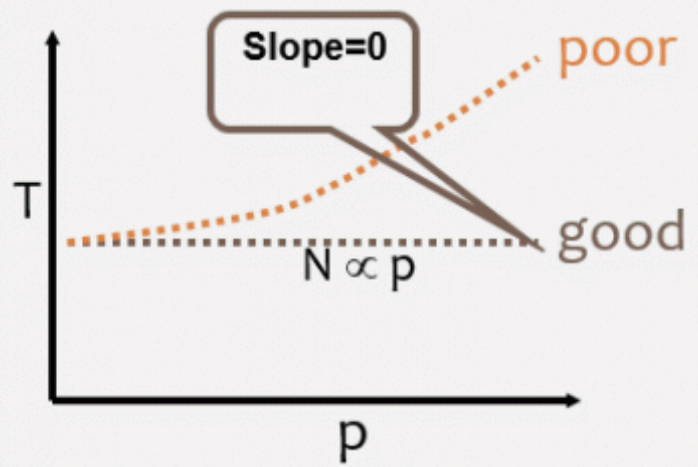
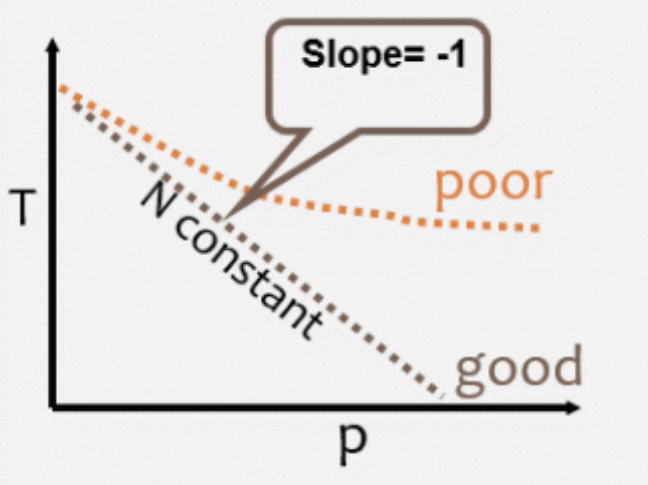
Implicitly there is an upper boundary of processors for which it does not make sense to add additional processors.
Sp(n)=c1⋅p
for some
c1<1
Sp(n)=c2⋅
p
for some
c2<1
Limit of absolute speedup
Linear speedup
Sp(n)∈O(p)
can not be exceeded.
Tseq(n)≤p⋅Tpar(p,n)
Perfect speed-up is rare and hardly achievable.
Sometimes we experimentally get super-linear speedup but its because of randomization, non determinism or because algorithms are not
comparable (also possible by using caches on multiple processors).
Proof through contradiction
Sequential simulation construction
(Wrongly) assume that we can simulate a parallel algorithm sequentially by:
executing one step of each process, for
C(n)
iterations
all steps of a single process until a communication/synchronization point, then the steps of the next process and so
on, ...
Proof through contradiction
Assume in
Tsim(n)
simulates
Tpar(p,n)
We know that:
p⋅Tpar(p,n)≥Tsim(n)
The simulation can not take more time than thanp⋅(max0≤i<pTi(n))
To assume that
Sp(n)>p
for some
n
:
Sp(n)=Tpar(p,n)Tseq(n)>p
impliesTseq(n)>p⋅Tpar(p,n)
impliesTseq(n)>p⋅Tpar(p,n)≥Tsim(n)(see above)
impliesTseq(n)>Tsim(n)
Contradiction:
Tseq(n)>Tsim(n)
would mean, that
Tseq(n)
is the best known/possible time.
Therefore:
Sp(n)=Tpar(p,n)Tseq(n)≤p
Tseq(n)≤p⋅Tpar(p,n)
Cost-optimal, Work-optimal
Cost-optimal parallel algorithm
C(n)=p⋅Tpar(p,n)∈O(Tseq(n))
has
linear speedup.
Proof
Cost-optimal algorithm with
p⋅Tpar(p,n)=c⋅Tseq(n)∈O(Tseq(n))
impliesTpar(p,n)=c⋅Tseq(n)/p
impliesSp(n)=Tseq(n)/Tpar(p,n)=p/c
The constant
c
stands for the load imbalances and overheads.
The smaller
c
is, the closer we are to the perfect speed-up.
Example 1
ForTseq(n)∈O(n)
anyTpar(p,n)∈O(n/p)is cost-optimal.
Proof:
Tpar(p,n)∈O(n/p)
impliesp⋅Tpar(p,n)∈p⋅O(n/p)
impliesp⋅Tpar(p,n)∈p⋅O(n/p)≤p⋅(c⋅n/p)=c⋅n∈O(n)
for some constant
c
impliesp⋅Tpar(p,n)∈O(n)
Example 2
ForTseq(n)∈O(n)
the parallel timeTpar(p,n)∈O(n/p)is not cost-optimal.
par (0<=i<n) b[i] = true; // set all to true
par (0<=i<n, 0<=j<n)
if (a[i] < a[j]) b[i] = false; // set those where a larger one exists to falsepar (0<=i<n)
if (b[i]) x = a[i];
Wpar(p,n)∈O(n2)
Tseq(n)=Wseq(n)∈O(n)(best known sequential algorithm)
Absolute speedup
Not work-optimal:
Wpar(n)∈/O(Tseq(n))
Sp(n)=Tseq(n)/Tpar(p,n)=O(n)/O(n2/p)=O(p/n)
Linear absolute speedup for fixed
n
.
Absolute speedup decreasing with
n
.
Break even
Number of processors for parallel algorithm to be faster than sequential algorithm:
Tpar(p,n)<Tseq(n)⇔n2/p<n⇔p>n
Tpar(p,n)<Tseq(n)⇔p>n
This is bad! We need as many processors as we the problem size.
Relative speedup
SRelp(n)=Tpar(1,n)/Tpar(p,n)=O(n2)/O(n2/p)=O(p)
Linear relative speedup.
Parallelism
T∞(n)=O(1)
T∞(n)Tpar(1,n)=O(n2)/O(1)=O(n2)
Great parallelism.
Conclusion: This (terrible) parallel algorithm has
linear relative speedup for
p
up to
n2
processors.
Overhead
Parallelization Overhead
= Work that does not have to be done by a sequential algorithm like cooridination (communication, synchronization) and redundant
computation.
When there is no overhead we can parallelize perfectly:
Tpar(p,n)=Tseq(n)/p
Each Processor has Task
Ti(n)
and Overhead
Oi(n)
in its work:
Wpar(p,n)=∑0≤i<pTi(n)+Oi(n)
Therefore
Tpar(1,n)≥Tseq(n)
Communication overhead model
Toverhead(p,ni)=α(p)+β⋅nifor processori:
α(p)
latency, dependent on
p
β⋅ni
cost per data item, that needs to be exchanged by processor
i
for synchronization operations it’sni=0
Cost-optimal
If cost-optimal
p⋅Tpar(p,n)=k⋅Tseq(n)
absolute speedup still is linear (but not perfect)
Sp(n)=
k
1⋅p
Load Balancing
Load imbalance
Differece betweeen max and min work+overhead.
∣max(Ti(n)+Oi(n))−min(Ti(n)+Oi(n))∣
Load balancing
Achieving an even amount of work for all processors
i,j
:
Tpar(i,n)≈Tpar(j,n)
Static, oblivious
Splitting problem in
p
pieces, regardless of the input
(except it’s size)
.
Static, problem dependent, adaptive
Splitting problem in
p
pieces, using the structure of the input.
Dynamic
Dynamically (during program execution) readjusting the work assigned to processors.
This means some overhead.
Amdahl’s law: Sequential bottleneck
When static, oblivious - load balancing:
A)Seq
perfectly parallelizable:
Tpar(p,n)∈O(Tseq(n)/p)
B)Seq
has a
fractions(n)
that can’t be parallelized
dependens onn
:
Tseq(n)=s(n)⋅Tseq(n)+(1−s(n))⋅Tseq(n)can be parallelized
Tpar(p,n)=s(n)⋅Tseq(n)+p1−s(n)⋅Tseq(n)
C)Seq
has a
fractions
that can’t be parallelized
constant and independent ofn
:
Tseq(n)=(s+r)⋅Tseq(n)
Tpar(p,n)≥s⋅Tseq(n)+pr⋅Tseq(n)
Max speedup gets very limited and the constant fraction becomes a “sequential overhead”.
Amdahl’s Law (parallel version): Sequential bottleneck / overhead
Let program of
Seq
contain two fractions, independent of
n
:
“perfectly parallelizable” fraction
r
“purely sequential” fraction
s=(1−r)(can’t be parallelized at all)
The maximum achievable speedup
(independent ofn)
:
Sp(n)=1/s
Proof
Tseq(n)=(s+r)⋅Tseq(n)
Tpar(p,n)=s⋅Tseq(n)+p
r
⋅Tseq(n)
Sp(n)=Tseq(n)/Tpar(n)=1/(s+r/p)
Sp(n)=1/(s+
r
/p)
limp→∞Sp(n)=1/s
We want to avoid Amdahl’s law at all cost.
I/O, initialization of global data structures, shared data structures, everything that takes
O(n)
time and work
Examples
Sequential algorithms that could be a constant fraction:
Example: I/O and problem splitting
Total time:
10ns
Processor 0: Read input for some computation
? ns
Split problem into
n/p
parts, send part
i
to a processor
i? ns
All processors
i
: solve part
9ns
All processors
i
: send partial solution back to processor 0
? ns
Constant sequential fraction in 3 out of 4 steps limits the speedup.
s=1−(9ns/10ns)=0.1
limp→∞Sp(n)=1/s=10
When measuring parallelism we therefore often dont measure the I/O and problem splitting part.
Example: malloc
// Sequential initialization
// O(1)
x = (int*)malloc(n*sizeof(int));
...// Parallelizable part
do {
for (i=0; i<n; i++) {
x[i] = f(i);
}// check for convergence
done = …;} while (!done)
K
iterations before convergence.
Assumptions: convergence check and
f(i)∈O(1)
Tseq(n)=1+
K
sequential part+
K
⋅nfor-loop
Tpar(p,n)=1+K+K⋅n/p
Sequential fraction:
s=(1−r)=1−(1+
K
+
K
⋅n/p
K
⋅n)≈1/(1+n)
Speedup:
limp→∞,
n
>
p
,
n
→∞Sp(n)=1/s=∞p
sincepis our upper boundary
👉
A constant sequential part (not a constant fraction), does not limit the speedup
Example: calloc
// Sequential initialization
// O(n)
x = (int*)calloc(n*sizeof(int));
...// Parallelizable part
do {
for (i=0; i<n; i++) {
x[i] = f(i);
}// check for convergence
done = …;} while (!done)
K
iterations before convergence.
Assumptions: convergence check and
f(i)∈O(1)
Tseq(n)=
n
+
K
sequential part+
K
⋅nfor-loop
Tpar(p,n)=n+K+K⋅n/p
Sequential fraction:
s=(1−r)=1−(n+
K
+
K
⋅n/p
K
⋅n)≈1/(1+K)
Speedup:
limp→∞Sp(n)=1/s=1+K
👉
A sequential part that is a constant fraction (dependent on
n
) limits the speedup
Scaled speedup
Strictly non-parallelizable usually depends on
nas ins(n)
and
decreases
with rising
n
.
Scaled speedup
Let program of
Seq
contain two fractions dependent on
n
:
“perfectly parallelizable” fraction
T(n)
“purely sequential” fraction
t(n)=(1−T(n))
This part decreases with rising
n
.
limn→∞t(n)=0
We can therefore reach linear speedup through increasing
n
and the fastert(n)/T(n)converges, the faster the speed-up converges.
t(n)should increase more slowly withnthanT(n).
We get
Tseq(n)=t(n)+T(n)
Tpar(p,n)=t(n)+T(n)/p
limn→∞Sp(n)=p
Proof
We know that
limn→∞t(n)=0
limn→∞
T
(n)t(n)=0
Therefore
Sp(n)=Tpar(p,n)Tseq(n)=t(n)+
T
(n)/pt(n)+
T
(n)=t(n)/
T
(n)+1/pt(n)/
T
(n)+1
limn→∞Sp(n)=0+1/p0+1=1/p1=p
limn→∞Sp(n)=p
If the speedup is not linear
Tpar(p,n)=t(n)+T(n)/f(p)
with
f(p)<p
using
t(n,p)
instead of
t(n)
Assuming that the parallel algorithm is work optimal we can allow the non-parallelizable part to depend on
p
: