File Management
Motivation
Früher Computer ausschließlich zum Rechnen, haben keine Dokumente gespeichert.
Heute auch File-System auch Dokumentenspeicher.
Sekundärspeicher früher zB als Band-Speicher oder Platten-Speicher.
Externer Speicher wird von File-System genutzt da Arbeitsspeicher
begrenzten Speicher-Platz hat→ Auslagern wenn voll
Daten bei Stromausfall oder Ende der Prozess-Lebensdauer weg sind
Sekundärer Speicher billiger ist
Man Daten nicht immer mitnehmen muss wenn man einen anderen Rechner verwendet
File
Menge an Datenblöcke im Speicher.
Mehrere Prozesse können gleichzeitig darauf zugreifen
Lebensdauer nicht durch Termination von Prozessen abhängig
____________
Sichten
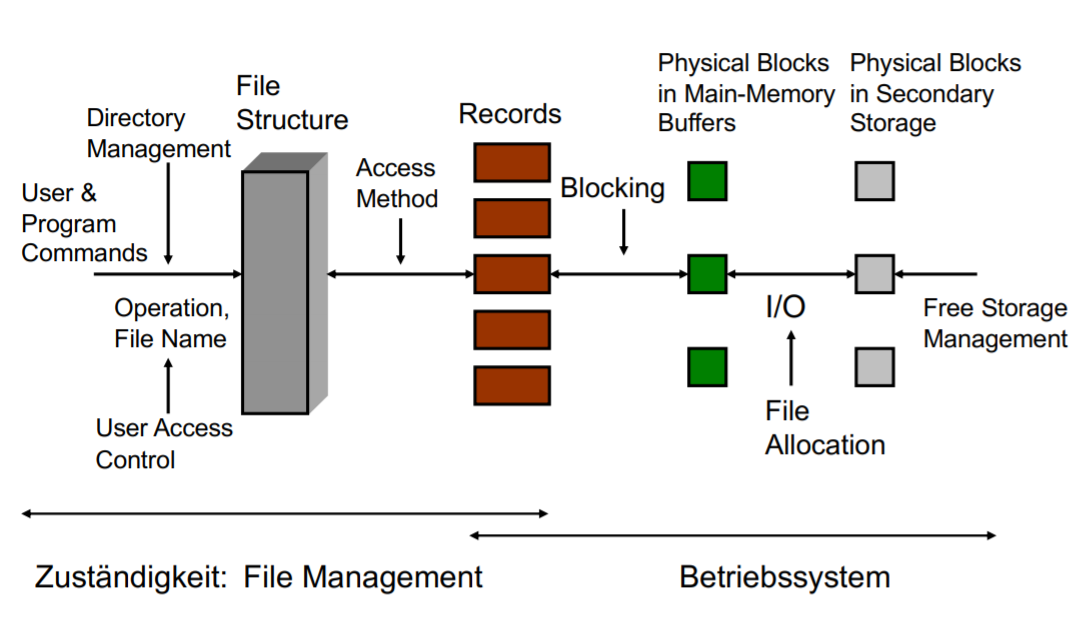
User Sicht: File Management
Aus der sicht des Users / Programm Commands sieht man die logische Struktur. (Nicht die dahinterliegende Implementierung)
Ziele
Kurze Zugriffszeit
Leichte Aktualisierbarkeit / Veränderbarkeit
Geringer Platzverbrauch
Gute Wartbarkeit
Zuverlässigkeit
Zugriffsrechte gewahren, Daten schützen
Elemente der Datei Organisation / Datei Zugriff
Der graue Block steht für ein File - eine logische Datei.
Namen
Organisation (heute Directories)
Zugriffsrechte (Erlaubte Operationen auf Dateien und Dateinamen)
Datei-Struktur (zB Textfile, Daten, Ausführbarer Code, Strukturierte Daten)
OS Sicht: File System
Ermöglicht File Management.
Implementierung von OS-Designer.
Ziele
Effizient Datenblöcke der User Datenträger.
