Grammatiken G = ⟨ N , T , P , S ⟩ G=\langle N, T, P, S\rangle G = ⟨ N , T , P , S ⟩
N N N
T T T
P ⊆ ( N ∪ T ) + × ( N ∪ T ) ∗ P \subseteq (N \cup T)^+ \times (N \cup T)^* P ⊆ ( N ∪ T ) + × ( N ∪ T ) ∗
Man schreibt α → w \small \alpha \rarr w α → w statt ( α , w ) ∈ P \small (\alpha,w) \in P ( α , w ) ∈ P
α → β 1 ∣ ⋯ ∣ β n \small \alpha \rightarrow \beta_{1}|\cdots| \beta_{n} α → β 1 ∣ ⋯ ∣ β n statt α → β 1 , … , α → β n
\small \alpha \rightarrow \beta_{1}, \ldots, \alpha \rightarrow \beta_{n}
α → β 1 , … , α → β n
S ∈ N S \in N S ∈ N
Satzform
w ∈ ( N ∪ T ) ∗ w \in(N \cup T)^* w ∈ ( N ∪ T ) ∗
Wenn
S ⇒ w S \Rarr w S ⇒ w w w w
Die Menge aller in
n n n
S F ( G , n ) = { w ∈ ( N ∪ T ) ∗ ∣ S ⇒ n w }
S F(G, n)=\left\{w \in(N \cup T)^{*} \mid S \Rightarrow^{n} w\right\}
SF ( G , n ) = { w ∈ ( N ∪ T ) ∗ ∣ S ⇒ n w }
Erzeugte Sprache
L ( G ) = { w ∈ T ∗ ∣ S ⇒ ∗ w }
\mathcal{L}(G)=\left\{w \in T^{*} \mid S \Rightarrow^{*} w\right\}
L ( G ) = { w ∈ T ∗ ∣ S ⇒ ∗ w }
Zwei Grammatiken äquivalent wenn
L ( G 1 ) = L ( G 2 )
\mathcal{L}\left(G_{1}\right)=\mathcal{L}\left(G_{2}\right)
L ( G 1 ) = L ( G 2 )
Kontextfreie Grammatiken Kontextfrei bedeutet dass die Ableitungs-Art keine Rolle spielt und man immer die selbe Sprache erzeugt.
L ( G ) = { w ∈ T ∗ ∣ S ⇒ ∗ w } = { w ∈ T ∗ ∣ S ⇒ L ∗ w } = { w ∈ T ∗ ∣ S ⇒ R ∗ w } = { w ∈ T ∗ ∣ S ⇒ P ∗ w }
\begin{aligned}\mathcal{L}(G) &=\left\{w \in T^{*} \mid S \Rightarrow^{*} w\right\} \\&=\left\{w \in
T^{*} \mid S \Rightarrow_{\textcolor{pink}L}^{*} w\right\} \\&=\left\{w \in T^{*} \mid S
\Rightarrow_{\textcolor{pink}R}^{*} w\right\} \\&=\left\{w \in T^{*} \mid S
\Rightarrow_{\textcolor{pink}P}^{*} w\right\}\end{aligned}
L ( G ) = { w ∈ T ∗ ∣ S ⇒ ∗ w } = { w ∈ T ∗ ∣ S ⇒
L
∗ w } = { w ∈ T ∗ ∣ S ⇒
R
∗ w } = { w ∈ T ∗ ∣ S ⇒
P
∗ w }
Kontextfreie Grammatiken sind
abgeschlossen unter
∪ , ⋅ , ∗ \cup, \cdot,^{*} ∪ , ⋅ , ∗ Beispiel G 1 = ⟨ N 1 , T 1 , P 1 , S 1 ⟩ , G 2 = ⟨ N 2 , T 2 , P 2 , S 2 ⟩
G_{1}=\left\langle N_{1}, T_{1}, P_{1}, S_{1}\right\rangle, \quad G_{2}=\left\langle
N_{2}, T_{2}, P_{2}, S_{2}\right\rangle
G 1 = ⟨ N 1 , T 1 , P 1 , S 1 ⟩ , G 2 = ⟨ N 2 , T 2 , P 2 , S 2 ⟩
N 1 ∩ N 2 = { } N_{1} \cap N_{2}=\{\} N 1 ∩ N 2 = { }
S ∉ N 1 ∪ N 2 S \notin N_{1} \cup N_{2} S ∈ / N 1 ∪ N 2
Kontextfreie Grammatiken:
