Work as a DAG
Work
Work to solve problemwith input of size :
can be described as set of smaller tasks
executed in some order, constrained by dependencies.
Work
total number of executed instructions
or by all processors (not including idle / waiting times)
If this isnotthe case there must be a better algorithm than→ contradiction.
Work optimality
Should be the case here.
Fastest running time / fastest possible parallel
= smallest possible running-time of with arbitrarily many processors
= smallest number of parallel steps in which work can be done is
Work-time relationship of parallel algorithms
Work should be work-optimal
Assuming that load balanced and work assigned evenly to processors:
Work as DAG (Directed Acyclic Graph)
Computation can be structured as tree / directed acyclic graph DAG.
Example: Quicksort
void QuickSort(int x[], int n) { if (n<=1) return;pivot = pivot(x,n); // x[pivot] as pivot value ix = partition(x,n,pivot); // partition, return new pivot index QuickSort(x,ix); // sort elements until pivot QuickSort(x+ix+1,n-1-ix); // sort elements after pivot }pivot(n)partition(n)partition into elements smaller, equal, larger than pivot in Recursion depth in best case .
Total work .
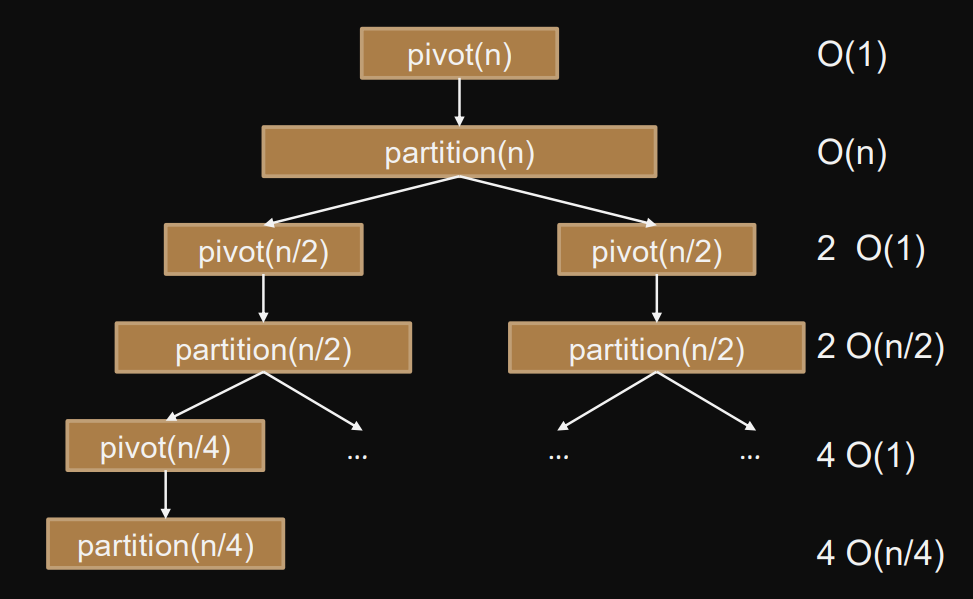 💡Every single node must be executed in order for problem to be solved (not just a path from root to leaf)
💡Every single node must be executed in order for problem to be solved (not just a path from root to leaf)
Task
a sequential computation (strand)
requires input data (from other tasks) - or else can not be executed
produces output data (to other tasks)
Work as DAG
Work shown with directed acyclic graph
vertices, task set
root called start node
leaf called final node
nodes without ancestors called ready nodes
data dependencies
means that can’t be executed before has completed (dependency).
transfering output of one task to the input of another called communication cost .
is dependent from if there is a path from to .
Node task / strand / work package
Input nodes no incoming edges
Output nodes no outgoing edges
Dependence when path between two tasks
Parallel execution Tasks scheduled to processors with respect to dependencies
or Time for processors with given schedule
Work of : number of sequential operations
total work, sum of nodes (ignoring communication costs)
Depth / Span / Fastest possible parallel
Execution with unlimited number of processors.