Logische Datei aus dem Hauptspeicher Buffer Datenblöcke.
Elemente des Datei Systems
Records - interne Darstellung von einem (strukturierten) File
Namen (Naming)
Struktur zB mit Directories, organisieren, suchen und finden (aus Benutzer-Sicht)
Lokalisierung und Zugriff
Schutz (Protection)
____________
User Sicht
Record Arten in structured files
Struktured Files
Datensätze einer Datenbank mit gleichem Aussehen (gleicher Struktur)
Man braucht meist eigene Datenbanksoftware um mit ihnen zu arbeiten, aber manche OS unterstützen diese bestimmte Datenformate.
Unstructured sequence of bytes
Default in den meisten OS. Unstructured Files als character-Strings behandelt.
Pile
Records mit unterschiedlicher Länge und Feld-Anzahl
Haben chronologische Reihenfolge
zB jeder Record als Datensatz einer Log-Datei
Schwer zu durchsuchen, Software muss wissen wie Daten zu lesen sind.
Sequential File
Records (Felder) mit fixer Länge und Feldanzahl.
Key-entry bestimmt Position und Reihenfolge der Felder in der Datei (für Suche via Key) .

Indexed sequential file
Noch effizientere Suche: keys in tree mit pointern zu Datensätzen in Datei.
Hinzufügen von Datensätzen schwer
Kurzfristige Lösung: Overflow-file für neu hinzugefügte Dateien
Nach bestimmter Zeit alles mit neuen Indizes neu generiert.
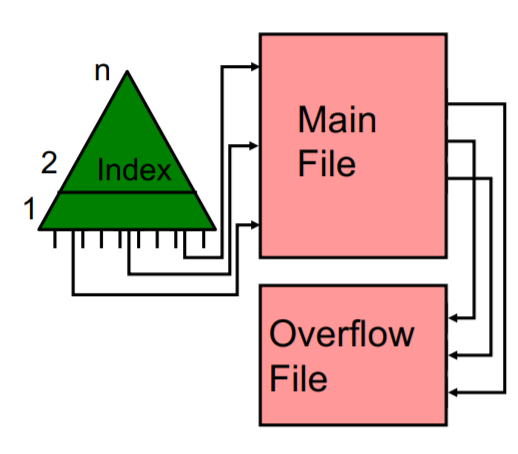
Indexed file
Alle Felder haben eigenen Index, zeigen auf Datensatz
zB Index für Nachnamenfeld in bestimmten Datensatz
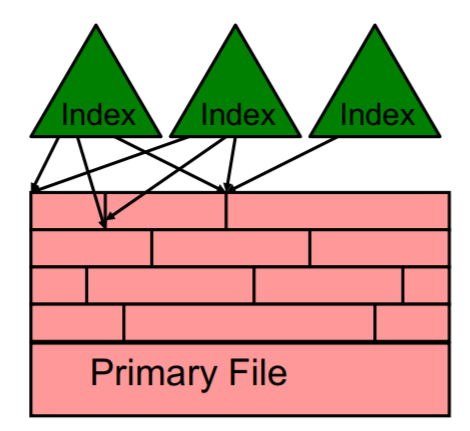
Direct (hashed) file
Kein Sortieren mehr von sequential files notwendig, es wird Hashfunktion für keys benutzt.
Keine sequentielle Reihenfolge der Dateien
Overflow file für Kollisionen beim Einfügen.
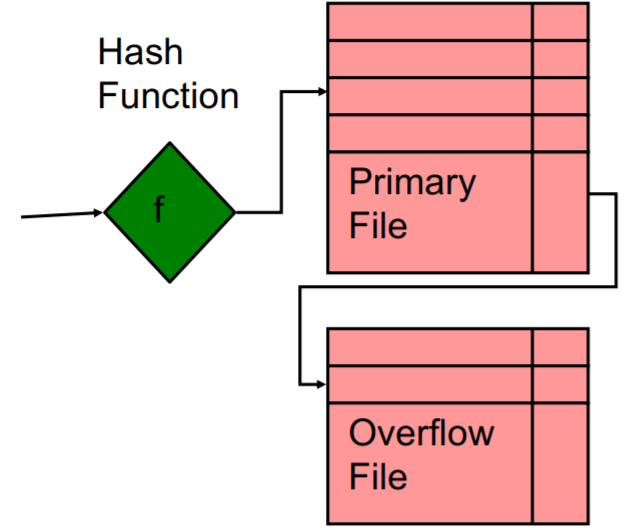
Files
File Types
Regular files
In vielen OS wird nicht zwischen record Arten unterschieden sondern es gibt nur regular files.
Dabei unterscheidet man:
ASCII files
Binary files (Daten, Executables, ...)
OS muss
.exe
files interpretieren können mit: Header, Text, Data, Relocation Bits, Symbol Table.
Für executables muss header magic number (bestimmtes bit muster) sein.
(
.exe
ist das einzige vom OS interpretierbare Format).
Alle anderen Datei-Arten wie zB.wordmuss nicht das OS interpretieren können sondern die spezifische Software.
Directories
Files die dem User erlauben Dateien zu ordnen.
Special Files
Um IO Geräte zu repräsentieren
Character Special Files Für sequenteille IO Geräte
Block Special Files Repräsentation von Platten
File Attributes
Nicht jedes OS muss alle diese Attribute unterstützen - Entscheidung des OS designers.
Metadaten / Verwaltungsdaten:
Creator, Owner, Protection, Password
Flags
Read-only flag
Hidden flag (für Benutzer unsichtbar)
System flag (nur für OS)
Archive flag (soll bei Backup gespeichert werden)
ASCII/binary flag
Random access flag (ob datei sequentiell gelesen werden kann oder auf random access Art)
Temporary flag (ob datei wieder gelöscht wird)
Lock flags (damit man verhindert dass mehrere Prozesse gleichzeitig zugreifen und man inkonsistente Daten hat)
Zeitstempel: Creation time, Time of last access, Time of last change
Record length, Key position, Key length
Current size, Maximum size
File Names
Kann mit Attributen-Namen oder seperat gespeichert werden.
Anzahl der Zeichen (8 bis 255)
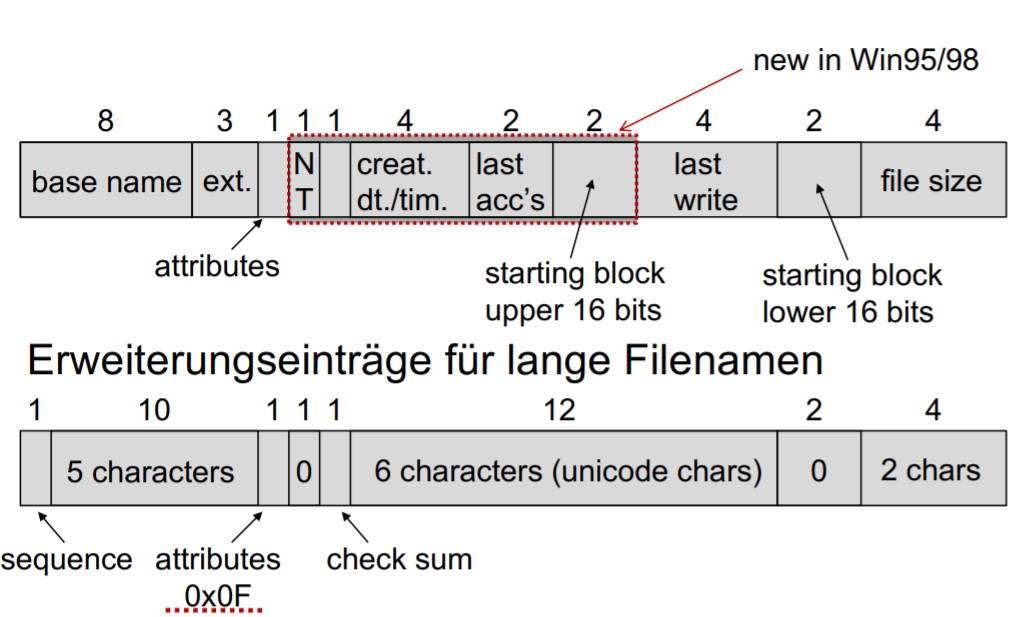
MS-DOS (Win95, Win98): 8 Zeichen + Extension,
Unix: 255 Zeichen
Relevanz von Groß-/Kleinschreibung, erlaubte Zeichen
Unix unterscheidet, Win95/98 nicht
File Name Extensions
zB.docs
Win: Extension ist etwas eigenes und nur eine Extension erlaubt
Unix: Extension ist Teil des File Namens, hat keine Wirkung, beliebig viele Extensions erlaubt
File Operationen
Typische Operationen:
Create, Delete
Open, Close
Read, Write, Append
Seek
Get Attributes, Set Attributes
Rename
Lock
Datei Verzeichnis (File Directory / Folder)
Directories sind spezielle Dateien die zur Verwaltung dienen.
