pthreads
Definition
Process
Program in execution
Thread
Used for thread parallel programming.
Smallest independent stream of instructions that can be scheduled by OS.
Each contain local variable stack, registers, thread local storage.
If scheduled by OS, then OS thread = lives inside an OS-process and shares global information (file pointers, global variables, static variables, heap storage).
POSIX threads, pthreads
POSIX = Portable Operating System Interface for uniX
Low level interface for thread programming in C/Unix
Have no cost model, no memory model, ...
Programming model
(p)threads programming model
-
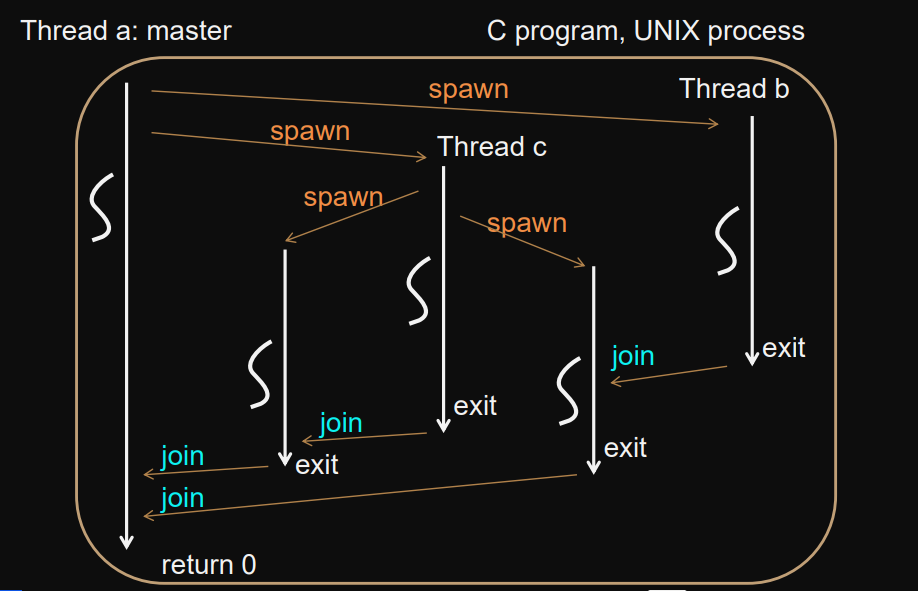
Fork-join parallelism
A thread can spawn (start) any number of new threads and wait for them to terminate.
-
Master thread
There is initially only one active main thread.
Code for threads are functions. All threads execute within the same program (SPMD) but can be different functions.
-
Peer threads
A thread can wait for another “peer thread” to terminate.
-
Parallelism
Threads are scheduled by the underlying system and may or may not run simultaneously on different processors.
-
Synchronization between threads
There is no implicit synchronization between threasd - the progress independently and asynchronously.
- Threads share process global data
-
Coordination mechanisms
for protecting access to shared variables (locks, condition variables).
All concurrent updates must be protected otherwise: illegal program with undefined outcome.
-
Pragmatics for parallel computing
Threads get scheduled and bound specified cores (non-standard).
Symmetric Multi-Processor SMP
- Single OS
- all cores treated equally
- threads not bound to cores
- there can be more threads than cores
Explicit parallelization of data parallel loop
Increased performance by spawning threads recursively instead of using loops.
start = rank*n/p
end = (rank+1)*n/pfor (i=start; i<end; i++) {
a[i] = f(i);
}rank
is the virtual thread id and is set by the spawning thread.
implementation (in depth)
Using the argument struct
typedef struct { int *array; int n; int rank; int size; } array_t;loopblock(void *what) { array_t *ix = (array_t*)what; int *a = ix->array; int i; int n = ix->n; int p = ix->size; // no. of threads int start = ix->rank*(n/p); int end = start+n/p; for (i=start; i<end; i++) { a[i] = f(i); } }
example: matrix-vector product
Sequential solution
for (i=0; i<n; i++) { y[i] = 0; for (j=0; j<m; j++) { y[i] += x[i][j]*A[j]; } }Parallel solution
using cache ineffectively
Thread with
idrank rank handles everyp‘th index of matrixxfor (i=rank; i<n; i+=p) { y[i] = 0; for (j=0;j<m; j++) { y[i] += x[i][j]*A[j]; } }
But this way we use the cache ineffectively and each thread writes and reads into
yat the same time.
for (i=rank*n/p; i<(rank+1)*n/p; i++) { y[i] = 0; for (j=0;j<m; j++) { y[i] += x[i][j]*a[j]; } }
Synchronization
Synchronization / coordination constructs (from concurrent computing) prevent malicious non-determinism (ie. race conditions).
Allow solving algorithms under weak memory consistency assumptions.
Race condition
Outcome of parallel program execution depends on the relative timing of the updates by processors/threads (in an undesired way).
Data race
Several threads (or cores, processes, …) compete for updating a shared variable.
Outcome depends on relative timing.
Deadlock
Two or more threads in situation where they depend on eachother and can’t progress.
Deadlocks spread to all threads and eventually the program can not terminate.
example
pthread_mutex_t lock1 = PTHREAD_MUTEX_INITIALIZER; pthread_mutex_t lock2 = PTHREAD_MUTEX_INITIALIZER;… pthread_mutex_lock(&lock1); pthread_mutex_lock(&lock2); …… pthread_mutex_lock(&lock2); pthread_mutex_lock(&lock1); …
Shared resources
Simple variables, data structures, devices, ... accessible by multiple threads
Critical section
The manipulated shared resources by code, are not allowed to be manipulated by other entities (threads, processes, ...) concurrently.
Mutual exclusion property
There is at most one thread in critical section at any fiven time.
Safety
pthreads memory model for “safe” programs
Thread not allowed to update variables outside of critical sections.
(Lock constructs used to ensure consistent memory views)
Thread safe functions
Function can be executed concurrently by any number of threads and will always produce the correct result.
Non-thread safe functions have side effects
- Don’t protect (write access) to shared (ie. static) variables
- Keep a state over successive invocations
- Return pointers to static variables
-
call thread-unsafe functions
these unsafe functions can also be system functions:
ie.
rand(),random()keep internal state in static variablessolution: using
random_r()with an explicit state, locking, ...problem: serialization can lead to slowdown, deadlocks, ...
Example: concurrent read and thread-safety
Where
xis the input.a = f(x);b = f(x);c = f(y);Conclusion: There is a concurrent read of
x.This program is only safe for concurrent execution, if
fhas no side effects (is thread safe ).
Wait free vs. lock free
Wait-freedom lock-freedom
(but lock-freedomwait-freedom)
Both require hardware support (ie. atomic counter).
Wait freealgorithm on concurrent data
Each thread can always do progress no matter what other threads are doing.
If thread tries to execute the operation, progress is guaranteed and does not depend on other threads or their attempt to execute the same operation.
Lock freealgorithm on concurrent data
If several threads are attempting to execute the operation, at least one of the threads can make progress on the operation.
Synchronization constructs
Slow implementation
These constructs were developed for small numbers of concurrent tasks, not scalable HPC (many threads on many cores).
Most of them have sequential parts that slow down (Amdahl).
Locks
Locks
= shared object between threads, guarantee mutual exclusion
called “mutex” in pthreads
States of locks
2 possible states:
- acquired (locked)
- released (unlocked)
Only one thread can acquire lock and must release it after use.
If another thread tries to acquire the locked lock, it is blocked and must wait until its release.
Properties of locks
Deadlock freedom Some thread will always succeed in acquiring the lock
Starvation freedom If a thread is trying to acquire the lock it will eventually succeed
Fairness First come first serve: thread that acquired first will get the lock first
Bounded waiting Bounded time / steps after which a thread must succeed in
acquiring the lock it is trying to acquire.
By definition, locks are not lock-free, not wait-free.
A thread that acquired the lock can keep it indefinitely while no other thread makes progress.
pthreads rule
Whatever thread can view in memory when releasing the lock,
thread can view when acquiring the lock.
Properties of pthread locks
Not fair, not starvation free, no bounded waiting - pthread locks are deadlock free but not starvation free.
Threads can starve eachother by never allowing the others to enter the critical section.
There is no guarantee that a thread will eventually acquire the lock it wants.
Lock pattern
flag = 1; x = … ;lock(&lock);
if (flag) {
a = x;
flag = 0;
}
unlock(&lock);lock(&lock);
if (flag) {
a = x;
flag = 0;
}
unlock(&lock);lock(&lock);
if (flag) {
a = x;
flag = 0;
}
unlock(&lock);Example: using locks
unsafe program: race condition
initial value:
x = 0;if (flag) { a = x; flag = 0; }if (flag) { a = x; flag = 0; }flag = 1; x = 27;Conclusion: race condition - What happens depends on relative timing.
-
Either
ais some unintended value ofx(before it was initialized) or 27.
- Both threads might enter critical secion
-
Either
safe program (implements pattern)
what is the intended value of
afor thread0, thread1?pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER; x = 0;lock(&lock); if (flag) { a = x; flag = 0; } unlock(&lock);lock(&lock); if (flag) { a = x; flag = 0; } unlock(&lock);lock(&lock); flag = 1; x = 27; unlock(&lock);Conclusion:
Both read and write accesses to
xnow protected by lock (mutex).Mutual exclusion, consistent memory ensured by locking.
unsafe program: deadlock
what is the intended value of
afor thread0, thread1?pthread_mutex_t lock1 = PTHREAD_MUTEX_INITIALIZER; pthread_mutex_t lock2 = PTHREAD_MUTEX_INITIALIZER; x = 0;lock(&lock1); // executed lock(&lock2); // <-- needs unlock of lock2 from thread1 to progress if (…) unlock(&lock2); unlock(&lock1);lock(&lock2); // executed lock(&lock1); // <-- needs unlock of lock1 from thread0 to progress if (…) unlock(&lock1); unlock(&lock2);lock(&lock1); flag = 1; x = 27; unlock(&lock1);Conclusion: Deadlock
Deadlock occurs if thread0 and thread1 try to progress “simultaniously” by each alternately executing one instruction
Example: using global locks
List procesing: locking entire list
delete(e)operation:lock(listlock)
-
scan sequentially until element
eis found
-
dereference / free
efrom list via its predecessor
unlock(listlock)
This is inefficient: Thread using list blocks all other threads forsteps for list of size.
List procesing: locking each element individually
insert(e)operation:We want to insert element
ebetweene1ande2.We will need to lock
e1ande2for this.delete(e)operation:We want to delete element
ebetweene1ande2.We will need to lock
e1ande2for this.This is solution is expensive (needs a lot of space).
Deadlocks can still occur - We don’t know how the code for every thread is written → locks are not composable.
Assume the operations are written by 2 different programmers.
-
Insert: first lock
e1, thene2
-
Delete: first lock
e2, thene1
Then by executing them both a deadlock occurs
-
Insert: first lock
Example: using read/write locks
Reading arbitrary value
pthread_rwlock_t lock = PTHREAD_RWLOCK_INITIALIZER; flag = false;rdlock(&lock); if (flag) { a = x; } unlock(&lock);rdlock(&lock); if (flag) { b = x; } unlock(&lock);wrlock(&lock); x = c; flag = true; unlock(&lock);Conclusion
Thread0, thread1 can both enter their critical section simultaneously (read lock).
Thread2 is always alone in its critical section (write lock).
Therefore the thread0, thread1 either read the old
xvalue (== 0) or new value set by thread2.
Reading newly assigned value (deadlock possible) → can be solved with condiction variables
pthread_rwlock_t lock = PTHREAD_RWLOCK_INITIALIZER; flag = false;rdlock(&lock); while(!flag) {} a = x; unlock(&lock);rdlock(&lock); while (!flag) {} b = x; unlock(&lock);wrlock(&lock); x = c; flag = true; unlock(&lock);Same as above but threads wait until condition is met before continuing (because of the while loop).
Problem
Active wait is inefficient.
Deadlock is possible.
Solution
Condition variables
Using locks to avoid deadlocks
The best solution is avoiding locks altogether by replicating shared information.
- Use one lock at a time
-
If not possible: always acquire and release in the same order
(this is difficult to do with libraries, because we don’t know how they are implemented)
Can be done by assigning a level to each lock, sorting them via their IDs, using “trylocks” (if a lock can’t be aquired, release all locks, wait, try again)
Condition variables
See above for use-case example
Condition variables / Monitor
Allows thread to temporarily release lock and wait (suspend) for condition-signal with a condition variable .
Different from semaphore object (which is not part of standard pthreads)
Waiting for signal inside critical section on condition variable:
- Thread acquires lock and enters critical section.
- Thread suspends itself, relinquishes (temporarily releases) lock but stays suspended - and waits in critical section until the condition is met.
-
Thread is resumed (woken up) later by a signal from some other signaling thread.
It has again acquired the lock.
Mutual exclusion
Mutual exclusion still guaranteed.
Suspended thread is only resumed when signaling thread left critical section.
Risk of deadlock
if threads mutually wait on some condition but there are no signal-threads.
weird bug in pthreads
There can be unwanted wakeups by signals from the runtime-system without explicit wakeup from other thread.
Good practice: rechecking whether wait-condition is fulfilled - even after waking up.
Standard pattern
Thread waiting for condition (signalled thread)
lock(&lock);
// critical section ::while (!condition()) {
pthread_cond_wait(&cond, &lock); // wait and release lock temporarily
}
// thread has been signaled, condition holds, lock is acquired again// :: critical section
unlock(&lock);Thread broadcasting signal (signaling thread) — can be done inside or outside the critical section
Inside
lock(&lock); // critical section ::... // establishing condition cond_signal(&cond); // signal if condition holds// :: critical section unlock(&lock);- Advantage: Establishing condition in critical section → therefore it should hold when suspended thread is resumed.
- Disadvantage: Suspended thread will block on mutex again - until signaling thread leaves the section.
Outside
lock(&lock); ... // establishing condition (in critical section) unlock(&lock);cond_signal(&cond); // signal- Advantage: Suspended thread can immediately continue without blocking.
Example
Readers-writers lock (with condition variables and locks) → unfair
typedef struct { int readers; // actice readers int writer; // (boolean) active writer int waiting; // pending writes (writers in queue) pthread_cond_t read_ok; // condition: reading allowed pthread_cond_t write_ok; // condition: writing allowed pthread_mutex_t gateway; // lock} rwlock_t;void rwlock_rlock(rwlock_t *rwlock) { pthread_mutex_lock(&rwlock->gateway); // acquire gateway lockwhile (rwlock->waiting > 0 || rwlock->writer) { // writers exist or wait - release gateway lock and wait for read_ok signal pthread_cond_wait(rwlock->read_ok, &rwlock->gateway); }rwlock->readers++; // increment readers pthread_mutex_unlock(&rwlock->gateway); // release gateway lock }void rwlock_wlock(rwlock_t *rwlock) { pthread_mutex_lock(&rwlock->gateway); // acquire gateway lock rwlock->waiting++; // pending write while (rwlock->readers > 0 || rwlock->writer ) { // readers, writers exist - release gateway lock and wait for read_ok signal pthread_cond_wait(&rwlock->writer_ok, &rwlock->gateway); } rwlock->waiting--; // remove writer from queue rwlock->writer = 1; // active writer == true pthread_mutex_unlock(&rwlock->gateway); // release gateway lock }void rwlock_unlock(rwlock_t *rwlock) { pthread_mutex_lock(&rwlock->gateway); // acquire gateway lock// remove active writer or reader if (rwlock->writer) { rwlock->writer = 0; } else { rwlock->readers--; }// send signal: resume threads waiting to acquire if (rwlock->readers == 0 && rwlock->waiting > 0) { pthread_cond_signal(&rwlock->writer_ok); // no readers, waiting writer } else { pthread_cond_broadcast(&rwlock->reader_ok); // reader || no waiting writer }pthread_mutex_unlock(&rwlock->gateway); // release gateway lock }The signal in the release function could also be sent outside the critical section, but it would change up the semantics (readers/writers can be changed by other threads after unlock).
This way, we release the signal but keep the lock - therefore the signalled threads get blocked when they wake up.
Correctness can be proven using invariants.
Problem: Unfairness
Threads acquiring write can starve threads wanting to acquire read.
- Newer writer can starve older writer
- Newer reader can acquire lock before older reader or writer
Barrier synchronization (with condition variables and locks) → inefficient
Each thread executing
<barrier>must wait until all or some number of threads have also executed<barrier>.typedef struct { int tc; // thread count pthread_cond_t barrier_ok; pthread_mutex_t barwait;} barrier_t;void barrier(barrier_t *b, int total_tc) { pthread_mutex_lock(&b->barwait); // acquire barwait lockb->tc++; if (b->tc == total_tc) { // threshold reached b->tc = 0; pthread_cond_broadcast(&b->barrier_ok); } else { // wait until barrier_ok signal (acquire and immediately release barwait) pthread_cond_wait(&b->barrier_ok, &b->barwait); }pthread_mutex_unlock(&b->barwait); // release barwait lock }Problems
- Not scalable
- Probably not safe on spurious (unexpected) wake ups
Solution: Tree structured barrier with an extra flag
Barriers
Barriers
Each thread executing
<barrier>
must wait until all or some number of threads have also executed
<barrier>
.
Semaphores
Semaphore (by dijkstra)
concurrenct counter object with operations.
up(x)
atomic increment → wakes
x
up if it was negative
(signal, post, V)
down(x)
atomic decrement → blocks
x
if it turned negative
(wait, P)
If there is no thread in queue, the signals are not lost (contrary to condition variables).
Atomic operation
Atomic operation
Update to memory location or complex object that is atomic (can not be delayed, in one, uninterrupted):
- Indivisible either the whole result or nothing is seen by other threads
- Time bounded completed in finite time (wait-free, independent of other threads)
Usually done by hardware:
Require expensive hardware support and complex interaction with memory system (ie. cache-line invalidation).
- load/stores atomic loads and stores (can be ordered in program)
- ready-modify-write read, update, store
- Swap swap two memory locations (based on condition)
Example: finding all primes in interval
Finding all primes in interval with atomic operation
Find all primes between and .
for (i=2; i<1000000000; i++) { if (isPrime(i)) printf("Found %d\n",i); }Solution 1) Statically scheduled data parallel loop
Each thread executes block of size → load imbalance, only few processors perform expensive
isPrime()checks.Problem:
- Almost no speedup.
- Array compaction cannot help since we dont know where primes are in advance.
Solution 2) Shared global counter with global variable
int i = 0; // shared globally// thread code (function) while (i<1000000000) { int j = i; // thread gets next value of i i++; // illegal concurrent update -> race condition if (isPrime(j)) printf("Found %d\n",j); }Problem:
Unsafe because of multiple threads update
iat the same time.i++is not atomici++actually translates to:tmp = i; tmp = tmp+1; i = tmp;This way we can have an unwanted interleaving where
iis only incremented by 1 between two threads:tmp = i; tmp = i; tmp = tmp+1; tmp = tmp+1; i = tmp; i = tmp;
Solution 3) Shared global counter with mutex
int i = 0; // shared global. init once pthread_mutex_t count_lock = …;// thread code (function) while (i<1000000000) { int j; pthread_mutex_lock(&count_lock); // critical section :: j = i; i++; if (isPrime(j)) printf("Found %d\n",j); pthread_mutex_unlock(&count_lock); // :: critical section }Alternative: putting
isPrime()out of the critical sectionint i = 0; // shared global. init once pthread_mutex_t count_lock = …;// thread code (function) while (i<1000000000) { int j; pthread_mutex_lock(&count_lock); // critical section :: j = i; i++; // thread could just stop here somewhere arbitrarily pthread_mutex_unlock(&count_lock); // :: critical section if (isPrime(j)) printf("Found %d\n",j); }Problem: thread can sleep arbitrarily and make no progress after acquiring the lock, while other threads just wait.
Problem:
No speedup → all the other threads can’t make any progress when
isPrime()checks are in the critical sectionSolution 4) Atomic increment
int i = 0; // shared global// thread code (function) int done = 0; do { int j = fetch_and_inc(&i); // return i, increment O(1) if (j==1000000000) done = 1; else if (isPrime(j)) printf("Found %d\n",j); } while (!done);Wait-free algorithm
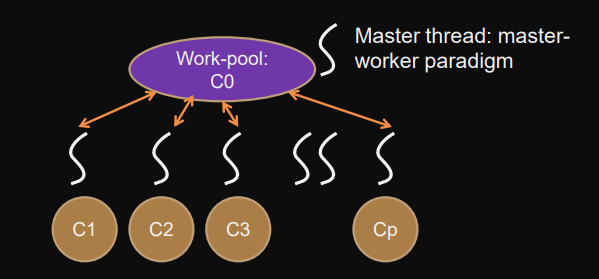
Work-pools (master-worker pattern)
Useful implementation of higher-level parallel paradigm.
Master Maintains pool of work
Workers ask for work, execute, return new results to master (until done)
Centralized work-pool
Work-pool distributed pool of work nodes (function and arguments)
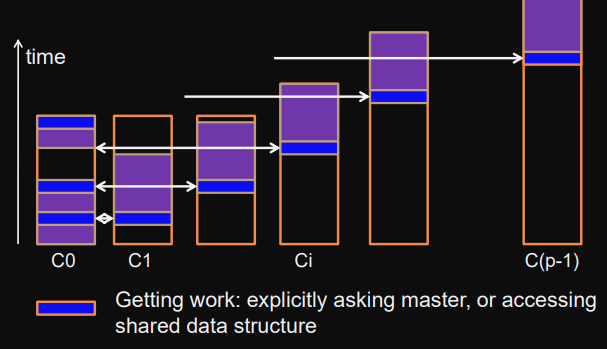
Scalability bottleneck
Getting work = explicitly asking master or accessing shared data structure
There is a competition for the work in the work-pool.
Implementation
Assume that work is executed in the order it was generated in (use deque data-structure as work-pool).
Each thread repeats until termination:
- Acquire mutex, check queue, if non-empty, take from front (else wait for condition variable).
- Execute work
- If new work generated: acquire mutex, insert at end of deque, wake up waiting threads
Work task as linked list:
typedef struct work {
void (*routine)(void *args); // function
void *args; // args
struct work *next; // next node in list
} work_t;Problems with centralized work pool
-
Centralized resource
Bad for scalability
-
Locks
Thread updating shared resource can lock out all other threads indefinitely
Solutions
-
Local task queues
thread primarily uses local queue → work stealing from other thread’s, when it’s empty
-
Lock-free/wait-free data structures
Enabling a thread always to either make progress by itself or to ensure that others are also making progress.
Make extensive use of strong atomic operations of type “compare and swap CAS”.
Decentralized work-pool
Each thread maintains local pool of work and executes work from own pool.
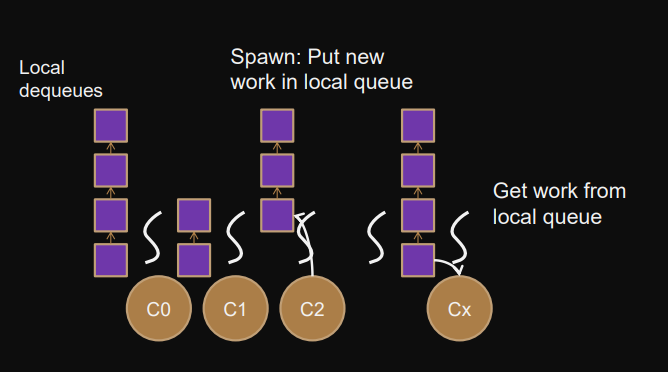
Work stealing local pool empty → steal work from other pools
Work dealing local pool full → distribute work to other pools
Randomized stealing
has good theoretical properties.
Deterministic stealing
Stealing from top of non-local queue.
Can provide good locality (cache) properties.