breadth-first search BFS
Frontier as queue.
The space and time complexity is too high.
Here the goal test is done at generation time.
Pseudocode
function BREADTH-FIRST-SEARCH(problem) returns a solution, or failure
node ← a node with STATE = problem.INITIAL-STATE, PATH-COST = 0
if problem.GOAL-TEST(node.STATE) then return SOLUTION(node)
frontier ← a FIFO queue with node as the only element
explored ← an empty set
loop do
if EMPTY?(frontier) then return failure
node ← POP(frontier)
add node.STATE to explored
for each action in problem.ACTIONS(node.STATE) do
child ← CHILD-NODE(problem, node, action)
if child.STATE is not in explored or frontier then
if problem.GOAL-TEST(child.STATE) then return SOLUTION(child)
frontier ← INSERT(child,frontier)
completeness
yes, if
b
is finite
time complexityO(bd)
in depth
If solution is at depth
d
and max branching is
b
:
Goal test at generation time:
1+b+b2+b3+...+bd=O(bd)
Goal test at expansion time:
1+b+b2+b3+...+bd+bd+1=O(bd+1)
space complexityO(bd)
solution optimality
yes, if step costs ≥ 1
2) Uniform-cost search UCS
Fronier as priority queue ordered by costs.
Here the goal test is done at expansion time.
Pseudocode
function UNIFORM-COST-SEARCH(problem) returns a solution, or failure
node ← a node with STATE = problem.INITIAL-STATE, PATH-COST = 0
frontier ← a priority queue ordered by PATH-COST, with node as the only element
explored ← an empty set
loop do
if EMPTY?(frontier) then return failure
node ← POP(frontier)
if problem.GOAL-TEST(node.STATE) then return SOLUTION(node)
add node.STATE to explored
for each action in problem.ACTIONS(node.STATE) do
child ← CHILD-NODE(problem, node, action)
if child.STATE is not in explored or frontier then
frontier ← INSERT(child,frontier)
else if child.STATE is in frontier with higher PATH-COST then
replace that frontier node with child
completeness
Yes, if step-cost
≥ε
and
b
is finite
time complexityO(b⌊C∗/ε⌋+1)
in depth
if all step-costs
≥ε
and
C∗
is the cost of the optimal solution
then
d=⌊ε
C
∗⌋+1
and therefore
O(b⌊
C
∗/ε⌋+1)
if goal-tested at expansion, not generation - therefore
bd+1
.
space complexityO(b⌊C∗/ε⌋+1)
solution optimality
Yes, if goal-tested at expansion.
3) Depth-first search DFS
Fronier as stack.
Much faster than BFS if solutions are dense.
Backtracking variant: store one successor node at a time - generate child node with
Δ
change.
completeness
No - only complete with explored-set (graph search) and in finite spaces.
time complexityO(bm)
- Terrible results if
m≥d
.
space complexityO(bm)
solution optimality
No
4) Depth-limited search DLS
DFS limited with
ℓ
- returns a
cutoff
subtree/subgraph.
Pseudocode
function DEPTH-LIMITED-SEARCH(problem, limit) returns a solution, or failure/cutoff
return RECURSIVE-DLS(MAKE-NODE(problem.INITIAL-STATE), problem, limit)function RECURSIVE-DLS(node, problem, limit) returns a solution, or failure/cutoff
if problem.GOAL-TEST(node.STATE) then return SOLUTION(node)
else if limit = 0 then return cutoff
else
cutoff occurred? ← false
for each action in problem.ACTIONS(node.STATE) do
child ← CHILD-NODE(problem, node, action)
result ← RECURSIVE-DLS(child, problem, limit − 1)
if result = cutoff then cutoff occurred? ← true
else if result != failure then return result
if cutoff occurred? then return cutoff else return failure
completeness
No - May not terminate (even for finite search space)
time complexityO(bℓ)
space complexityO(bℓ)
solution optimality
No
5) Iterative deepening search IDS
Iteratively increasing
ℓ
in DLS to gain completeness.
Pseudocode
function ITERATIVE-DEEPENING-SEARCH(problem) returns a solution, or failure
for depth = 0 to ∞ do
result ← DEPTH-LIMITED-SEARCH(problem, depth)
if result 6= cutoff then return result
completeness
Yes
time complexityO(bd)
in depth
Only
b−1b
times more inefficient than BFS therefore
O(bd)
The total number of nodes generated in the worst case is:
(d)b+(d−1)b+...+(1)b=O(db)
Most of the nodes are in the bottom level, so it does not matter much that the upper levels are generated multiple times. In
IDS, the nodes on the bottom level (depth
d
) are generated once, those on the next-to-bottom level are generated twice, and so on, up to the children of the root,
which are generated
d
times.
Therefore asymptotically the same as DFS.
solution optimality
Yes, if step cost ≥ 1
In general IDS is very attractive and prefered when the search space is large and the depth of the solution is unknown.
It is usually only a little more expensive than BFS.