G union = ⟨ N 1 ∪ N 2 ∪ { S } , T 1 ∪ T 2 , { S → S 1 ∣ S 2 } ∪ P 1 ∪ P 2 , S ⟩ G c a t = ⟨ N 1 ∪ N 2 ∪ { S } , T 1 ∪ T 2 , { S → S 1 ⋅ S 2 } ∪ P 1 ∪ P 2 , S ⟩ G star = ⟨ N 1 ∪ { S } , T 1 , { S → ε , S → S 1 S } ∪ P 1 , S ⟩
\begin{aligned}&G_{\text {union }}=\left\langle N_{1} \cup N_{2} \cup\{S\},
T_{1} \cup T_{2},\left\{S \rightarrow S_{1} \mid S_{2}\right\} \cup P_{1} \cup
P_{2}, S\right\rangle \\&G_{c a t}=\left\langle N_{1} \cup N_{2} \cup\{S\},
T_{1} \cup T_{2},\left\{S \rightarrow S_{1} \cdot S_{2}\right\} \cup P_{1} \cup
P_{2}, S\right\rangle \\&G_{\text {star }}=\left\langle N_{1} \cup\{S\},
T_{1},\left\{S \rightarrow \varepsilon, S \rightarrow S_{1} S\right\} \cup P_{1},
S\right\rangle\end{aligned}
G
union
=
⟨
N
1
∪
N
2
∪ {
S
} ,
T
1
∪
T
2
,
{
S
→
S
1
∣
S
2
}
∪
P
1
∪
P
2
,
S
⟩
G
c
a
t
=
⟨
N
1
∪
N
2
∪ {
S
} ,
T
1
∪
T
2
,
{
S
→
S
1
⋅
S
2
}
∪
P
1
∪
P
2
,
S
⟩
G
star
=
⟨
N
1
∪ {
S
} ,
T
1
,
{
S
→ ε ,
S
→
S
1
S
}
∪
P
1
,
S
⟩
Durchschnitt
∩ \cap ∩
nicht abgeschlossen unter
Durschschnitt
∩ \cap ∩ Beispiel L 1 = { a m b m c n ∣ m , n ≥ 1 }
L_{1}=\left\{a^{m} b^{m} c^{n} \mid m, n \geq 1\right\}
L 1 = { a m b m c n ∣ m , n ≥ 1 }
L 2 = { a m b n c n ∣ m , n ≥ 1 }
L_{2}=\left\{a^{m} b^{n} c^{n} \mid m, n \geq 1\right\}
L 2 = { a m b n c n ∣ m , n ≥ 1 }
L = L 1 ∪ L 2 L=L_{1} \cup L_{2} L = L 1 ∪ L 2
S → S 1 ∣ S 2 S \rightarrow S_{1} \mid S_{2} S → S 1 ∣ S 2
S 1 → S 1 c ∣ A A → a A b ∣ ε
\begin{aligned}&S_{1} \rightarrow S_{1} c \mid A \\&A \rightarrow a A b
\mid \varepsilon\end{aligned}
S
1
→
S
1
c ∣ A A → a A b ∣ ε
S 2 → a S 2 ∣ B B → b B c ∣ ε
\begin{aligned} &S_{2} \rightarrow \text { a } S_{2} \mid B \\ &B
\rightarrow b B c\mid \varepsilon \end{aligned}
S
2
→ a
S
2
∣
B
B
→ b
B
c ∣ ε
L 1 ∩ L 2 = { a n b n c n ∣ n ≥ 1 }
L_{1} \cap L_{2}=\left\{a^{n} b^{n} c^{n} \mid n \geq 1\right\}
L 1 ∩ L 2 = { a n b n c n ∣ n ≥ 1 } → nicht kontextfrei
Für jedes Wort aus dem Durchschnitt der beiden Sprachen kann man entweder über
S 1 S_1 S 1 S 2 S_2 S 2
Ableitungsbäume G = ( N , T , P , S ) G=(N, T, P, S) G = ( N , T , P , S )
Wir erzeugen einen Ableitungsbaum
g = ( K , E , L ) g=(K, E, L) g = ( K , E , L )
über Knotenmarkierungen
U = N ∪ T ∪ { ε } U=N \cup T \cup\{\varepsilon\} U = N ∪ T ∪ { ε }
und Kantenmarkierungen
W = { 1 , … , n } W=\{1, \ldots, n\} W = { 1 , … , n }
für die gegebene kontextfreie Grammatik.
Es gilt:
L ( p 0 ) = S L(p_0) = S L ( p 0 ) = S
Wenn
p p p L ( p ) ∈ N L(p)\in N L ( p ) ∈ N
Wenn
p p p L ( p ) = ε L(p) = \varepsilon L ( p ) = ε
Die von
p p p { ( p , i , q i ) ∣ i ∈ 1 , … , n }
\left\{\left(p, i, q_{i}\right) \mid i \in 1, \ldots, n\right\}
{ ( p , i , q i ) ∣ i ∈ 1 , … , n } L ( p ) = A L(p) = A L ( p ) = A
A → L ( q 1 ) … L ( q k ) A \rightarrow L(q_{1}) \ldots L(q_{k}) A → L ( q 1 ) … L ( q k )
A-Baum
Wenn für die Wurzel gilt:
L ( p 0 ) = A L(p_0) = A L ( p 0 ) = A A ∈ N A \in N A ∈ N
Ansonsten S-Baum.
Ordnungsrelation von Pfaden
Angenommen wir haben einen A-Baum.
Wir definieren eine Ordnungsrelation der Pfade:
P ( j ) = ( p j , 0 , e j , 1 , p j , 1 , … , e j , k j , p j , k j )
P(j)=\left(p_{j, 0}, e_{j, 1}, p_{j, 1}, \ldots, e_{j, k_{j}}, p_{j, k_{j}}\right)
P ( j ) = ( p
j
, 0 , e
j
, 1 , p
j
, 1 , … , e
j
,
k
j
, p
j
,
k
j
)
Angenommen wir haben 2 verschiedene Pfade von der Wurzel
j ∈ { 1 , 2 } j \in\{1,2\} j ∈ { 1 , 2 }
p 1 , 0 = p 2 , 0 = p 0 p_{1,0}=p_{2,0}=p_{0} p 1 , 0 = p 2 , 0 = p 0 (der 0te Knoten in Pfaden 1 und 2 ist p 0 p_0 p 0 )
dann definieren wir die Ordnungsrelation
P 1 < P 2 P_1 < P_2 P 1 < P 2
∃ m ≥ 1 \exists m \geq 1 ∃ m ≥ 1 ∀ 1 ≤ i < m , e 1 , m < e 2 , m : e 1 , i = e 2 , i
\forall 1 \leq i <m,~e_{1,m}<e_{2,m}:~ e_{1, i}=e_{2, i}
∀1 ≤ i < m , e 1 , m < e 2 , m : e 1 , i = e 2 , i
(die Kanten von Pfade 1 und 2 sind überall gleich, außer in der Ebene m m m , wo P 1 P_1 P 1 eine Kante mit einem niedrigeren Wert gewählt hat)
Front
Sind
p 1 , … , p k p_1, \dots, p_k p 1 , … , p k L ( p 1 ) … L ( p k ) L(p_{1}) \ldots L(p_{k}) L ( p 1 ) … L ( p k )
Sätze
Sei
w ∈ ( N ∪ T ) ∗ w \in(N \cup T)^{*} w ∈ ( N ∪ T ) ∗ A ⇒ ∗ w A \Rightarrow^{*} w A ⇒ ∗ w w w w
Sei
v ∈ T ∗ v\in T^* v ∈ T ∗ S ⇒ ∗ v S \Rightarrow^{*} v S ⇒ ∗ v v v v
Eindeutigkeit vs. Mehrdeutigkeit Eindeutig vs. Mehrdeutig
Eindeutig wenn:
zu jedem ableitbaren Terminalwort es genau eine einzige Linksableitung gibt.
Ansonsten mehrdeutig.
