Merging
Definition
Problem
data dependent, adaptive, load balancing - problem
Input:
Array of size , Array of size
both are sorted -for all
Output:
Array of size containing every single element from
sorted -for all
Theorem
on “shared memory system” we can achieve parallel time:
(Convenient to assume “shared-memory programming model” → in “distributed memory programming model” we would need communication and data redistribution)
Distinctness
Sometimes useful to assume that all elements are distinct.
Assumption does not reduce generalizability: We can make elements distrinct through lexicographical ordering of pairs :
If and then:
This means, when they are equal, the index decides which one is considered larger
Disadvantage: more memory usage
Stable merge
When original index-order of equal input-elements is preserved in output array.
Stability sometimes desirable ie. Radix sort
Strictly sequential solution
this is not the best known solution
read and write operations in total
i = 0; j = 0; k = 0;// pick smaller elem from both arrays
while (i<n && j<m) {
C[k++] = (A[i]<=B[j]) ? A[i++] : B[j++];
}// fill up the rest, if one array is already eliminated
while (i<n) C[k++] = A[i++];
while (j<m) C[k++] = B[j++];Merging by Ranking
= number of elements in that are smaller than
Can be done sequentually in ordered arrays with binary search
written in
written in
rank(A[pos], B)
can be understood as the index of the first element in
B
that is bigger than
A[pos]Barrier pattern
Synchronization pattern
Explicit synchronization through barrier
At barrier the processor can’t continue until others have also reached that point.
Solution 1)
Solution 1)
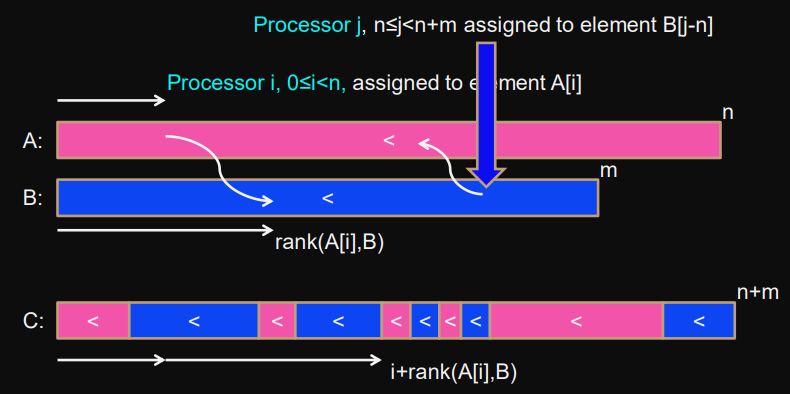
Explicit paralelization: We tell each processor what to do
One processor per element:
Processor assigned to
Processor assigned to
par (0 <= i < n+m) {
if (i < n) {
// Array A
C[i+rank(A[i],B)] = A[i];} else if (i < n+m) {
// Array B
j = i-n;
C[j+rank(B[j],A)] = B[j];
}barrier; // synchronization construct so that any C[k] can be accessed
}The algorithm is not efficient:
Exponential improvement in time with linear number of processors
Not work-optimal
Speedup is bad. It decreases with with .
Normally
Solution 2)
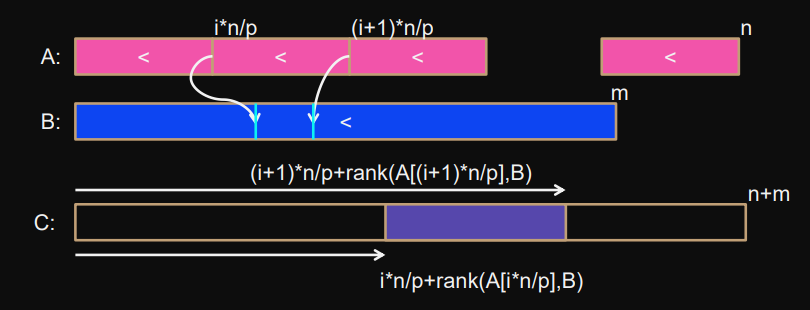
Solution 2)
Divide into blocks of , then rank the start and end of each block.
We find the matching block in for each block in .
Number of processors does not depend on Input.
Assumesis divisible by(can be fixed if not the case).
We then merge blocks of sequentially.
andare sequential algorithms.
par (0 <= i < p) {
pos = i*(n/p);
nextPos = (i+1)*n/p;// sequential merge
merge (
// & → Address of ...
&A[pos], // interval start in A
n/p, // n (interval size in A)
&B[rank(A[pos],B)], // interval start in B
rank(A[nextPos],B) - rank(A[pos],B), // m (interval size in B)
&C[pos + rank(A[pos],B)] // interval start in C
);
barrier;
}
There can be severe load imbalance where one processor does all the work, because the intervall in gets mapped to a huge chunk in .
Work-optimal for
Solution 3a)
Solution 3a)
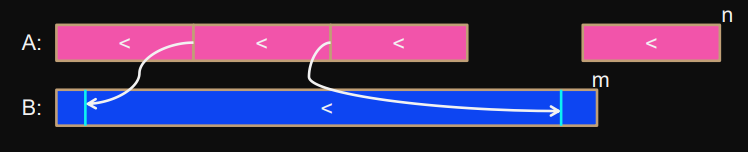
Divide into blocks of , then rank the start and end of each block.
Differentiate between good and bad segments in :
good segments :rank(A[nextPos],B)-rank(A[pos],B)≤ m/p
balanced pairs
Do sequential merge
bad segments :rank(A[nextPos],B)-rank(A[pos],B)> m/p
unbalanced pairs → divide intervall in into smaller blocks and find their partner-block in (means also splittingup) .
This way wereassignprocessors to the start-indices of the blocks which is problematic.
In case there is more than one bad segment we use prefix-sums (see below).
This way there are at most smaller merge-pairs all of size

Solution 3b)
Solution 3b)
Divide into blocks of
Divide into blocks of
This gives independent merge-pairs all of size
Experience shows that the pairs are usually independent from eachother (but we could potentially do twice the work).

Merging by Co-ranking
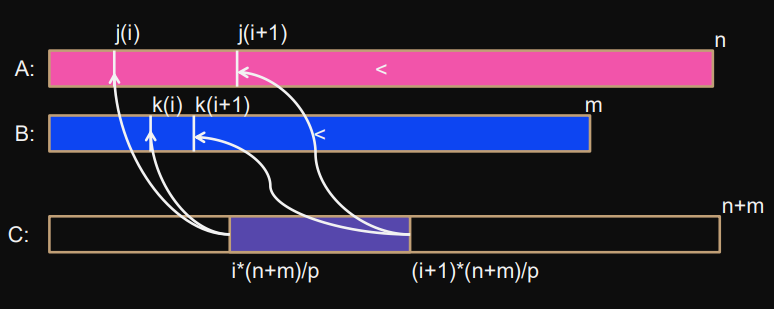
Co-Ranks
j(i), k(i)
are the co-ranks of segment
i
A[j(i), j(i+1)-1]
and
B[k(i),k(i+1)-1]— merged —→C[i*(n+m)/p, (i+1)*(n+m)/p-1]
They satisfy:
j(i) + k(i) = i*(n+m)/p
A
,
B
from which the merging of segment
i(with indexi*(n+m)/p)
starts.
Example
A[j(i), j(i+1)-1]andB[k(i),k(i+1)-1]— merged —→C[i*(n+m)/p, (i+1)*(n+m)/p-1]A [0, 2, 4, 6] B [1, 3, 5, 7] \___/ \___/ 0 1 <- segments (for each processor)C [0, 1, 2, 3, 4, 5, 6, 7] \_________/ \_________/ 0 1 <- segments (for each processor)Lets say we have 2 processors
p = 2and each of them gets a segment ofC:n = 4,m = 4→ Length of each segment:(n+m)/p = 4We calculate the beginning and end of the segment dedicated to each processor:
p_0dedicated to segmenti=0:C[0*(n+m)/p; 1*(n+m)/p-1] =C[0;3]p_1dedicated to segmenti=1:C[1*(n+m)/p; 2*(n+m)/p-1] =C[4;7]We want to find the pair-segments from
A, Bthat will be merged into our segment inC:🪄 magic calculation
For
i = 0j(0) = 0k(0) = 0Check of invariant:
j(0) + k(0) = 0*(n+m)/p = 0For
i = 1j(1) = 2k(1) = 2Check of invariant:
j(1) + k(1) = 1*(n+m)/p = 4For
i = 2j(2) = 4k(2) = 4Check of invariant:
j(2) + k(2) = 2*(n+m)/p = 8Now we know:
i = 0→C[0;3]is merged fromA[j(0); j(0+1)-1]andB[k(0); k(0+1)-1]A[0; 1]andB[0; 1]i = 1→C[4;7]is merged fromA[j(1); j(1+1)-1]andB[k(1); k(1+1)-1]A[2; 3]andB[2; 3]
Co-Rank Lemma
Let
i
be a shorthand for:
(i)*(n+m)/p(same applies for co-ranksj,k)
Let
(i)-1
be a shorthand for:
(i)*(n+m)/p-1
Let
i-1
be a shorthand for:
(i-1)*(n+m)/p(same applies for co-ranksj-1,k-1)
For any
i
in
0 ≤ i < n+m
there are unique
j
,
k
such that:
j + k = i
-
Either
k = 0orA[(j)-1] ≤ B[k]
-
Either
j = 0orB[(k)-1] < A[j]
merge(A[0,…,(j)-1], B[0,…,(k)-1]) = C[0,…,i-1]
Proof of lemma
- Invariant
j + k = i
- Transivity
C[(i')-1] ≤ C[(i)-1] ≤ C[(i'')-1]for anyi',i''withi' < i < i''Because of
A[j-1; (j)-1] ∈ C[0; (i)-1]B[k-1; (k)-1] ∈ C[0; (i)-1]more precisely:
∈ C[i-1; (i)-1]
A[j], B[k] ∉ C[0; (i)-1]
The last element
C[(i)-1]must either be fromAorB:-
If
Agets chosen:C[(i)-1] = A[(j)-1]A[(j)-1] ≤ B[k]or else an element fromBwould have been chosen.B[(k)-1] < A[(j)-1] ≤ A[j]B[(k)-1] < A[j]
-
If
Bgets chosen:C[(i)-1] = B[(k)-1]B[(k)-1] < A[j]or else an element fromAwould have been chosen.Same as above:
A[(j)-1] ≤ B[k]
- Invariant
Co-Rank Algorithm
Very similar to binary search.
j = min(i,n);
k = i-j;
jlow = max(0,i-m);done = 0;
do {
// case 1: j is too large
if (j>0 && k<m && A[j-1]>B[k]) {
d = (1+j-jlow)/2;
klow = k;
j -= d;
k += d;
// case 2: k is too large
} else if (k>0 && j<n && B[k-1]>=A[j]) {
d = (1+k-klow)/2;
jlow = j;
k -= d;
j += d;
} else {
done = 1;
}
} while (!done)-
First assume
Cis made out of only elements fromAfirst:j = min(i, n)k = i-j
-
If
A[(j)-1] > B[k]then
jwas too large → we should have chosen element fromBnow halve
jand increasek→ we needjlowfor thisj=(j-jlow)/2klow= old value ofk
-
If
B[(k)-1] ≥ A[j]then
kwas too large → we should have chosen element fromAnow halve
kand increasej→ we needklowfor thisk = (k-klow)/2jlow= old value ofj
Iterate times until lemma is satisfied
Solution 4)
Solution 4)
Each processor handles a segment of of the same size.
Perfectly load-balanced, stable.
Divide of size into blocks of size .
This means
i ∈ [0; p-1]
The start index of block is
i*(n+m)/p
For each block :
-
Determine its co-ranks
j(i), k(i)and store intocoj[i], cok[i].
-
Merge the blocks
A[j(i); j(i+1)-1]andB[k(i); k(i+1)-1]intoC[i*(n+m)/p; (i+1)*(n+m)/p-1]
par (0 <= i < p) {
// 1) get coranks
// coj[]: array of j-coranks
// cok[]: array of k-coranks
corank(i*(n+m)/p, A, n, &coj[i], B, m, &cok[i]);
barrier; // processor i will need coranks of i+1
// 2) merge (sequentially)
merge(
&A[coj[i]], // interval start in A
coj[i+1] - coj[i], // n (interval size in A)
&B[cok[i]], // interval start in B
cok[i+1] - cok[i], // m (interval size in B)
&C[i*(n+m)/p] // interval start in C
);barrier;
}
which is when .
Work optimal
We can also get rid of the first synchronization
barrier
It is necessary because process requires co-ranks of process .
implementation
Cost: Redundant computation of coranks, more memory
par (0 <= i < p) { // 1) get coranks -> not arrays but variables j1, j2, k1, k2 corank(i*(n+m)/p, A, n, &j1, B, m, &k1); corank((i+1)*(n+m)/p, A, n, &j2, B, m, &k2); // compute again // 2) merge (sequentially) merge( &A[j1], // interval start in A j2 - j1, // n (interval size in A) &B[k1], // interval start in B k2 - k1, // m (interval size in B) &C[i*(n+m)/p] // interval start in C );barrier; // not needed anymore }