Auflisten: Verzeichnis gespeicherter Dateien.
Abbilden: Dateinamen Datenblöcke auf Festplatte.
Einträge: Name, Attribute, phys. Adresse der Daten
- Einfache Liste (erste OS)
-
Hierarchische Baumstruktur mit beliebig vielen child nodes
Verzeichnisse in Hash-Struktur gespeichert für schnellere Zugriffszeiten (vs. separate Dateien).
Verzeichnis mit Baumstruktur
Von Root-Verzeichnis kann man sich überall durchnavigieren.
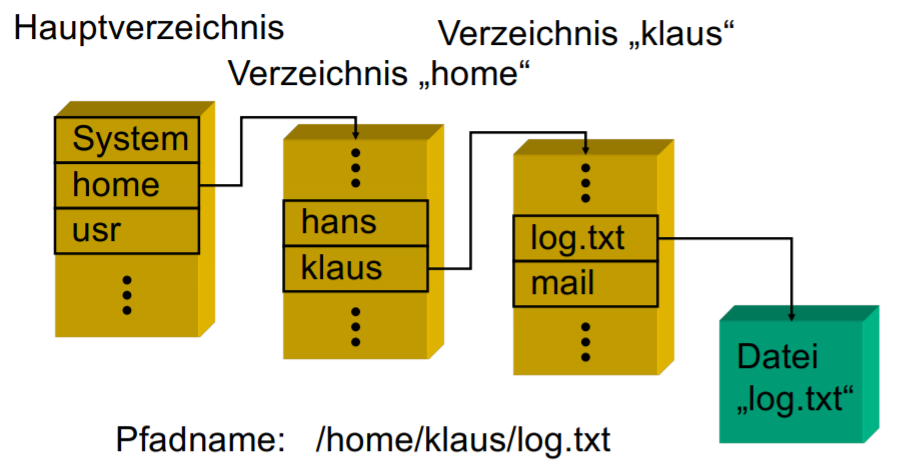
Absoluter Pfadname (absolute path name)
identifiziert Datei durch Beschreibung des Pfads von der Root ausgehend
Windows:
\usr\hans\mailbox
Unix:
/usr/hans/mailbox
Relativer Pfadname (relative path name)
lokalisiert Datei vom Working Directory (Current Directory) aus
Im oberen Beispiel:
current /
working directory
/usr
relative path
hans/mailbox
Current directory . (dot)
./hans/mailbox
Parent directory .. (dotdot)
../home/klaus/log.txt
Directory Operationen
Typische Operationen:
Create, Delete
Opendir, Closedir Readdir,
Rename
Link, Unlink
Änderung der Zugriffsrechte, etc.
____________
OS-Designer Sicht
File System Implementierung
Disk und File-System Layout
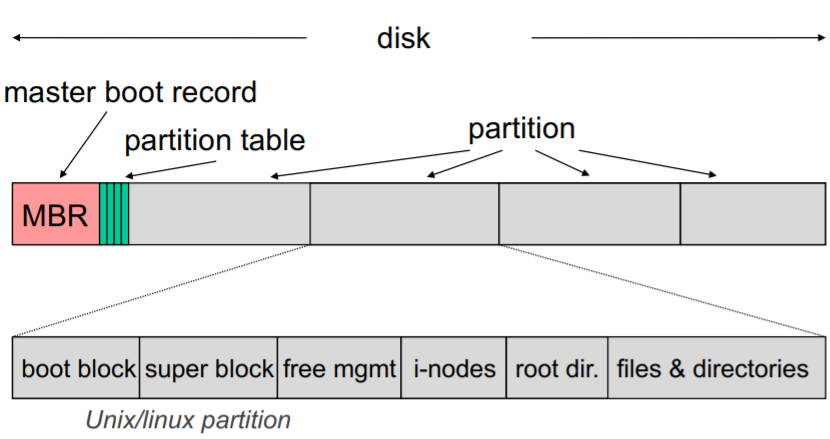
Partitionen
Jedes User Datei-System unabhängige Partition der Festplatte mit gespeichertem File-System
Master Boot Record (MBR)
Damit das OS weiß wie mit den Partitionen zu arbeiten ist.
MBR = initial program loader (IPL), volume boot code, masterboot
Steht in Sektor 0 der Disk, enthält:
Boot Code
Bei Systemstart: BIOS exekutiert beim Hochfahren des Systems Code das MBR
- Lokalisieren der aktiven Partition
-
Ausführen des ersten Blocks (=Boot Block, erster Block der ausgewählten Partition): laden des OS aus der aktiven Partition
Beispiel: Linux Partition
Boot Block Code zum Starten des OS
Super Block Gibt Informationen über Aufbau des restlichen Dateisystems gibt (start / end)
Free Managem.
I-Nodes
Root directory
Files, Directories
Alternativ
Boot Menü zur OS-Partitionswahl von User
Boot Block im ersten Sektor (Früher bei Floppy Disks)
Partition Table
start/end of partitions, active partition - steht am Ende des MBR
Datei Implementierung
Datei im Sekundären Speicher = Sammlung von allokiierten Blöcken
Contiguous Allocation
Datei = eine einzige, aufeinanderfolgende Sequenz an Blöcken.
Wird bei unveränderlichen Datenträgern verwendet wie bei CD-ROMs, DVD-ROMs
gute Performance beim sequentiellen Lesen
Platzprobleme beim Vergrößern einer Datei
Einfügen von Blöcken schwer weil eine Datei nach der anderen kommt (Blöcke müssen verschoben werden)
Löschen und wieder einfügen → externe Fragmentierung
Chained Allocation
Datenblöcke sind miteinander mit einander verlinked - Bearbeiten der Daten leichter.
keine externe Fragmentierung, Platz gut ausgenützt - Blöcke können überall verstreut sein
Verstreutheit = keine Lokalität der Blöcke, viele Bewegungen des Lese-Schreib-Kopfes
langsamer Zugriff bei Random Access (man kann nur sequentiell iterieren)
Zeiger / Pointer in Datenblock-Liste braucht selbst auch Speicher
Indexed Allocation
Wie Chained Allocation aber
Pointer werden in einer eigenen Tabelle gespeichert ( File Allocation Table FAT ).
Schneller als sequentielle Iteration
Blöcke ganz für Nutzdaten verfügbar, kein Speicher für pointer belegt
Platzbedarf für FAT im Arbeitsspeicher
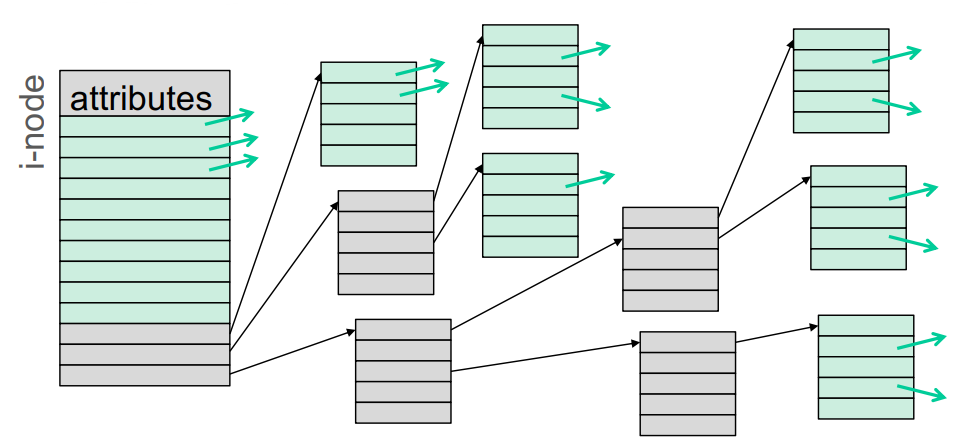
iNodes (Index Node)
In Unix Systemen verwendet um die Blöcke zu Dateien zu finden.
iNode enthält File-Attribute und Pointer.
Pointer zeigt auf die Datenblock der Datei oder auf Indirektions-Block (= Datenblock, kein iNode)
Indirektionsblock kann nur auf Datenblock auf anderen Indirektionsblock zeigen.
Eigenschaften:
iNode wird nur im Memory gebraucht, wenn ein File verwendet wird
iNodes sind in der iNode-Tablle im Dateisystem gespeichert (ein iNode für jedes File).
(notwendig für OS: Array muss maximale Anzahl offener Dateien halten können)
Anzahl der Blockreferenzen pro iNode ist begrenzt
Verwendung indirekter, doppelt und dreifach indirekter Blöcke. Sie können nicht öfter benutzt werden.
Structured file Implementierung
Allokiierung von Datenblöcken für strukturierte Datensätze.
Methoden zur Abbildung von Records auf Datenblöcke.
Fixed blocking
Records fixer Länge - werden der Reihe nach auf die Datenblöcke übertragen. → Verschnitt.
Beschränkte Anzahl von Records pro Datenblock.
Effizient aber extreme Fragmentierung.

Variable-length spanned blocking
Records variabler Länge - können auch auf mehreren Blöcken verteilt sein. → Kein Verschnitt.
Speicher wird besser genutzt.
Lesen eines Records kann 2 Block-Zugriffe beanspruchen.

Variable-length unspanned blocking
Records variabler Länge - können als ganzes in einem Block gepeichert werden aber nicht nicht über Blockgrenzen hinweg gehen. → Verschnitt.
Jeder Record kann mit einem Blockzugriff gelesen werden
Speicher nicht gut ausgenutzt

Directory Implementierung
Auffinden von Dateien
- Lokalisierung des Root Directories
- Interpretation des Pfadnamens
Position des Root Directories
Ermittlung der fixen Position vom Partitionsanfang durch OS:
Unix: Startadresse der i-nodes im Super Block - Erster i-node verweist of Root Directory
Win: Boot Sector enthält Information über Adresse der Master File Table (MFT)
Directories und File-Attribute
Wo findet OS die File-Attribute?
In Directory-Einträgen
zB Directory-Einträge fixer Größe der Form:
Filename (fixe Größe), Struktur mit File Attributen, eine oder mehrere Block-Adressen
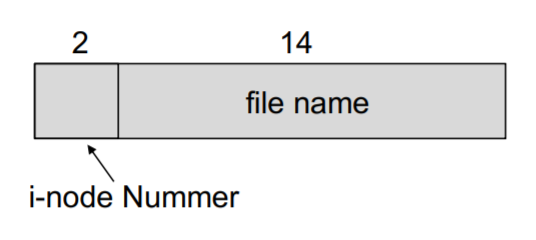
In i-nodes
Directory Einträge: Filename, i-node Nummer
File Block Size
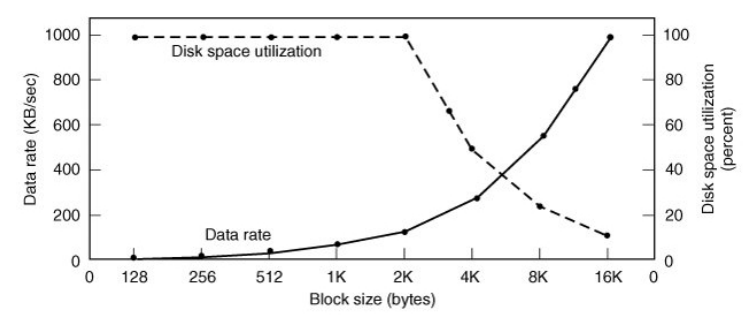
Wie groß sollen die Blöcke von Dateien sein?
Nutzung des Speicherplatzes vs. Zugriffszeit
In Unix Dateisystemen sind über 95% der Dateisysteme < 2KB groß
Verwaltung freier Blöcke
Disk Allocation Table zur Markierung freier Blöcke.
Chained Free Portions
Verlinkte liste von freien Speicherbereichen mit (Zeiger, Länge)-Eintrag.
Mühsame Suche durch die Liste
mit der Zeit Fragmentierung
Overhead für Zeigerupdate (=R/W) bei Fileoperationen.
Bit Tables
Bit-vektor mit je einem Bit pro Plattenblock. (0 oder 1 je nachdem ob Block frei ist) .
Geringer Platzbedarf, guter Überblick über Folgen von freien Blöcken.
Indexing
Freie Blöcke als eigenes File betrachtet. (4 Methoden um Daten zu verwalten siehe oben)
Effizient für alle Datei-Belegungsverfahren.
Performance
Plattenzugriffe beschleunigen durch:
Disk Caching (siehe vorherige Eineheit)
Ausnutzung der Lokalität (Lokalitätsprinzip)
Bedeutung eines Blocks für die Konsistenz des Filesystems: read-only oder bearbeitbar → Write Back (wenn block verändert wurde)
Block Read Ahead
Vorauslesen von Folgeblöcken, nicht nur on-demand lesen.
Kopfbewegungen der Disk
Weniger Bewegungen durch Scheduling von Plattenzugriffen.
Daten so auf die Platte legen, dass Zugriffe effizient sind:
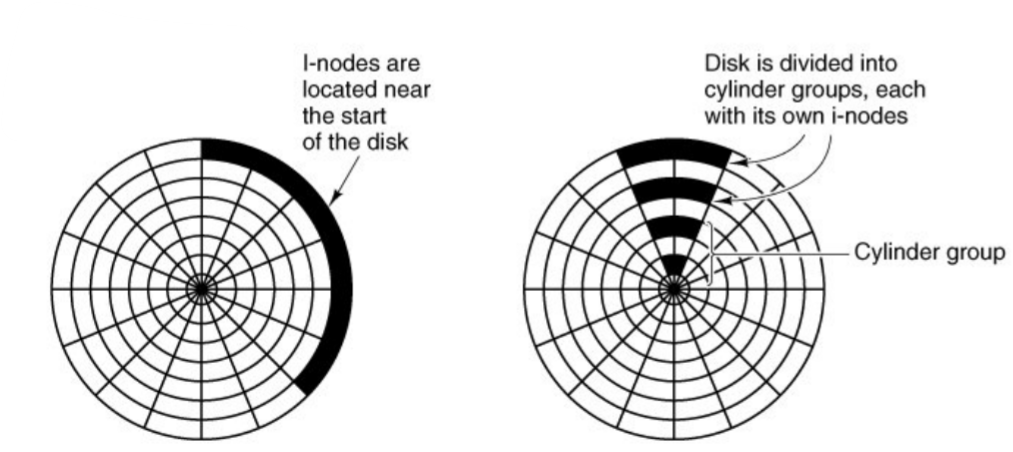
Dateiverwaltungsinformationen (Tables der Datei) und Datenblöcke nahe bei einander speichern
zB In Unix werden I-Nodes gleichmäßig verteilt: