Memory Management
Detailiert: Primärspeicher vs. Sekundärspeicher
-
Primärspeicher
/ Hauptspeicher - kurz: Speicher
Register, Caches, Arbeitsspeicher (RAM)
-
Sekundärspeicher
Festplatten, CDs, DVDs
-
Primärspeicher
/ Hauptspeicher - kurz: Speicher
Speicherverwaltung / Memory Management
Das OS wird zuerst in den Hauptspeicher eingefügt und stellt dann Prozessen Speicher zur verfügung.
Wir wollen Speicher effektiv aufteilen und verwalten:
Partitioning - Speicheraufteilung auf Prozesse
Positioning (= Allocation + Relocation) - Speichern von Code und Daten, Virtual-Memory Management
Protection - Speicherschutz
Sharing - gemeinsamer Zugriff mit mutual exclusion
Performance - schnelle, effektive logische und physikalische Organisation
Partitioning
Haupt-Speicher-Aufteilung auf Prozesse.
Prozesse beinhalten Programm und Daten, Kontext.
OS wird immer zuerst eingefügt.
Zu wenig Speicherplatz:
Swapping / Auslagern von Prozessen vorrübergehend auf Sekundärspeicher auslagern.
Overlays / Überladen von Programmen Programm Anteile im Primär- oder Sekundärspeicher.
Speicherplatz wird nicht effizient ausgenützt:
Fragmentierung Teile des Speichers bleiben ungenützt.
Interne Fragmentierung Ungenützter Speicherplatz innerhalb einer Partition.
Externe Fragmentierung Zerstückelung des Speicherbereichs außerhalb der Partitionen.
Löst sich mit compaction (Zusammenschieben, teure Operation).
1) Fixed Partitioning
Statisch Partitionen mit fix vordefinierten Größe.
Problem Speichernutzung ineffizient, interne Fragmentierung
Gleiche Partitions-Größen
Es ist bei gleicher Partitionsgröße egal wie man sie mit Prozessen belegt.
Programm kann zu groß für Partition sein obwohl Speicher leer
Ineffizient - kleines Programm kann gesamte Partition blockieren
Interne Fragmentierung
Unterschiedliche Partitions-Größen
Wir wollen Partitionen optimal belegen.
Eine Queue für jede Partition
Partitionen nach Größe sortiert. Je nach Größe, kommt Prozess in eine andere Queue.
Problem: kleine Prozesse können in Warteschlange sein obwohl größere Partitionen leer sind.
Eine Queue für alle Partitionen
Nimmt kleinstmöglichste Partition
2) Dynamic Partitioning
Dynamisch Partitionen mit variabler Länge und Anzahl.
Problem Externe Fragmentierung
Weist jedem Prozess eine Partition zu die exakt so groß ist.
Für die ersten Prozesse optimal, danach haben "Löcher" ohne Partition und wieder fixe Größen.
Placement Stategien beim Einfügen
Auswahl der Partition in die ein Prozess eingefügt werden soll:
Best fit - Geringste Platzverschwendung / Geringster Verschnitt
First fit - erste freie Partition von oben
Next fit - wie first fit, fängt aber von der letzten freien Stelle wo eingefügt wurde an
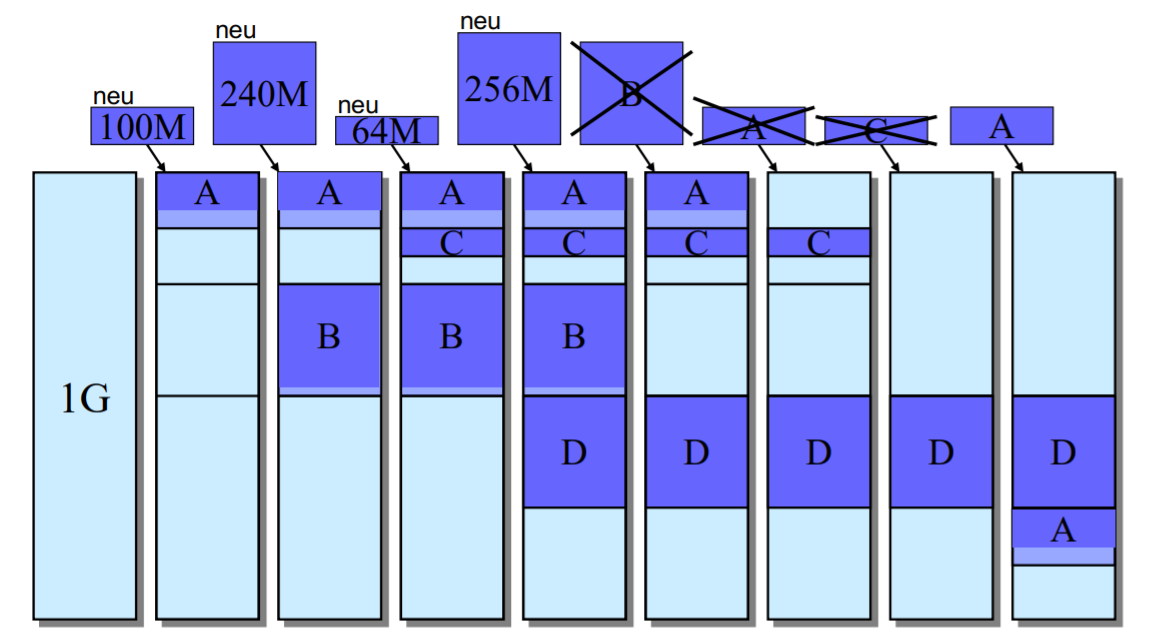
3) Buddy System
Fixed und dynamic partitioning sind nicht mehr in Benutzung.
Versucht Schwächen von statischer und dynamischer Partitionierung auszugleichen:
konfigurierbare Größen
Größenvergabe nur mit Zweierpotenzen wobei für Schranken angegeben werden.
Buddy = Speicher-Block
Ablauf: Anforderung von Blockgröße
-
Suche nach Block mit
für die Schranken
.
Sucht nach kleinstem bestehenden passenden Block.
Am Anfang ist der gesamte Speicher ein großer Block.
-
Falls nicht gefunden, zerteile nächstgrößeren Block in
kleinere (so lange bis gefunden).
Zerkleinert größere Blöcke.
zB angenommen wir findendann zerteilen wir den Blockmal herunter.
Nach dem Löschen: Vereine benachbarte Blöcke die nicht belegt wurden.
__________
Relocation - Logische Adressierung
Referenzen auf physikalischen Speicher müssen veränderbar sein.
Wir wollen Daten im Speicher verschieben können (= dynamisch positionieren) da wir andere absolute Adressen haben bei
zB Swapping, Compaction - wenn Prozess wieder ins Speicher geholt wird
Programmausführung auf unterschiedlichen Rechnern mit unterschiedlichen Speicherbelegungen.
Addressübersetzung
Zur Laufzeit: logische und relative Adressen aus Programm absolute Adressen.
Memory Management Unit (Hardware) und Page-table / Segment-table unterstützen Übersetzung.
Physische (absolute) Adresse
Nicht veränderbar - Absolute Position in Hauptspeicher
Logische Adresse
Veränderbare Variablenzuweisung.
Pointer zu Position im Speicher - unabhängig von Speicherorganisation.
Relative Adresse
Position relativ zur logischen Adresse.
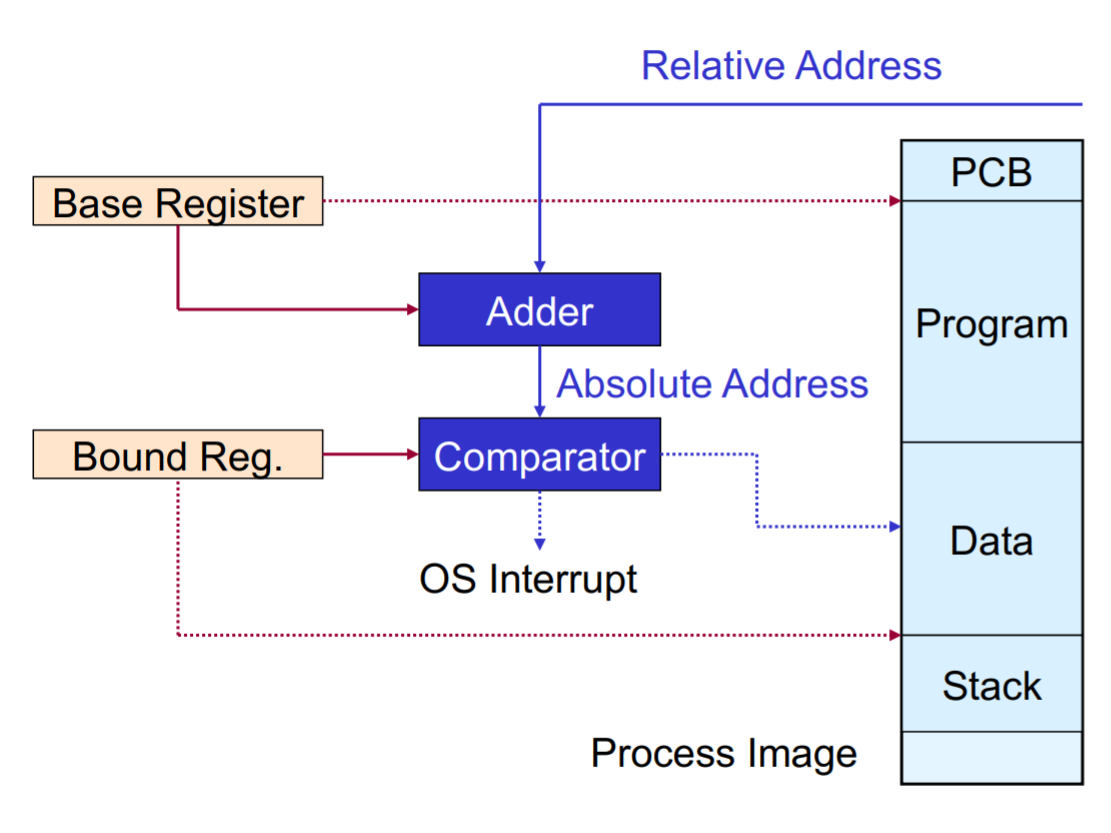
Einfache Addressübersetzung
Erfolgt bei jedem Speicherzugriff durch Hardware.
Wir speichern 2 wichtige physische Addressen
Base Register Programm-Anfang: Zeigt auf Start-Adresse vom laufenden Prozesses
Bound Register Programm-Ende: damit wir nur auf gültige Addressbereiche zugreifen
Umsetzung:
- Übersetzte absolute Addresse = Startaddresse + Relative Addresse als Offset
- Danach vergleich mit Boundregister damit Addressbereich / Bound nicht überschritten wird
__________
Relocation - Virtual memory management
Virtual Memory
Wir abstrahieren darüber welcher Anteil vom Prozess im Hauptspeicher ist.
Wir übernehmen nur notwendige Frames vom Prozess ins Hauptspeicher.
Logischer Addressraum kann viel größer sein als der physischer Addressraum.
mehr Speicherplatz, Parallelität
Ausführung von Prozessen die viel größer sind als der Speicherplatz
Anteil von Prozess Frames / Segmente im Sekundärspeicher heißt virtual memory.
Resident Set
Anteil vom Prozess im Hauptspeicher.
Fixed Allocation Bei Prozesserstellung fixe Anzahl an Frames zugewiesen
Variable Allocation Allokiierten Frames können sich während Prozesslebensdauer noch ändern
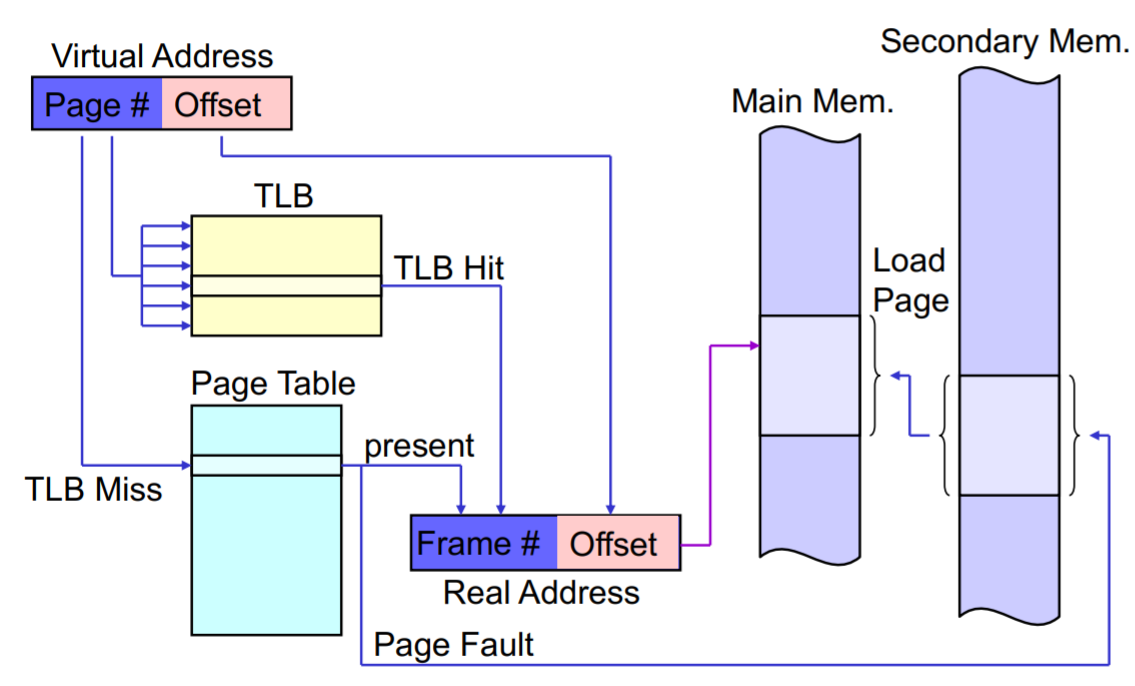
Page Fault (Exception Handling)
Adresse nicht im Hauptspeicher gefunden - Suche im Sekundärspeicher ( Demand Paging ).
Thrashing
Management beansprucht mehr Ressourcen als Prozesse.
zB zu viele Page faults da Resident set zu klein
Prozessor muss sehr oft vom Sekunderspeicher laden (IO Operation).
Lösung: Swapping von Prozessen, Resident set vergrößern
1) Segmentierung
Wir wollen nicht gesamtes Programm für Prozess in Hauptspeicher laden sondern Segmente davon definieren die dann in den Partitionen eingefügt werden.
Es kann zu Fragmentierung kommen.
Segment Programm-Block mit beliebiger Länge die zusammengehörenden Code und Daten enthält.
Segment-Tabelle Enthält Segmentlänge und Start (Base der physischen Adresse).
Adressübersetzung mit Segment-tabelle
Logische Addresse besteht aus Offset und Segmentnummer (= Index aus Segmenttabelle)
Logische Addresse: ( Segment-Index | Offset )
↓
Segment table: ( Length | Base )
↓
Physische Addresse: Base + Offset 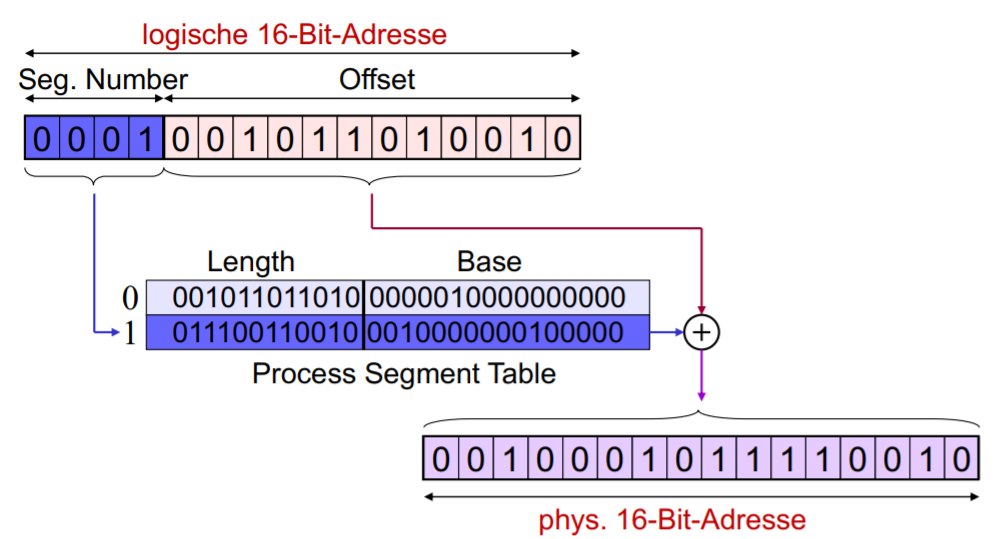
2) Paging
Effizienter als Segmentierung
Page Frame
Arbeitsspeicher im Vorherein in gleich große Frames unterteilt.
Relativ klein verglichen mit Segmenten.
In der Free Frame List stehen alle freien Frames im Speicher
Page
Logische Addressbereiche in gleich große Pages unterteilt.
Pages werden zur Laufzeit in Frames hineingeladen (wobei der Frame dann Lücken haben kann) .
Pages und Frames sind gleich lang (Größe in Zweierpotenzen)
Page-table
Page table um für jede Page eines Prozesses die Position im Frame zu finden. Alle bits stehen für booleans.
Present Bit Seite im Hauptspeicher?
Frame Number pointer zu Frame
Modified Bit Seite seit dem letzten Load verändert? (Konsistenz mit festplatte)
Control Bits r/w, kernel/user (für protection, security) , locking (nicht entfernen)
Adressübersetzung
Compiler, Linker muss nichts über Unterteilung nichts wissen - passiert durch Paging-Hardware
Logischer Addressbereich Physischer Addressbereich
( Page Number | Offset ) ( Frame Number | Offset )
| ↑
index └──────────────────────────────┘ table entry
Page Table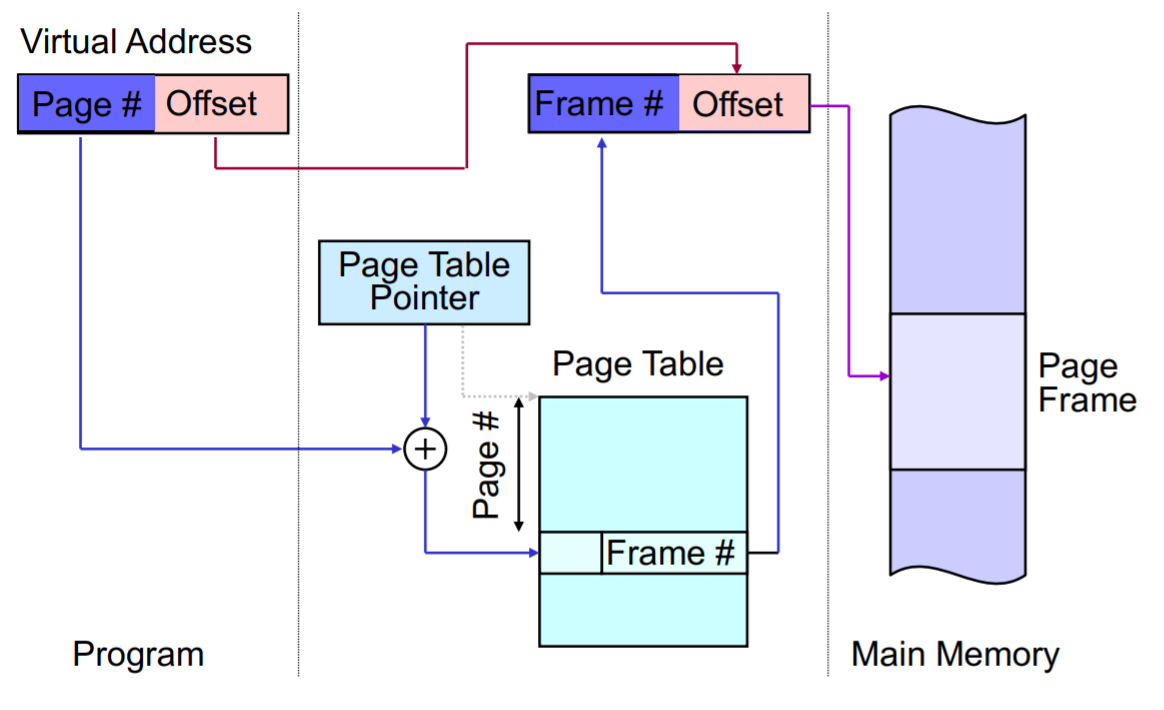
Eintrag in page table wird gefunden indem mit dem pointer welche die page table base enthält addiert wird.
Multilevel Page Tables
Die page-table der Prozesse selbst muss im Arbeitsspeicher sein - Kann mit der Zeit sehr groß werden.
Page-table wird selbst in pages unterteilt, die in der root-page-table nachgeschlagen werden.
Ineffizient: 2 Speicherzugriffe vor jedem eigentlichen Speicherzugriff.
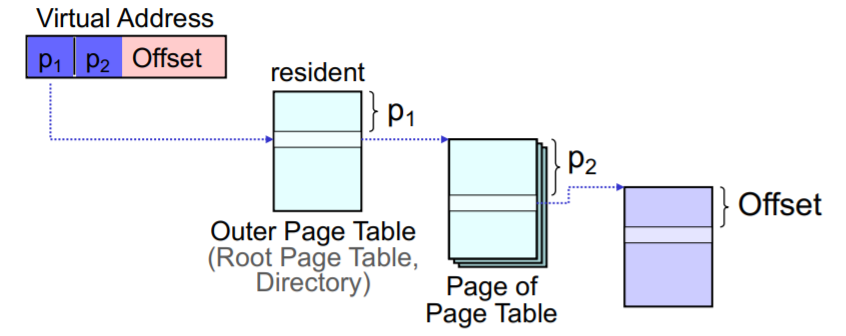
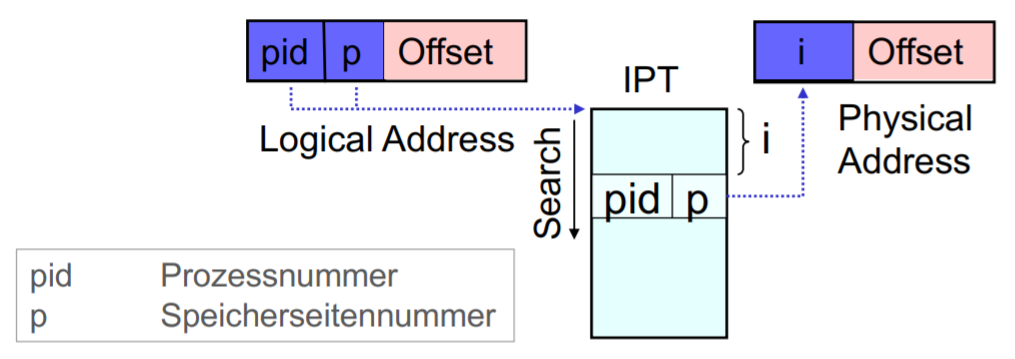
Inverted Page Table IPT
Platz sparen indem sich Prozesse eine große Tabelle teilen
Keine page-table pro Prozess sondern eine große page-table für alle Prozesse im Arbeitsspeicher.
Suche durch assoziativen Suchalgorithmus oder Hashing mit Hardware.
Translation Lookaside Buffer TLB
Um zu vermeiden dass 2 physikalische Speichezugriffe notwendig sind (page table, daten lesen).
Cache in der CPU für die Einträge der page-table auf die zuletzt zugegriffen wurde.
Assoziativer Zugriff beim Suchen (sofort zugreifbar).
TLB wird bei jedem context switch gelöscht.
Bei TLB-miss wird Cache erweitert.
Effizient wegen Lokalitätsprinzip.
Fetch policy
Wann kommen Seiten in den Hauptspeicher? Ähnlich wie: Pre-Cleaning vs. Demand Cleaning
Demand Paging laden bei Bedarf (viele Page faults am Anfang)
Prepaging lädt mehr im Voraus (Lokalitätsprinzip) - viele Seiten nicht benötigt
Replace policy
Welche pages werden ersetzt wenn eine neue ins Hauptspeicher geladen wird?
local replacement Austauschstrategie auf Seiten des gleichen Prozesses
global replacement Austauschstrategie auf alle Seiten des Hauptspeichers
Austausch-Strategien
OPT Policy (optimal)
Optimale Strategie nicht implementierbar sondern als Maßstab für andere Strategien.
Wählt die Page die am spätesten referenziert wird.
Minimale #page-faults
LRU Policy (last recently used)
Ersetzt die Seite die am längsten nicht benützt worden ist.
Nutzt zeitliche Lokalität, sehr nahe zur optimaler strategie
Viel overhead, viel zum Protokollieren, aufwendig zu Implementieren:
Speichern der Zugriffszeiten + Suche
FIFO Policy
Ersetzt die älteste Seite (die zuerst geladen wurde).
Einfach zu implementieren: Pointer welcher zyklisch die page-frames iteriert
Keine Information über Frequenz der Verwendung der Seite
Deutlich mehr #page-faults
Clock Policy
Ringpuffer aus Seiten die für Austausch in Frage kommen.
Jede Seite hat ein used-bit (welche sagt ob neulich auf sie zugegriffen wurde oder nicht).
Nicht viel mehr page-faults als LRU.
Pointer wird am Anfang zufällig gesetzt.
- Es wird nach 0 gesucht und alle 1-Einträge dazwischen werden geflipped.
- Nachdem 0 gefunden wurde, wird die Seite ersetzt und der Bit auf 1 gesetzt
- Danach wird der pointer auf die nächste Position gestellt bis zur nächste Suche.
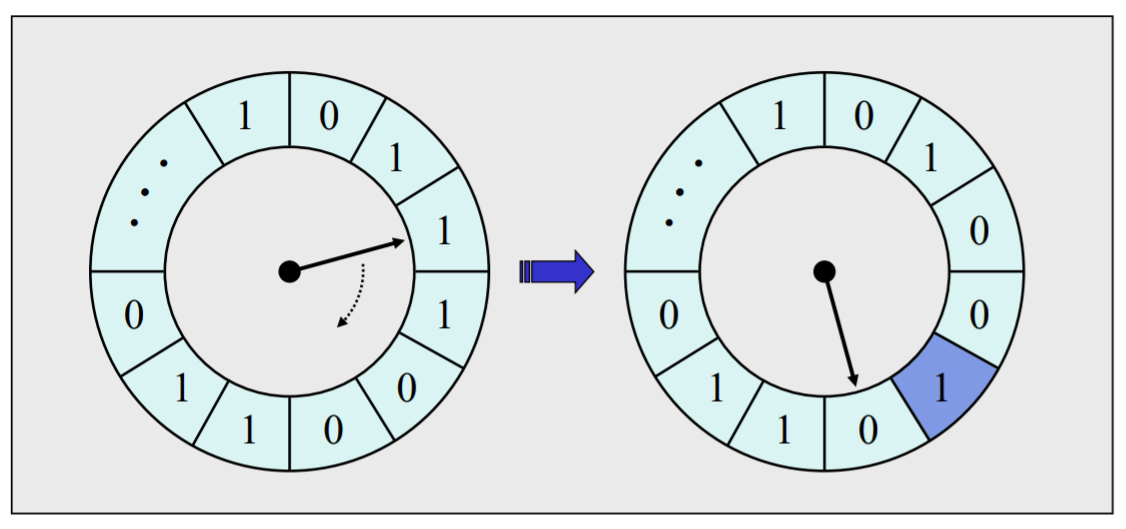
In diesem Szenario, wird in der darauf erneut folgenden Replacement, gleich die page ersetzt auf die der pointer das letzte Mal gezeigt hat, weil dort eine 0 steht und das bit auf 1 geflipped.
Working Set Strategie
Zur Bestimmung der richtigen Größe des Resident-Sets
zu wenige Frames: viele Page-Faults
zu viele Frames: weniger Arbeitsspeicher verfügbar, geringere Parallelität
Working Set von einem Prozess
= Set an pages, auf die virtuelle Zeiteinheiten vor Zeitpunkt zugegriffen wurde.
Virtuelle Zeiteinheiten: Nur Zeitfortschreitung im Prozess - zB preemptions nicht betrachtet.
Eigenschaften:
wächst am Anfang schnell
stabilisiert sich mit Prozessausführung
wächst wieder wenn wir anderen Prozess ausführen
Anwendung
Wir checken periodisch das Working Set für alle Prozesse.
Resident Set Working Set
Gib Speicher Frei.
Lösche pages die nicht im Working Set sind.
Resident Set Working Set
Allokiiere fehlende Frames aus Sekundärspeicher, durch Swapping anderer Prozesse
Eigenschaften
Overhead: Zusätzliches Logging und Ordnen von Seitenreferenzen
Optimales variiert und ist zur Laufzeit unbekannt
Best Practice
Beobachtung der #page-faults statt working-set pro Zeitintervall (für einzelne Prozesse) mit einem vordefinierten threshold.
Bei threshhold-Überschreitung bin ich im thrashing und suspend das Prozess.
Protection
Speicherschutz: Prozesse sollen nur auf die eigenen Seiten zugreifen können.
Virtueller Addressraum als Schutz
Adressen die protected sind, werden in Page-Table nicht eingetragen, dadurch page-fault.
Protection Keys
Variante 1 key-pair für Prozess und Frame im Speicher
Bei Speicherzugriff müssen keys gleich sein
Variante 2 key-pair für Prozess und TLB
TLB ein key pro Eintrag
Jeder Prozess hat eine Menge von keys Registers
Bei Speicherzugriff müssen keys gleich sein