Number of operation in heaviest path from input to output node:
in a good DAG, it shouldn’t be a constant fraction of
Therefore:
Lower bounds
Work law
Depth law
Max speedup- also called paralellism
Independence
when there is no path from to and vice versa.
can be executed in parallel.
Execution (= topological order)
Repeat until all tasks are executed:
- Pick a task that is ready (no incoming edges / dependencies)
- Execute task by some processor
-
Remove edges to all its children (successor tasks become available “ready nodes”)
“Ready nodes” can be executed on available processors.
- Remove task
Best possible execution time
therefore
DAG Design guidelines
“work-depth analysis” gives more informative upper-bounds on speedups than naive Amdahls’ law:
-
Look at “critical path” instead of just “sequential fraction”.
Design for light critical path compared to total work .
-
Find ways to specify good DAGs by:
using small
-
Find efficient way to schedule DAG nodes:
num of parallel steps
Scheduling Work-DAGs
Scheduling
= Finding ready task to assign to a processor at start time .
respect dependencies don’t start tasks predecessors have been completed
respect processors only assign one task to a processor at a time
Scheduling problem (NP-Hard)
finding the optimal schedule for some optimization criteria
ie. minimum completion time of last task
Scheduling on a single processor
Execute in topological order
Special cases
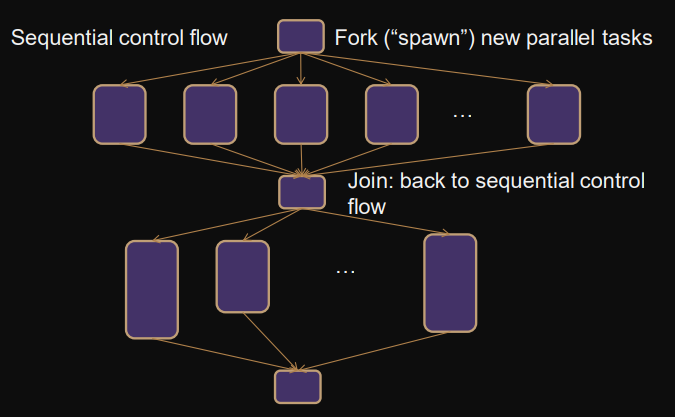
Fork-join parallelism (OpenMP programming model)
sequential control flow
fork spawning new parallel tasks
join joining back to sequential control flow
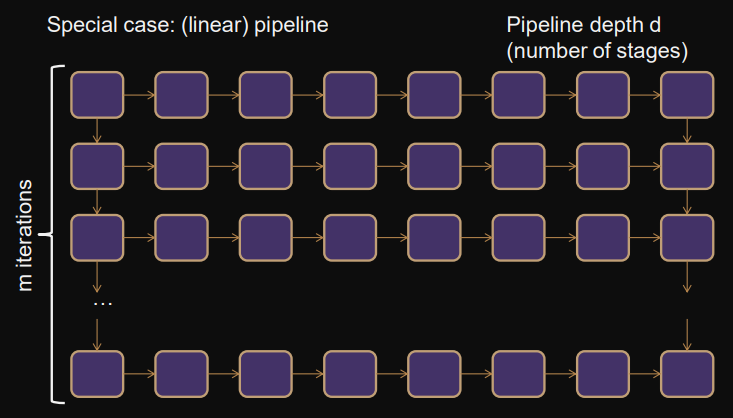
Linear pipeline
pipeline depth (number of stages)
iterations
Greedy DAG scheduling
Greedy DAG scheduler
Goal = Assigning as many tasks as possible to available processors.
“Complete step” = at least tasks are ready or being executed (otherwise called incomplete ).
Theorem
Greedy DAG scheduler executes with work and depth in:
time steps
Based on the other laws:
- Work law:
- Depth law:
Achieved is therefore usually within a factor of from the optimal schedule (with minimal time as optimization criteria).