Models
Architecture models
Algorithm inmodelImplementation asprogramExecution of it in concretearchitecture
Computational model / Architecture model / Machine model
Theoretical construct for designing and analyzing algorithms.
formally describes
- components of the processor (memory, communication, synchronization)
- how they execute programs
- at what costs (serves as execution-cost-model)
Bridging models
introduced as Valiant’s Bulk Synchronous Parallel BSP-Model.
should have enough resemblence to actual machines that the algorithms implemented with the model can be used to predict the performance to some extent.
Minimal requirements
If algorithm performs better than in the model,
then the implementation should also do so too on the applicable hardware.
Model gap
sequential computing
There are many bridging models, ie. RAM.
Predicted performance corresponds to real performance to some degree.
parallel computing
No single, agreed upon model.
Performance portability problem: No good “bridging” properties of models for the many paradigms, languages, architectures → we have to design, analyze, benchmark the parallel algorithms instead.
RAM model
RAM
= random access memory / von Neumann architecture.
standard sequential model - but there are alternatives (ie. turing machine)
Wrong asssumption in RAM
= ALU instructions and memory access take the same time.
In reality, memory access time is much slower (= von Neumann Bottleneck) .
We try to overcome it through the use of caches but they are complex.
PRAM model
PRAM
= parallel random access memory
a parallel computer-memory architecture model
Processors operate under the same clock (lock-step) : they all perform one instruction per clock tick
Wrong assumption in PRAM
= ALU instructions and memory access take the same time.
Even more inaccurate than in RAM because of multiple processors etc. (= Aggrevated von Neumann Bottleneck) .
We try to overcome it by increasing the memory bandwidth through prefetching in banked / non-monolithmemory for parallel instructions / vector operations.
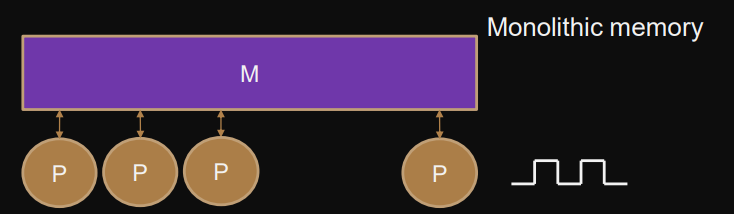
UMA
= Uniform memory access
Access time to memory does not depend on processor-location.
Monolithic shared memory
Synchronous, lock-step
Communication/coordination through shared memory
Using multiple ports, memory network
ie. RAM, PRAM
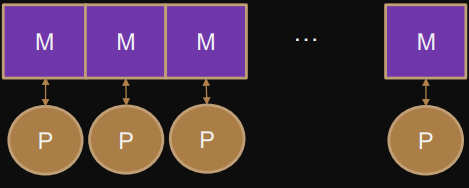
NUMA
= Non-Uniform memory access
Access time to memory depends on processor-location.
Non-monolithic / banked shared memory
Asynchronous, no lock-step, no common lock
Synchronization through atomic operations and barriers.
Memory-network
ie. almost all real processors
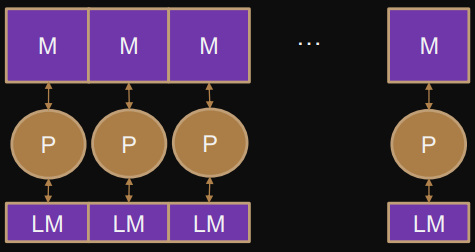
NUMA with local memory
Some memory locations are closer to processor (faster access) than others
Local memory is not shared - only accessible by the processor to which it belongs
Distributed memory
Local memory + memory distributed over processors via network
Needs explicit communication

PRAM conflict resolution
What happens if several processors in the same time-step access the same memory location in the PRAM model?
EREW PRAM ❌ reading exclusive ❌ writing exclusive
CREW PRAM ✔️ reading concurrent ❌ writing exclusive
CRCW PRAM ✔️ reading concurrent ✔️ writing concurrent
When exclusive it’s the algorithm designer’s responsibility to prevent it and not the hardware’s.
CRCW PRAM has 3 theoretical write-conflict resolutions:
common conflicting processors must write same value
arbitrary one random write succeeds
priority a priority-scheme decides which write succeeds
Flynn’s taxonomy
Classifies instruction streams and data streams in computing systems.
Classifies architectures by:
Instructions carried out simultaniously
Data / words accessed simultaniously
SSID - single instruction, single data
single processor operates on single data per instruction
ie. sequential architecture like RAM
SIMD - single instruction, multiple data
single processor operates on multiple data per instruction
ie. traditional vector processor, SIMD-extensions, some GPUs
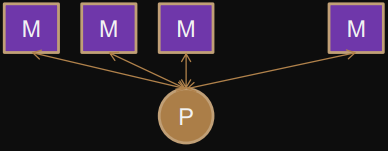
MISD - multiple instruction, single data
multiple processors and operate on a single stream of data
ie. some say there are none, some say pipelined architectures
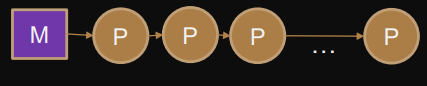
MIMD - multiple instruction, multiple data
multiple processors operate on multiple per instruction
ie. PRAM, distributed memory architecture
Parallel programming models
Parallel programming models
= Programming paradigms and interfaces, libraries
- parallel resources (processes, threads, tasks, ...) and granularity of parallelism
- memory (shared, distributed, hybrid)
- methods of synchronization and communication
All given programming models can be realized by any architecture but a better fit is more efficient.
Using Flynn’s taxonomy for programming models
SIMD: one instruction operates on many different elements
MIMD: different processes can execute different programs
SPMD: same program operates on multiple data (is a subcase of MIMD)
All code in this lecture will be SPMD
All processes must execute the same program but they can execute diffrent parts of the same program at the same time.