Inhärent mehrdeutige Sprache
Mehrdeutig wenn:
jede Grammatik die Sprache
L L L
Beispiel: Mehrdeutig
Mehrdeutige Grammatik zu der sich aber eine eindeutige Grammatik finden lässt
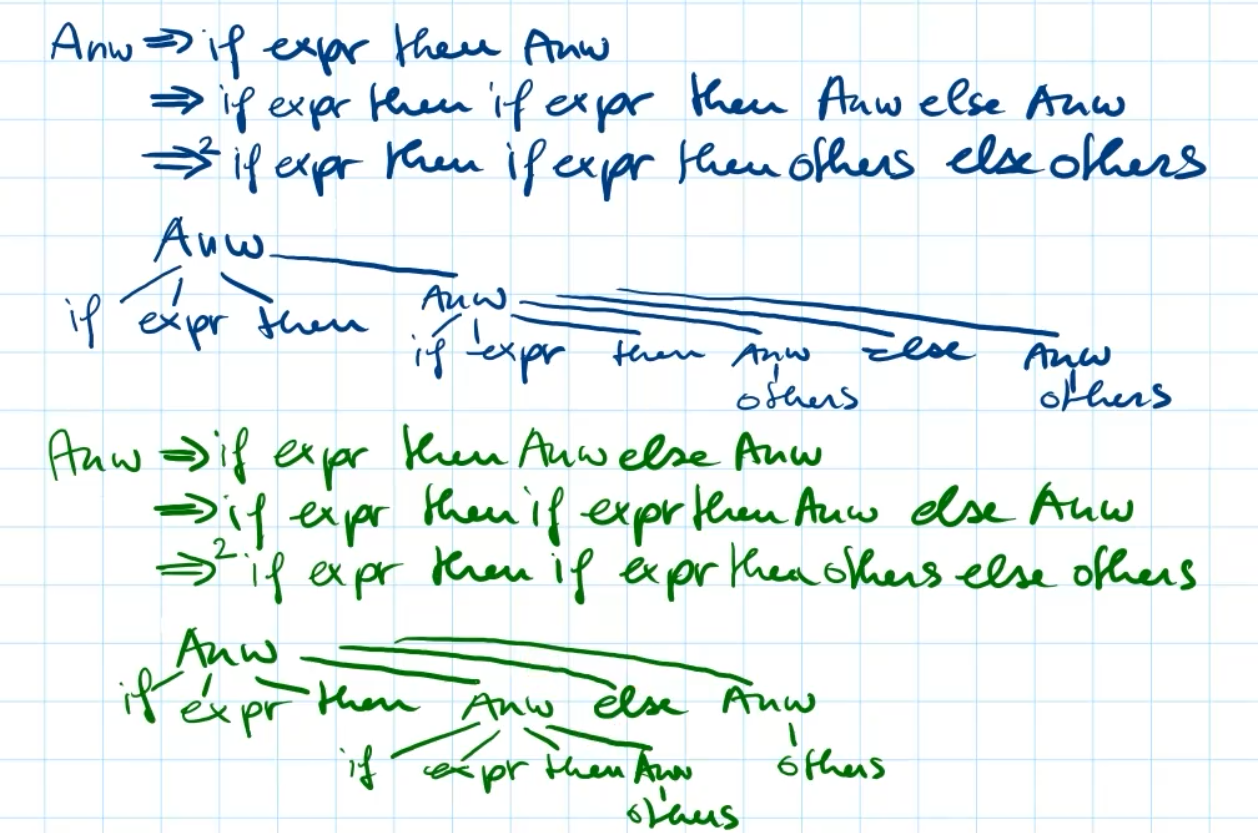
if-then-else Anweisung G 1 = ⟨ { A n w } , { if, then, else, expr, others } , P 1 , Anw ⟩
G_{1}=\left\langle\{A n w\},\{\text { if, then, else, expr, others }\}, P_{1}, \text { Anw
}\right\rangle
G 1 = ⟨ { A n w } , { if, then, else, expr, others } , P 1 , Anw ⟩
Anw → if expr then Anw
| if expr then Anw else Anw
| others
\begin{aligned}&\text { Anw } \rightarrow \text { if expr then Anw } \\&\qquad\quad ~
\begin{array}{l}\text {| if expr then Anw else Anw } \\\text {| others }\end{array}\end{aligned}
Anw →
if expr then Anw
| if expr then Anw else Anw
| others
Das Wort
if expr then if expr then others else others
\small \color{grey} \text { if expr then if expr then others else others }
if expr then if expr then others else others
Man kann in der Ableitung
if expr then Anw else Anw
\text { if expr then \textcolor{red}{Anw }else \textcolor{red}{Anw} }
if expr then Anw else Anw
entweder die linke oder rechte Anweisung nehmen.
Äquivalente eindeutige Grammatik Es gibt keinen Algorithmus um alle mehrdeutigen Grammatiken eindeutig zu machen.
In diesem Fall wäre die eindeutige Version:
G 2 = ⟨ { Anw, AnwT, AnwTE } , { if, then, else, expr, others } , P 2 , Anw ⟩
\begin{aligned}G_{2}=&\langle\{\text { Anw, AnwT, AnwTE }\},\\&\left.\{\text { if, then,
else, expr, others }\}, P_{2}, \text { Anw }\right\rangle\end{aligned}
G 2 = ⟨{ Anw, AnwT, AnwTE } , {
if, then, else, expr, others
} ,
P
2 , Anw ⟩
Hier lassen wir nur nach
then
eine Anweisung mit
then-else
zu.
Anw → AnwT ∣ AnwTE AnwT → if expr then A n w ∣ if expr then AnwTE else AnwT AnwTE →
if expr then AnwTE else AnwTE
∣ others
\begin{aligned} \text { Anw } & \rightarrow \text { AnwT } \\ & \mid \text { AnwTE } \\
\text { AnwT } & \rightarrow \text { if expr then } A n w \\ & \mid \text { if expr then
AnwTE else AnwT } \\ \text { AnwTE } & \rightarrow \text { if expr then AnwTE else AnwTE }
\\ & \mid \text { others } \end{aligned}
Anw AnwT AnwTE → AnwT ∣ AnwTE → if expr then A n w ∣
if expr then AnwTE else AnwT
→
if expr then AnwTE else AnwTE
∣ others
Beispiel: Inhärent mehreutig
Mehrdeutige Grammatik zu der sich gar keine eindeutige Grammatik finden lässt
Vereinigung von 2 kontextfreien Grammatiken L 1 = { a m b m c n ∣ m , n ≥ 1 }
L_{1}=\left\{a^{m} b^{m} c^{n} \mid m, n \geq 1\right\}
L 1 = { a m b m c n ∣ m , n ≥ 1 }
L 2 = { a m b n c n ∣ m , n ≥ 1 }
L_{2}=\left\{a^{m} b^{n} c^{n} \mid m, n \geq 1\right\}
L 2 = { a m b n c n ∣ m , n ≥ 1 }
L = L 1 ∪ L 2 L=L_{1} \cup L_{2} L = L 1 ∪ L 2
S → S 1 ∣ S 2 S \rightarrow S_{1} \mid S_{2} S → S 1 ∣ S 2
S 1 → S 1 c ∣ A A → a A b ∣ ε
\begin{aligned}&S_{1} \rightarrow S_{1} c \mid A \\&A \rightarrow a A b \mid
\varepsilon\end{aligned}
S
1 →
S
1 c ∣ A A → a A b ∣ ε
S 2 → a S 2 ∣ B B → b B c ∣ ε
\begin{aligned} &S_{2} \rightarrow \text { a } S_{2} \mid B \\ &B \rightarrow b B
c\mid \varepsilon \end{aligned}
S
2 → a
S
2 ∣
B
B
→ b
B
c ∣ ε
L 1 ∩ L 2 = { a n b n c n ∣ n ≥ 1 }
L_{1} \cap L_{2}=\left\{a^{n} b^{n} c^{n} \mid n \geq 1\right\}
L 1 ∩ L 2 = { a n b n c n ∣ n ≥ 1 }
Für jedes Wort aus dem Durchschnitt der beiden Sprachen kann man entweder über
S 1 S_1 S 1 S 2 S_2 S 2
Deshalb nicht eindeutig (für alle Wörter).
Bemerkung: Kontextfreie Sprachen sind nicht unter Durchschnitt abgeschlossen.
Normalformen für kontextfreie Grammatiken Kontextfrei bedeutet dass die Ableitungs-Art keine Rolle spielt und man immer die selbe Sprache erzeugt.
Normalform bedeutet eine Einschränkung der rechten Seite der Produktionen β \beta β .
Reduzierte Grammatik
(Vorbereitung für Chomsky NF) Reduzierte Grammatik
Wir möchten aus einer kontextfreien Sprache
L L L ε \varepsilon ε
ohne nutzlose Produktionen
Produktionen die nicht vom Startsymbol erreichbar sind:
w ∉ T ∗ \small w \notin T^* w ∈ / T ∗
Symbole
∈ ( N ∪ T ) \in (N\cup T) ∈ ( N ∪ T )
ohne ε \small \varepsilon ε -Produktionen N → ε \small N\rarr \varepsilon N → ε
ohne Einheits-Produktionen N → N \small N\rarr N N → N
Ausgehend von einer existenten Grammatik
G G G
Die erzeugte Sprache bleibt gleich.
G = ⟨ N , T , P , S ⟩ G=\langle N, T, P, S\rangle G = ⟨ N , T , P , S ⟩
G i = ⟨ N i , T i , P i , S ⟩ , 1 ≤ i ≤ 4
G_{i}=\left\langle N_{i}, T_{i}, P_{i}, S\right\rangle, \quad1 \leq i \leq 4
G i = ⟨ N i , T i , P i , S ⟩ , 1 ≤ i ≤ 4
Entfernen nutzloser Produktionen
Alle Nonterminale und Produktionen die zu einem Terminalwort führen:
N 1 ( 1 ) = { A ∈ N ∣ A → w ∈ P , w ∈ T ∗ }
N_{1}^{(1)}=\left\{A \in N \mid A \rightarrow w \in P, w \in T^{*}\right\}
N 1 ( 1 ) = { A ∈ N ∣ A → w ∈ P , w ∈ T ∗ }
N 1 ( i ) = { A ∈ N ∣ A → w ∈ P , w ∈ ( N 1 ( i − 1 ) ∪ T ) ∗ } ∪ N 1 ( i − 1 )
N_{1}^{(i)}=\left\{A \in N \mid A \rightarrow w \in P, w \in\left(N_{1}^{(i-1)} \cup
T\right)^{*}\right\} ~~ \cup ~~N_{1}^{(i-1)}
N 1 ( i ) = { A ∈ N ∣ A → w ∈ P , w ∈ ( N 1 ( i − 1 ) ∪ T ) ∗ } ∪ N 1 ( i − 1 )
bis
N 1 ( m + 1 ) = N 1 ( m ) N_{1}^{(m+1)}=N_{1}^{(m)} N 1 ( m + 1 ) = N 1 ( m ) m m m
Dann erhalten wir
G 1 = ⟨ N 1 , T , P 1 , S ⟩
\color{pink} G_{1}=\left\langle N_{1}, T, P_{1}, S\right\rangle
G 1 = ⟨ N 1 , T , P 1 , S ⟩
N 1 = N 1 ( m ) N_{1}=N_{1}^{(m)} N 1 = N 1 ( m ) — wobei N 1 = { A ∈ N ∣ A ⇒ ∗ w ∈ T ∗ } N_1 = \{A \in N\mid A \Rarr^* w \in T^*\} N 1 = { A ∈ N ∣ A ⇒ ∗ w ∈ T ∗ }
P 1 P_1 P 1
Die Sprache ist leer L ( G ) = { } L(G)=\{\} L ( G ) = { } wenn S ∉ N ( m ) S \notin N_{}^{(m)} S ∈ / N ( m )
Alle Symbole
V ⊆ ( N ∪ T ) V \sube(N \cup T) V ⊆ ( N ∪ T ) V 2 ( 1 ) = { S } V_{2}^{(1)}=\{S\} V 2 ( 1 ) = { S }
u , v ∈ ( N 1 ∪ T ) ∗ u, v \in\left(N_{1} \cup T\right)^{*} u , v ∈ ( N 1 ∪ T ) ∗
V 2 ( i ) = { α ∈ N 1 ∪ T ∣ A → u α v ∈ P 1 , A ∈ ( V 2 ( i − 1 ) ∩ N 1 ) } ∪ V 2 ( i − 1 )
\begin{gathered}V_{2}^{(i)}=\{\alpha \in N_{1} \cup T \mid A \rightarrow u~\alpha~v \in P_{1},~~ A
\in\left(V_{2}^{(i-1)} \cap N_{1}\right) \left.\right\}~~\cup ~~V_{2}^{(i-1)}\end{gathered}
V 2 (
i
) = { α ∈ N 1 ∪ T ∣ A → u α v ∈ P 1 , A ∈ (
V
2 (
i
− 1 ) ∩
N
1 ) } ∪ V 2 (
i
− 1 )
bis
V 2 ( m + 1 ) = V 2 ( m ) V_{2}^{(m+1)}=V_{2}^{(m)} V 2 ( m + 1 ) = V 2 ( m )
A \small A A besteht nur aus den Nonterminalen aus dem letzten Schritt ( i − 1 ) \small (i-1) ( i − 1 ) .
Dann erhalten wir
G 2 = ⟨ N 2 , T 2 , P 2 , S ⟩
\color{pink}G_{2}=\left\langle N_{2}, T_{2}, P_{2}, S\right\rangle
G 2 = ⟨ N 2 , T 2 , P 2 , S ⟩
N 2 = V 2 ( m ) ∩ N 1 N_{2}=V_{2}^{(m)} \cap N_{1} N 2 = V 2 ( m ) ∩ N 1
T 2 = V 2 ( m ) ∩ T 1 T_{2}=V_{2}^{(m)} \cap T_{1} T 2 = V 2 ( m ) ∩ T 1
P 2 P_2 P 2 N 2 ∪ T 2 N_2 \cup T_2 N 2 ∪ T 2
Enfernen von ε \varepsilon ε -Produktionen
N 3 N_3 N 3 ist die Menge aller Nonterminale die zu einem ε \varepsilon ε führen.
N 3 ( 1 ) = { A ∈ N 2 ∣ A → ε ∈ P 2 }
N_{3}^{(1)}=\left\{A \in N_{2} \mid A \rightarrow \varepsilon \in P_{2}\right\}
N 3 ( 1 ) = { A ∈ N 2 ∣ A → ε ∈ P 2 }
N 3 ( i ) = { A ∈ N 2 ∣ A → w ∈ P 2 , w ∈ ( N 3 ( i − 1 ) ) ∗ } ∪ N 3 ( i − 1 )
N_{3}^{(i)}=\left\{A \in N_{2} \mid A \rightarrow w \in P_{2}, w \in\left(N_{3}^{(i-1)}\right)^{*}\right\}
~~\cup ~~N_{3}^{(i-1)}
N 3 ( i ) = { A ∈ N 2 ∣ A → w ∈ P 2 , w ∈ ( N 3 ( i − 1 ) ) ∗ } ∪ N 3 ( i − 1 )
Aus S ∈ N 3 ( ∣ N 2 ∣ ) S \in N_{3}^{\left(|N_{2}|\right)} S ∈ N 3 ( ∣
N
2 ∣ ) folgt, dass ε ∈ L ( G 2 ) \varepsilon \in \mathcal{L}\left(G_{2}\right) ε ∈ L ( G 2 )
Dann erhalten wir
G 3 \color{pink}G_{3} G 3
Für
P 3 P_3 P 3 P 2 P_2 P 2
A → X 1 … X k A \rightarrow X_{1} \ldots X_{k} A → X 1 … X
k
X i ∈ N 2 ∪ T X_{i} \in N_{2} \cup T X i ∈ N 2 ∪ T
jetzt die Produktionen
A → Y 1 … Y k A \rightarrow Y_{1} \ldots Y_{k} A → Y 1 … Y
k
für die gilt
Y 1 … Y k ≠ ε Y_{1} \ldots Y_{k} \neq \varepsilon Y 1 … Y
k
= ε // kein ε \varepsilon ε auf rechter Seite
Y i = X i Y_{i}=X_{i} Y i = X i X i ∈ N 2 − N 3 ( ∣ N 2 ∣ ) X_{i} \in N_{2}-N_{3}^{\left({|N_2|}\right)} X i ∈ N 2 − N 3 ( ∣
N
2 ∣ )
Y i = ε Y_{i}=\varepsilon Y i = ε X i ∈ N 3 ( ∣ N 2 ∣ ) X_{i} \in N_{3}^{\left(|N_{2}|\right)} X i ∈ N 3 ( ∣
N
2 ∣ ) // sollte es S → ε S \rarr \varepsilon S → ε geben dann belassen
Dadurch: L ( G 3 ) = L ( G ) − ε
\mathcal{L}\left(G_{3}\right)=\mathcal{L}(G)-\varepsilon
L ( G 3 ) = L ( G ) − ε
Entfernen von Einheits-Produktionen
Für alle
B 0 → B 1 ∈ P 3 : B_{0} \rightarrow B_{1} \in P_3: B 0 → B 1 ∈ P 3 :
B 0 ⇒ B 1 ⇒ B 2 ⇒ … ⇒ B k ⇒ w , w ∉ N 3
B_{0} \Rightarrow B_{1} \Rightarrow B_{2} \Rightarrow \ldots \Rightarrow B_{k} \Rightarrow w,~~~w \notin
N_{3}
B 0 ⇒ B 1 ⇒ B 2 ⇒ … ⇒ B k ⇒ w , w ∈ / N 3
(Der letzte Schritt
k k k
Wir ersetzen
B 0 → B 1 B_0 \rarr B_1 B 0 → B 1 B 0 → w B_0 \rarr w B 0 → w
Dadurch können wieder nutzlose Symbole entstehen.
Deshalb muss man hier wieder Schritt 1, 2 ausführen.
Dann erhalten wir
G 4 \color{pink}G_{4} G 4
Chomsky Normalform Chomsky Normalform
Alle Produktionen besitzen die Form:
N → N N N \rarr NN N → NN
N → T N \rarr T N → T
Wenn
S ∉ β : S \notin \beta: S ∈ / β : S → ε S \rarr \varepsilon S → ε
Satz
Für jede kontexfreie Grammatik lässt sich eine äquivalente Chomsky-NF konstruieren.
Beweis
Wenn
L ( G ) = { } \mathcal{L}(G)=\{\} L ( G ) = { }
Wenn
L ( G ) ≠ { } \mathcal{L}(G) \neq\{\} L ( G ) = { }
Aus
G G G G 4 = ⟨ N 4 , T 4 , P 4 , S ⟩
G_{4}=\left\langle N_{4}, T_{4}, P_{4}, S\right\rangle
G 4 = ⟨ N 4 , T 4 , P 4 , S ⟩
Diese erzeugt:
L ( G ) − ε \mathcal{L}(G)-\varepsilon L ( G ) − ε
Aus
G 4 G_4 G 4 G ′ G' G ′
Für jede Produktion in
P 4 P_4 P 4
Für
A , B ∈ N A, B \in N A , B ∈ N A → B 1 … B k A \rightarrow B_{1} \ldots B_{k} A → B 1 … B
k
ersetzen mit
A → B 1 Y 1 , Y 1 → B 2 Y 2 , … , Y k − 2 → B k − 1 B k
A \rightarrow B_{1} Y_{1},~~ Y_{1} \rightarrow B_{2} Y_{2},~~\ldots,~~ Y_{k-2}
\rightarrow B_{k-1} B_{k}
A → B 1 Y 1 , Y 1 → B 2 Y 2 , … , Y
k
− 2 → B
k
− 1 B
k
Falls
ε ∈ L ( G ) \varepsilon \in L(G) ε ∈ L ( G )
Wenn
S ∉ β : S \notin \beta: S ∈ / β : S → ε S \rarr \varepsilon S → ε
Wenn
S ∈ β : S \in \beta: S ∈ β :
neues
S ′ ′ S'' S ′′ N ′ N' N ′
Produktionen
{ S ′ ′ → w ∣ S → w ∈ P ′ }
\left\{S'' \rightarrow w \mid S \rightarrow w \in P'\right\}
{ S ′′ → w ∣ S → w ∈ P ′ }
Greibach Normalform
Wenn
S ∉ β : S \notin \beta: S ∈ / β : S → ε S \rarr \varepsilon S → ε
Greibach Normalform
Alle Produktionen haben die Form
Erweiterte Greibach Normalform
Alle Produktionen haben die Form
N → T ( N ∪ T ) ∗ N \rarr T(N\cup T)^* N → T ( N ∪ T ) ∗
Satz
Für jede kontexfreien Grammatik lässt sich eine äquivalente (auch erweiterte) Greibach-NF konstruieren.
Übersicht: Alle eingeschränkte Varianten
Seien Produktionen der Form:
α → β ∈ P \alpha \rightarrow \beta \in P α → β ∈ P
Überall wenn
S ∉ β : S \notin \beta: S ∈ / β :
auch
S → ε S \rarr \varepsilon S → ε
Kontextsensitive Grammatik
Für alle Produktionen gilt
α ∈ ( N ∪ T ) ∗ × N × ( N ∪ T ) ∗
\alpha \in (N \cup T)^{*} \times N \times (N \cup T)^{*}
α ∈ ( N ∪ T ) ∗ × N × ( N ∪ T ) ∗ (Nonterminal umgeben von Kontext)
β ∈ ( N ∪ T ) ∗ × ( N ∪ T ) + × ( N ∪ T ) ∗
\beta \in (N \cup T)^{*} \times (N \cup T)^{+} \times (N \cup T)^{*}
β ∈ ( N ∪ T ) ∗ × ( N ∪ T ) + × ( N ∪ T ) ∗
kontextsensitive Grammatik
⇆ \leftrightarrows ⇆
Kontextfreie Grammatik
Für alle Produktionen gilt
Reguläre Grammatik
Es gibt links- und rechts-regulären Sprachen.
Für alle Produktionen gilt
N → T ⋅ N N \rightarrow T \cdot N N → T ⋅ N
N → ε N \rightarrow \varepsilon N → ε
oder
N → T ⋅ N N \rightarrow T \cdot N N → T ⋅ N
N → T N \rightarrow T N → T
Reguäre Sprache
⇆ \leftrightarrows ⇆ ⇆ \leftrightarrows ⇆
Umwandlung A = ⟨ Q , Σ , δ , q 0 , F ⟩
\mathcal{A}=\left\langle Q, \Sigma, \delta, q_{0}, F\right\rangle
A = ⟨ Q , Σ , δ , q 0 , F ⟩
G = ⟨ Q , Σ , P , q 0 ⟩
G=\left\langle Q, \Sigma, P, q_{0}\right\rangle
G = ⟨ Q , Σ , P , q 0 ⟩
q → a p ∈ P q \rightarrow a p \in P q → a p ∈ P δ ( q , a ) = p \delta(q, a)=p δ ( q , a ) = p
q → ε ∈ P q \rightarrow \varepsilon \in P q → ε ∈ P q ∈ F q \in F q ∈ F
δ ∗ ( q 0 , w ) ∈ F \delta^{*}\left(q_{0}, w\right) \in F δ ∗ ( q 0 , w ) ∈ F q 0 ⇒ ∗ w q_{0} \Rightarrow^{*} w q 0 ⇒ ∗ w
Monotone Grammatik
α ≠ ε \alpha \neq \varepsilon α = ε
Wenn für jede Produktion gilt:
∣ α ∣ ≤ ∣ β ∣ |\alpha| \leq |\beta| ∣ α ∣ ≤ ∣ β ∣
kontextsensitive Grammatik
⇆ \leftrightarrows ⇆