I/O, Disk Scheduling
I/O
Definition
Ein-/Ausgabe = Operationen die über OS Zugriff auf externe Geräte und Ports vom Prozessor erlauben.
3 Arten von externen IO-Geräten
Mensch-Maschinen-Interface zB Anzeige, Tastatur, Maus, ...
Maschinen-Interface elektronische Geräte, zB Datenlaufwerke, Sensoren, USB Sticks...
Netzwerk-Kommunikation spezielle IO für Datenaustausch mit anderen Geräten
Unterschiede zwischen Arten
Übertragungs-Datenrate zB Tastatur <300 byte/min, Netzwerke >10 GB/s übertragen.
Anwendung zB Dateiverwaltungs-Layer: Festplatte um Files zu speichern / als
Sekundärspeicher für Virtual Memory Management.
Ansteuerungs-Komplexität Pollen von Geräten: r/w von einem Gerät, Kontrolle bei Prozess
Interrupt: IO-Operation selbstständig ausgeführt, meldet sich mit interrupt zurück
Transfer-Einheiten zB Zeichen vs. Blöcke
Daten-Repräsentation Byte Order, Parität
Fehlerbehandlung
Blocking vs. Non-Blocking - Bestimmt ob aufrufender Prozess blockiert wird oder nicht.
Blocking IO
Prozess wird von
running
in die
blocked
queue gestellt werden.
Non-Blocking IO IO-Operationen wird ohne Unterbrechung ausgeführt - Returnstatus mit Feedback.
Prozess wird nicht blockiert.
zB für Keyboard oder Gaming-Konsolen-Joysticks: Feedback: # der übertragenen Bytes
IO Funktionen
Möglichkeiten von einem Prozess mit der IO-Devices zu interagieren.
IO-Operation = IO-Command + Abschluss
IO-Modul = IO-Device
Programmed I/O- Direkte programmierte I/O
Prozess setztzt einen IO-Command ab und wartet dann mit busy waiting auf den Abschluss der Operation bevor er fortfährt.
Einfachste Strategie: Einfach zu implementieren und managen, schlechte Performance
Interrupt-driven I/O
-
- (Interrupt Service Routine)
Prozess schickt ein IO-Command ab.
Falls IO-Operation blocking: Prozess blockiert und ein anderer Prozess vom Scheduler gewählt.
Ansonsten Prozess forgesetzt.
Wenn Operation fertig, wird Prozess durch IO-Device unterbrochen.
Mehr Overhead aber gute Systemperformance, ermöglicht Parallelität.
Direct Memory Access DMA
-
-
Hardwareunterstützung für OS: DMA-Controller(IO Baustein)
Kontrolliert den Datenaustausch zwischen Hauptspeicher und einem IO-Device.
Kein Kontextwechsle der CPU notwendig, Daten quasi parallel mit der CPU-Aktivität übertragen.
Verarbeitung parallel zur CPU, Performance-Gewinn.
Prozess schickt IO-Kommando an IO-Device.
Das IO-Device kopiert selbstständig Daten von Prozess.
Wenn Operation fertig, wird Prozess durch IO-Device unterbrochen.
DMA
Implementierung des Direct Memory Access (DMA)
Kontrollübergabe via Bus DMA-Controller übernimmt CPU Funktionalität für Memory Access.
Möglichkeiten für DMA-Transfer:
- blockwise - optionalerweise parallel mit CPU-Aktivität
- cycle stealing - DMA erzwingt einzelne Übertragungszyklen am Bus
Eigenschaften
effizient: Kein Kontextwechsel der CPU notwendig.
flexibel: DMA-Modul kann mehrere IO-Module versorgen (mehrere Ports oder eigener IO-Bus)
I/O Channel
Verallgemeinerung / Erweiterung der DMA
IO-Baustein, noch intelligenter als DMA.
Kann ganze IO-Operationen-Sequenzen ausführen die einprogrammiert werden können.
Interrupt signalisiert Ende.
Noch mehr Parallelität und mehr Performance.
Zwei typische Arten von I/O Channels:
- Selector Channel: jeweils nur ein Gerät aktiv
- Multiplexer Channel: mehrere Geräte gleichzeitig
OS Design
Widersprüchliche Ziele
Effizienz Gerätespezifische Implementierungen
IO soll nicht System-Bottleneck sein
Wenn System zu langsam - Swapping möglich - was selbst wieder eine IO-Operation ist.
Flexibilität (Generality) einheitliche Schnittstellen für alle IO-Devices
zB Zugriffsfunktionen wie open, close, lock, unlock, ...
Abstraktion, Austauschbarkeit von Geräten, geringere Fehlermöglichkeiten
Schichtenmodell
Schichtungsebenen / Schichtenmodell / Struktur von IO-Funktionen für Peripheriegeräte
Damit man widersprüchliche Ziele berücksichtigen kann: Mehrere Schnittstellen.
Layer nach Komplexität, Zeitkonstanten, Abstraktion.
1) Logical IO
(oberste Schicht)
logische Bedienung des Gerätes - Gleiche Befehle, einheitlich über die meisten IO-Geräte.
In einem File-System besteht die Logical IO aus 3 Komponenten:
Directory Management(oberste Schicht)
symbolische Dateinamen Referenz auf die Datei
Directory-Benutzeroperationen wie
add
,
delete
, …
File System
logische Struktur von Dateien und Dateioperationen wie open, close, read, write, …
Byte-Folge oder logische Struktur wie zB eine
.csv
Datei die Unterstützung zum Interpretieren braucht.
Physical Organisation(unterste schicht, physical layer)
logische pointer Spuren und Sektoren auf der Festplatte
2) Device IO
(Übersetzung zwischen oberster und unterster Schicht)
Operationen IO-Kommando- und Kontroll-Kommando-Sequenz
Buffering zwischen Applikationsprogramm und Hardware
3) Scheduling and Control
(unterste Schicht)
Ganz spezifische Ansteuerung des Geräts via Gerätehardawre.
Queuing, Verwaltung von IO-Operationen, Interrupt-Handling, Lesen des IO-Status.
Synchrone vs. Asynchrone I/O
Synchron - blocking
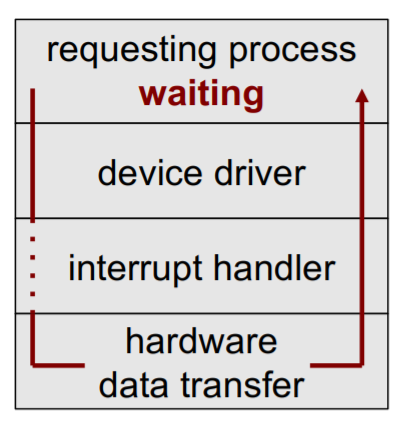
Prozess setzt nach Abschluss der Operation an call fort.
Asynchron - non-blocking
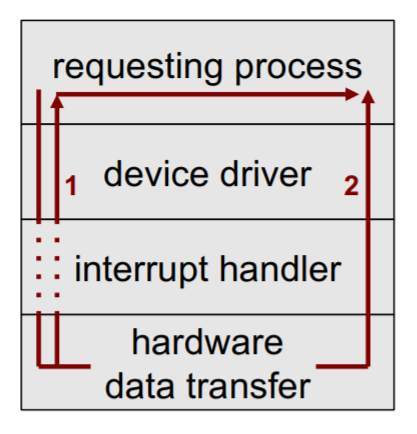
Kontrolle teilt sich, Prozess arbeitet parallel bzw asynchron weiter.
Ergebnis kann in Puffer geschrieben werden und später von Prozess gelesen werden.
Oder es gibt ein Interrupt Signal und es wird sofort reagiert (applikationsabhängig).
Synchroner Request - in depth
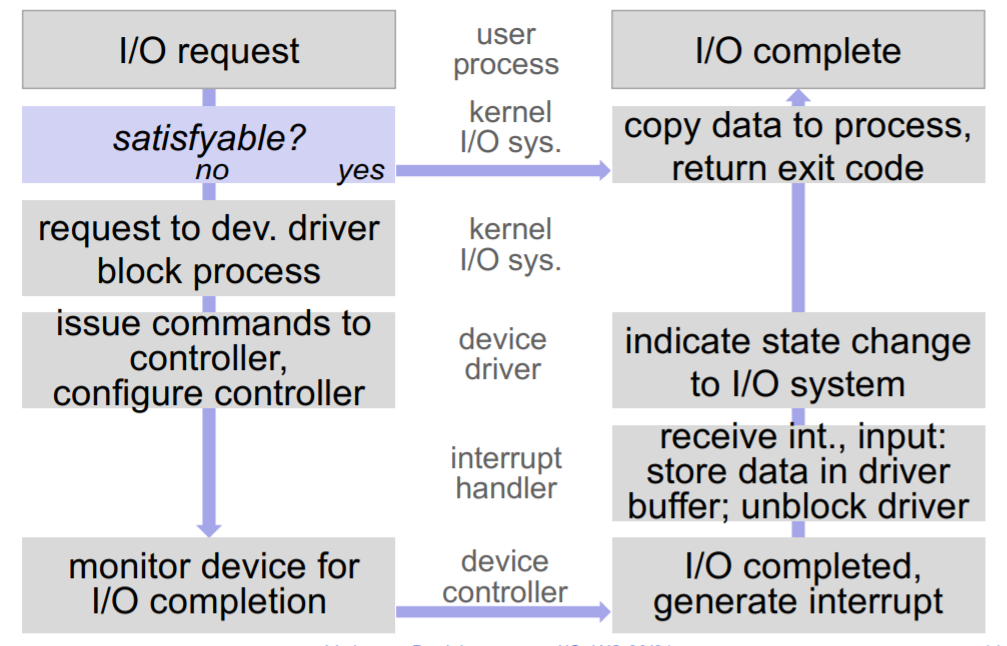
-
IO-Request auf User-Ebene aufgerufen
- Kernel führt system calls die schnell abarbeitbar sind (zB das Lesen von Registern) sofort aus und blockiert Prozess nicht und schreibt Daten sofort in Puffer. → Ende
- Call nicht sofort Erfüllbar → Schritt 2
- Prozess blockiert, IO-request an Driver geschickt damit IO-call aufgesetzt wird
-
Controller wird für Gerät programmiert
Vorbereitung: Control-Register gesetzt, Control-Bits gesetzt ...
Controller angestoßen IO-Operation durchzuführen
-
Controller führt Operation aus
- Transfer von Daten in Treiberpuffer
- Signal mit interrupt von interrupt-handler
-
IO-Request auf User-Ebene aufgerufen
Puffern von I/O-Anfragen
Puffer = Daten-Zwischenspeicher für IO-Transfer zwischen OS und IO-Gerät
Kosten: Speicher und Puffermanagement.
Erhöht Performance und Flexibilität
Reduktion des Overheads
Kann mehrere low-level IO-Operationen zusammenfassen und aufeinmal ausführen
zB mehrere Schreiboperationen → via Buffer eine einzige zusammengefasste Schreiboperation
Entkopplung von IO-Operation und Programm- ab 2 Buffers die parallel arbeiten können
OS entscheidet wann es am günstigsten ist IO-Operation auszuführen.
Swapping zwischen Buffer und Sekundärspeicher möglich.
Abfangen von Spitzenlastfällen- Performanceunterschiede zwischen Rechner CPU und Gerät
so lange Buffer Platz hat abzufangen.
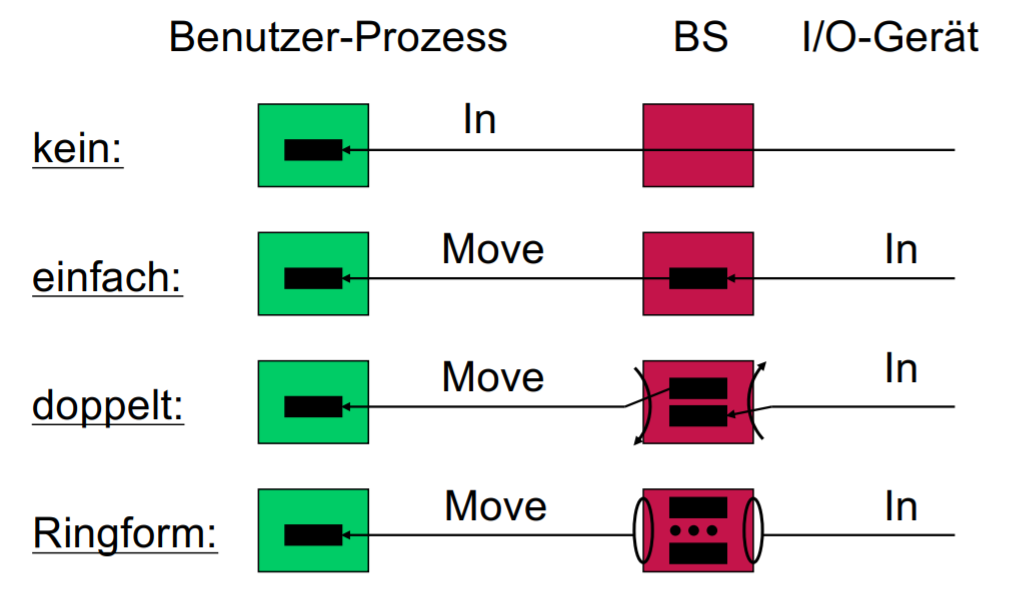
Kein Buffer bedeutet direkte Zugriffe auf IO-Gerät durch OS.
Ab 2 oder mehr Buffern: Operationen entkoppelt und zusammengefasstwerden.
____________
Disk I/O
Disk Scheduling und Caching für höhere durchschnittliche Zugriffsgeschwindigkeit
Disk Scheduling
Mittelwerte die wir zum Rechnen benutzen:
seek time benötigte Zeit um Disk-Arm auf die richtige Spur zu bewegen
rotational delay Zeitverzögerung, bis Sektor / Block in Spur gefunden
transfer time Datenübertragung
average access time benötigte Zeit für Datenzugriff
Charakteristische Zeiten
Bestimmend: Organisation der Daten auf der Festplatte
Anzahl der zu übertragenden Bytes
Anzahl der Bytes pro Spur
Umdrehungsgeschwindigkeit in
Im Durchschnitt muss sich die Scheibe halb rotieren bis Sektor gefunden wurde (best case keine Rotation, worst case fast eine ganze Rotation).
Wobeider prozentuelle Anteil der Bytes in der Spur ist die wir lesen wollen.
Strategien
Ziel: Ordnung von Disk-I/O Requests zur Minimierung der Seek Time
Priority
First-In, First-Out (FIFO)
Last-In, First-Out (LIFO)
Shortest Service Time First (SSTF)
: Zieht geringsten Weg von der aktuellen Spur in Betracht
SCAN (Elevator Algorithm)
Wie oben, aber damit auch requests die weiter entfernt sind ankommen - keine Starvation.
Geht über alle Spuren und führt alle requests die währenddessen eintreffen aus - wie ein Aufzug.
C-Scan
Versucht ungleichmäßige Behandlung der Ränder auszugleichen.
Leerfahrten und dadurch Behandlnug der Requests immer in die gleiche Richtung.
N-step-SCAN und FSCAN
Bündelt requests zusammen in einem Buffer.
RAID
Redundant Array of Independent Disks
Mehrere Platten die parallel verwendet werden (die auch redundante Informationen beinhalten)
Für Beschleunigung und Fehlertoleranz
Disk Caching
Ähnlich wie Memory Cache Puffer im Hauptspeicher für Disk-Sektoren
Lokalitätsprinzip bei Daten wahrscheinlich mehrfach auf die selben Disk-Stellen hintereinander zuzugreifen
Austauschstrategien / Replacement-Strategien
Strategie um zu besimmen was im Cache ersetzt werden soll (genau wie bei Paging) .
Austausch im Cache bei Bedarf oder im Voraus
Least Recently Used (LRU)
Least Frequently Used (LFU)
Frequency-Based Replacement (Verbesserung von LFU)
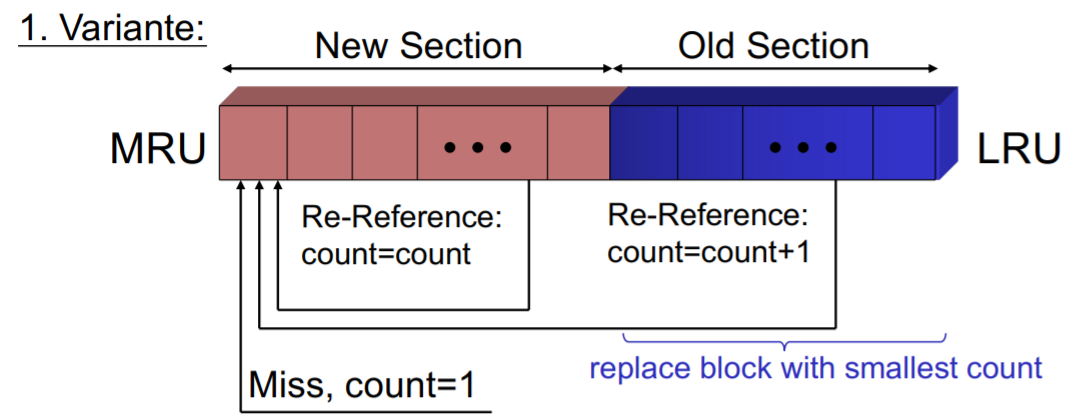
Frequency-Based Replacement
Lokalitätsprinzips + Hohe hit-frequency
Blöcke nach Zugriffszeitpunkt geordnet.
Links Blöcke im Bereich "New Section" die vor kurzem referenziert wurden.
Die restlichen Blöcke sind in der "Old Section".
Am Anfang haben alle Blöcke denn Reference-Counter /
count
-Wert 1.
New Section
Wird auf Grund von Lokalität nicht entfernt.
count
bleibt unverändert.
Old Section
Wir ersetzen Blöcke aus der old section die die niedrigste hit-frequency / höchsten
count
haben.
Bei Zugriff wird
count
erhöht und Block nach links verschoben.
Verbesserung: Section zwischen new und old.
