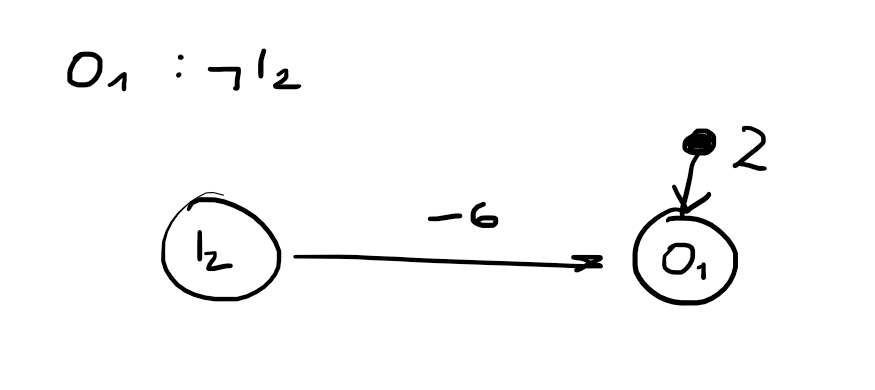
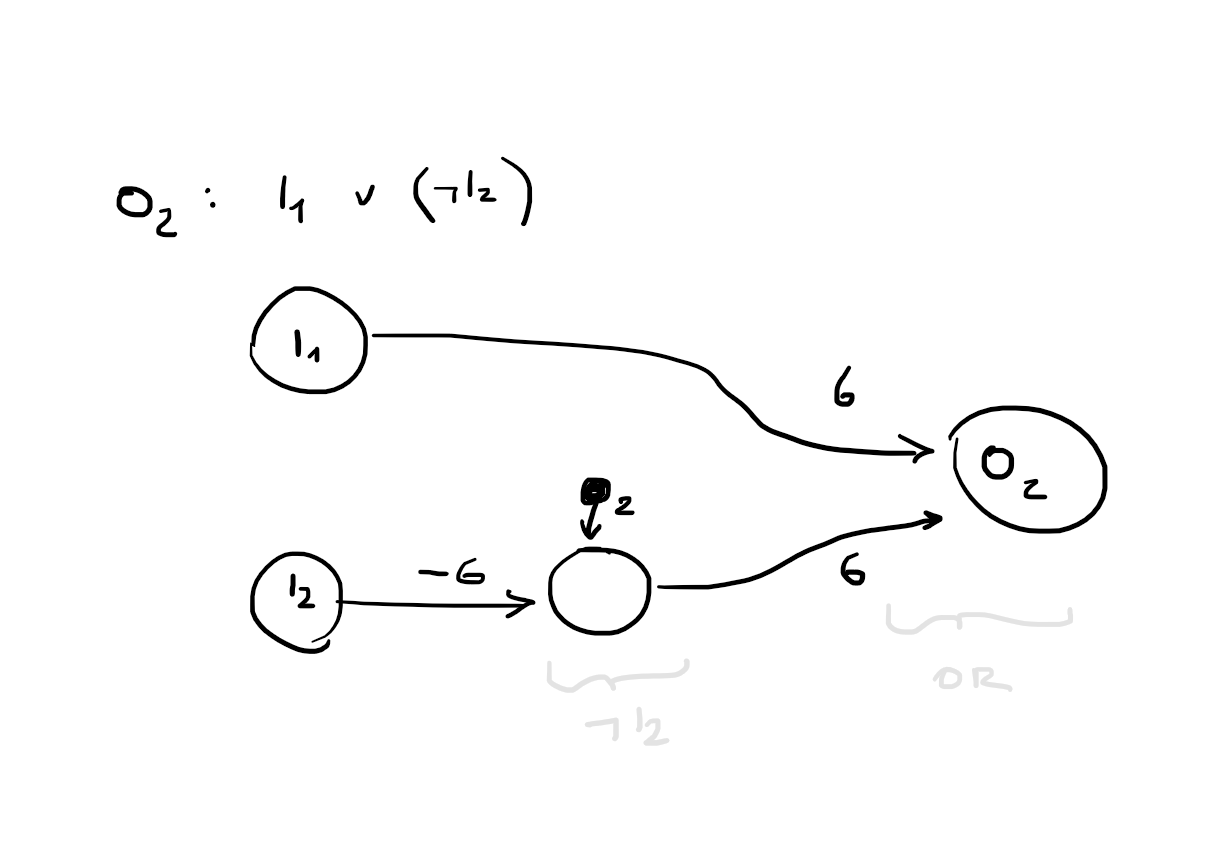
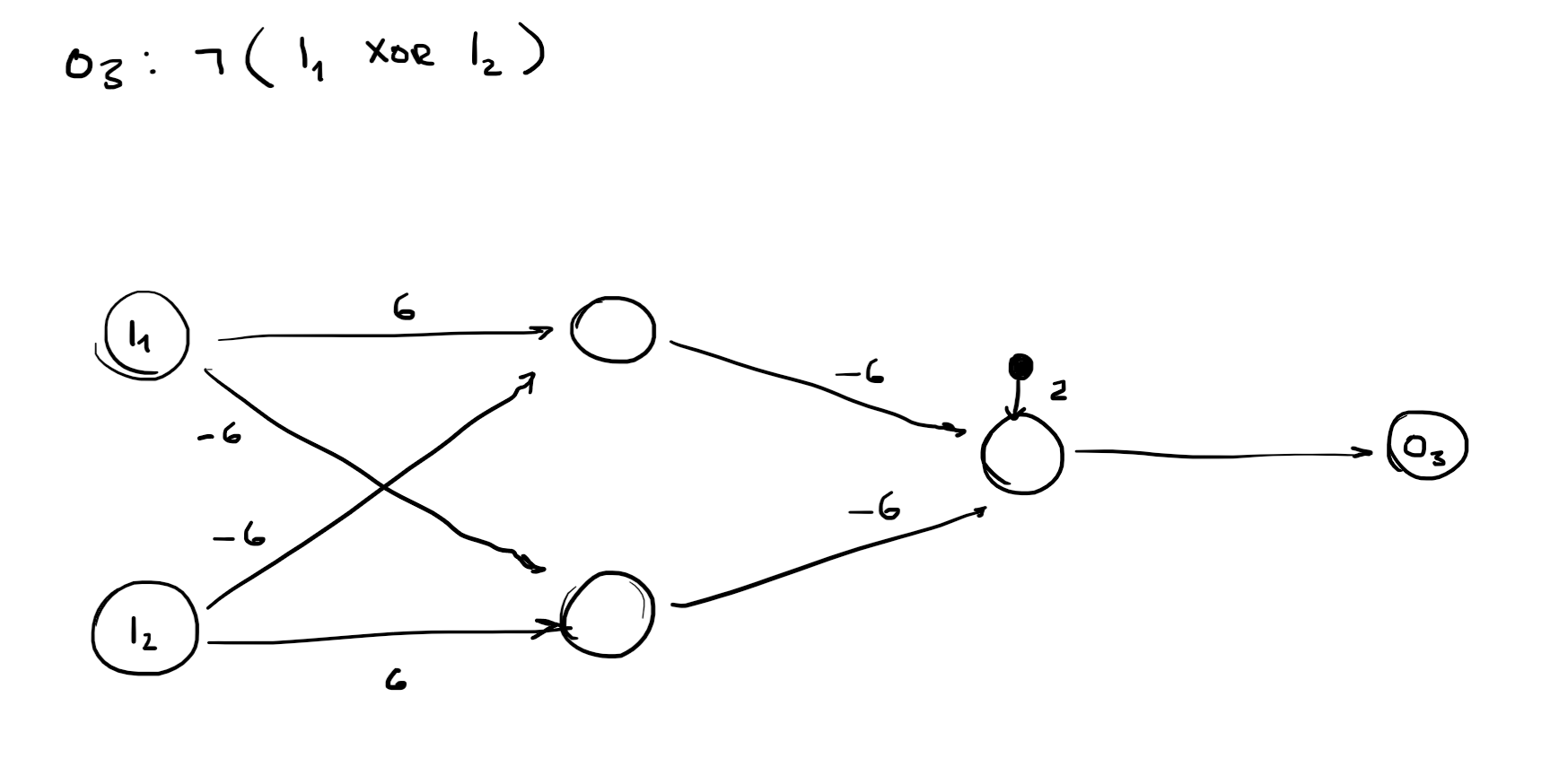
whether sensors can detect all relevant properties
single-agent vs. multi-agent
single agent, or multiple with cooperation, competition
deterministic vs. stochastic
whether the next state can be determined by current state + the performed action or is fully independent and can't be
foreseen (multiple possible following states) - and we know the probabilities
episodic vs. sequential
Episodic: the choice of action only depends on the current episode - percept history divided into independent episodes.
Sequential: storing entire history (accessing memories lowers performance)
static vs. dynamic vs. semi-dynamic
Static: world does not change during the reasoning / processing time of the agent (waits for agents response)
Semi-dynamic: environment is static, but performance score decreases while processing time.
discrete vs. continuous
property values of the world
known vs. unknown
state of knowledge about the "laws of physics" of the environment
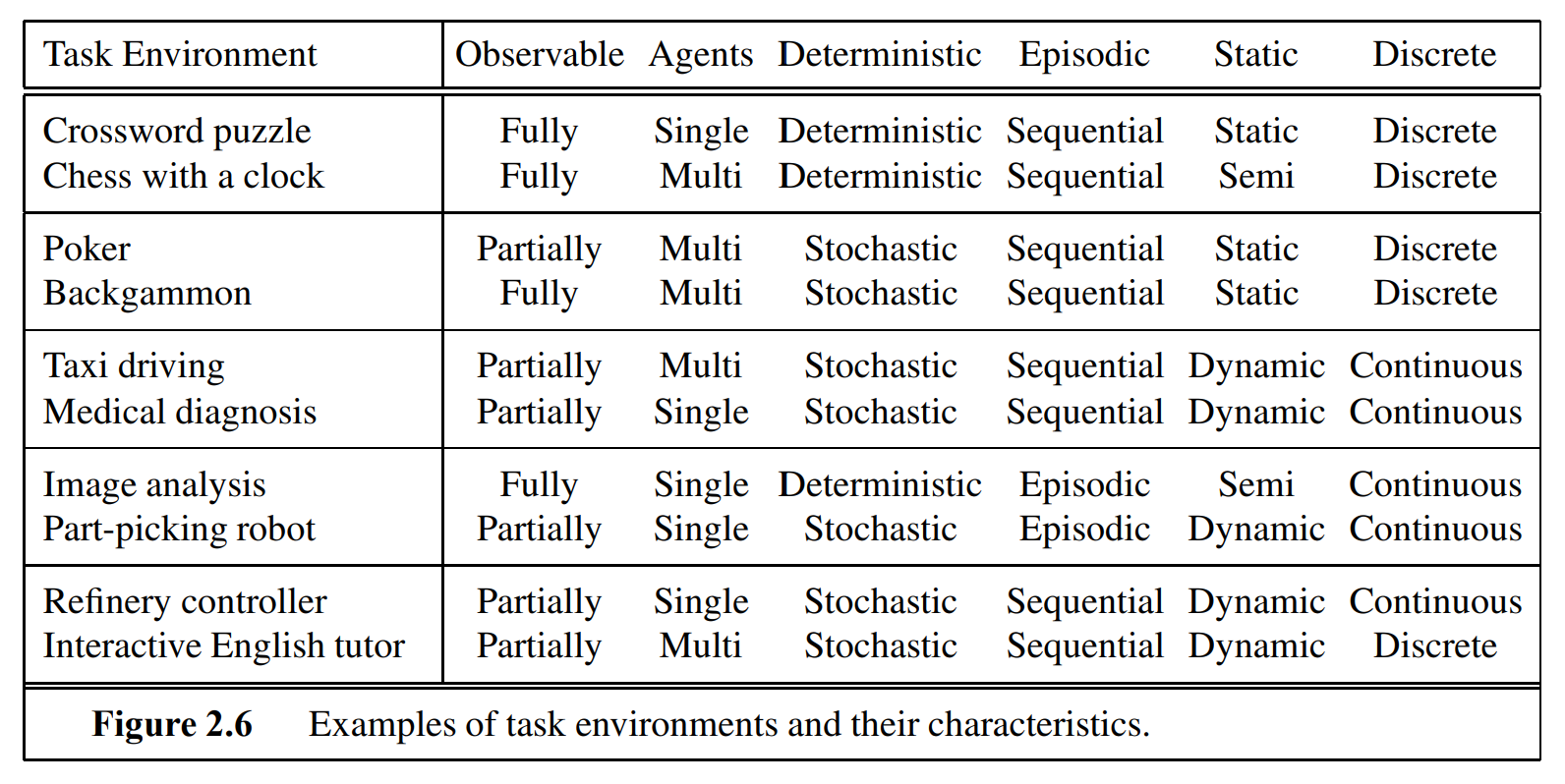
Example
A game of poker is in a discrete environment.
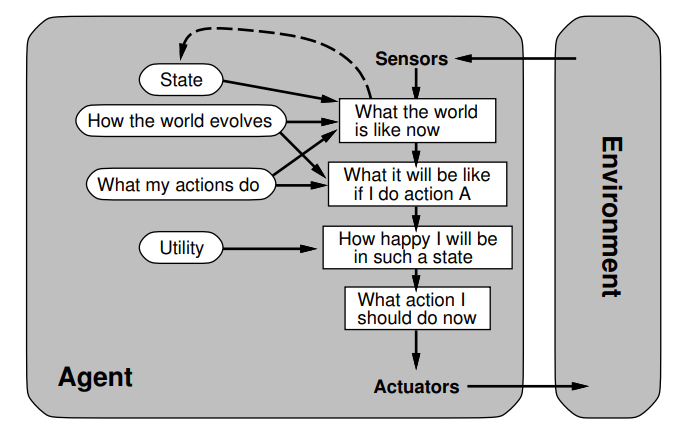
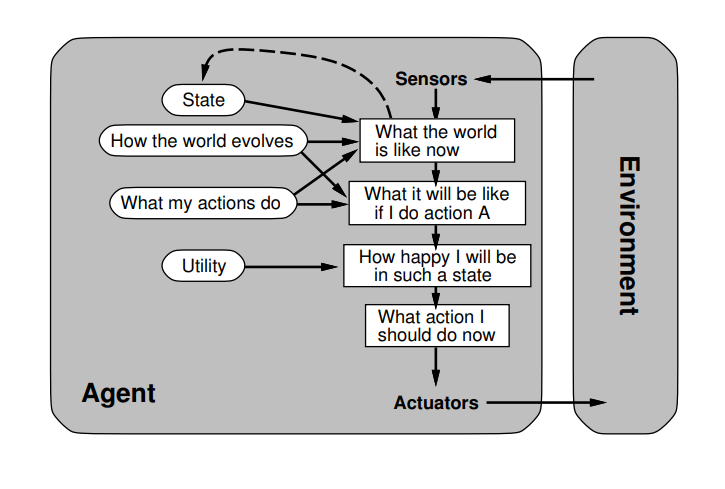
Name the 4 components of an agents task description
Chooses action that maximizes performance measure outuput for any percept sequence.
Decisions based on evidence:
percept history
built-in knowledge of the environment (if the environment is known)-
ie. fundamental knowledge laws like physics
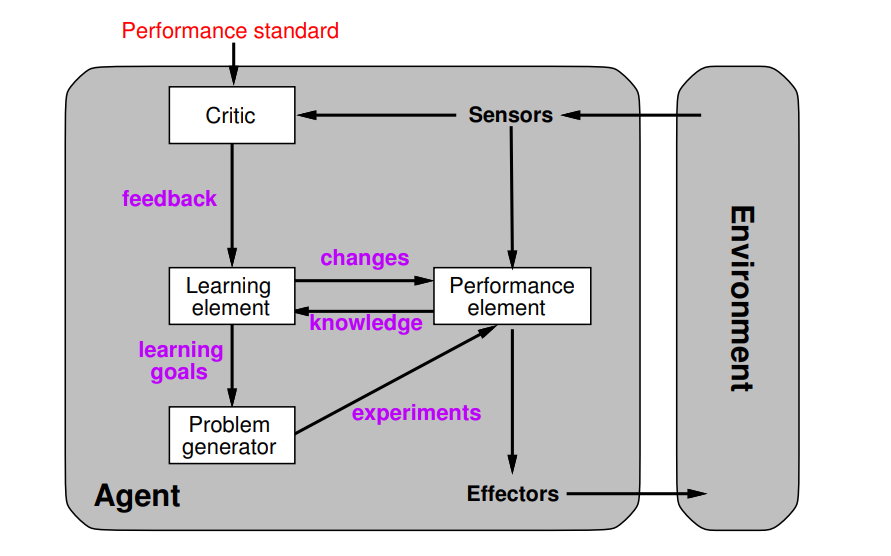
Agent types
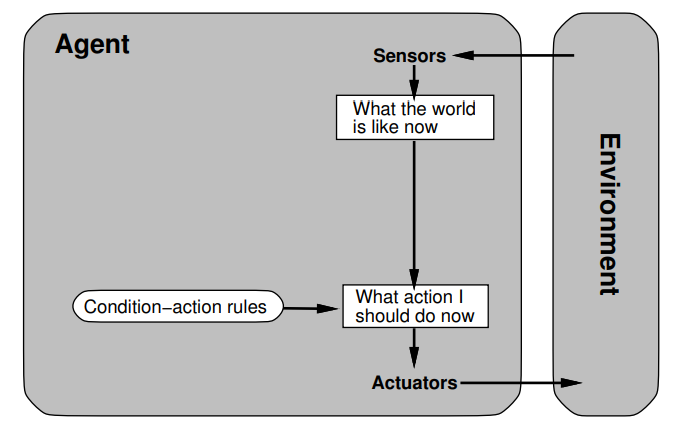
Simple reflex agents
No memory (percept sequences)
no internal states
Possible non-termination
Only suitable for very specific tasks
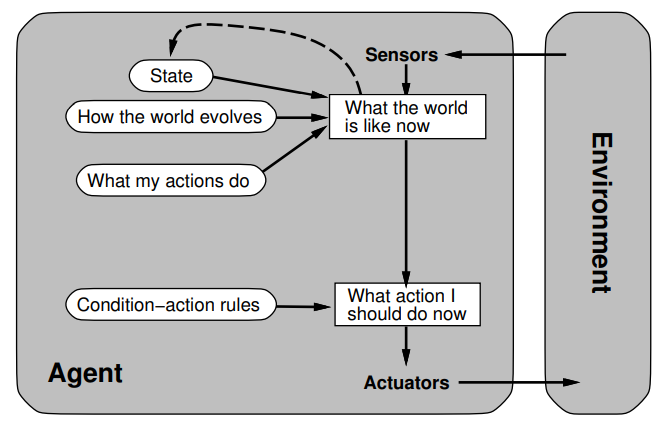
Model-based reflex agent
memory
internal states
of the world
model of environment and changes in it
can reason about unobservable parts
can deal with uncertainty
has
implicit goals
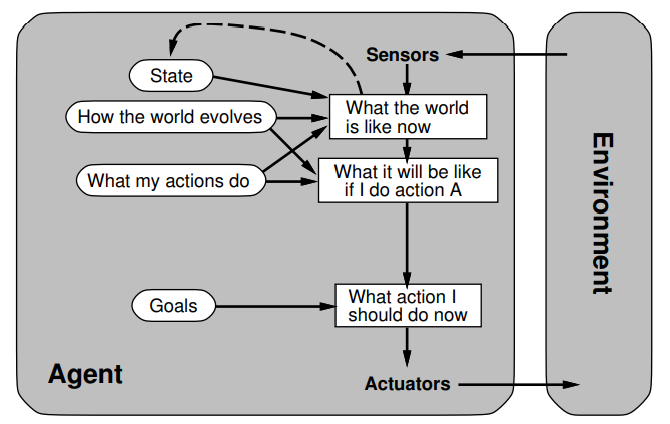
Goal-based agents
explicit goals
explicitly model:
the world
, goals, actions and their effects
Search and
planning
of action sequences
more flexible, better maintainability
Utility-based agents
evaluate goals with
utility function
use expected utility for decisions
resolve conflicting goals
- goals are weighted differently, the aim is to optimize a set of values
goal based agent vs. utility based agent
The goal based agent
can not deal with conflicting goals because it does not have a utility function.
Does not consider expected utility when planning - just goals, actions, effects.
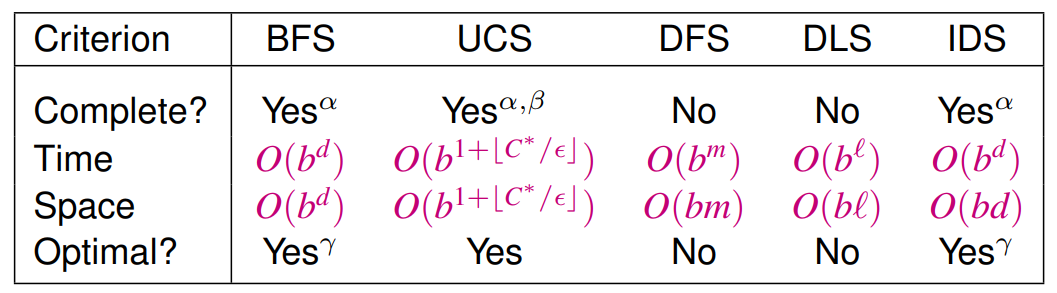
Uninformed search algorithms
Formal description of a search problem
Real World → Search problem → Search Algorithm
We define states, actions, solutions (= selecting a state space) through abstraction.
Then we turn states into nodes for the search algorithm.
Solution
A solution is a sequence of actions leading from the initial state to a goal state.
Initial state
Successor function
Goal test
path cost (additive)
All algorithms
Breadth-first search BFS
Frontier as queue.
The space and time complexity is too high.
Here the goal test is done at generation time.
Pseudocode
function BREADTH-FIRST-SEARCH(problem) returns a solution, or failure
node ← a node with STATE = problem.INITIAL-STATE, PATH-COST = 0
if problem.GOAL-TEST(node.STATE) then return SOLUTION(node)
frontier ← a FIFO queue with node as the only element
explored ← an empty set
loop do
if EMPTY?(frontier) then return failure
node ← POP(frontier)
add node.STATE to explored
for each action in problem.ACTIONS(node.STATE) do
child ← CHILD-NODE(problem, node, action)
if child.STATE is not in explored or frontier then
if problem.GOAL-TEST(child.STATE) then return SOLUTION(child)
frontier ← INSERT(child,frontier)
completeness
yes, if
b
is finite
time complexityO(bd)
in depth
If solution is at depth
d
and max branching is
b
:
Goal test at generation time:
1+b+b2+b3+...+bd=O(bd)
Goal test at expansion time:
1+b+b2+b3+...+bd+b
d
+
1
=O(bd+1)
space complexityO(bd)
solution optimality
yes, if step costs are identical
Uniform-cost search UCS
Fronier as priority queue ordered by costs.
Here the goal test is done at expansion time.
Pseudocode
function UNIFORM-COST-SEARCH(problem) returns a solution, or failure
node ← a node with STATE = problem.INITIAL-STATE, PATH-COST = 0
frontier ← a priority queue ordered by PATH-COST, with node as the only element
explored ← an empty set
loop do
if EMPTY?(frontier) then return failure
node ← POP(frontier)
if problem.GOAL-TEST(node.STATE) then return SOLUTION(node)
add node.STATE to explored
for each action in problem.ACTIONS(node.STATE) do
child ← CHILD-NODE(problem, node, action)
if child.STATE is not in explored or frontier then
frontier ← INSERT(child,frontier)
else if child.STATE is in frontier with higher PATH-COST then
replace that frontier node with child
completeness
Yes, if step-cost
≥ε
and
b
is finite
time complexityO(b⌊
C
∗/ε⌋+1)
in depth
if all step-costs
≥ε
and
C∗
is the cost of the optimal solution
then
d=⌊
ε
C
∗
⌋+1
and therefore
O(b⌊
C
∗
/ε⌋+1)
if goal-tested at expansion, not generation - therefore
bd+1
.
space complexityO(b⌊
C
∗/ε⌋+1)
solution optimality
Yes, if goal-tested at expansion.
Depth-first search DFS
Fronier as stack.
Much faster than BFS if solutions are dense.
Backtracking variant: store one successor node at a time - generate child node with
Δ
change.
completeness
No - only complete with explored-set and in finite spaces.
time complexityO(bm)
- Terrible results if
m≥d
.
space complexityO(bm)
solution optimality
No
Depth-limited search DLS
DFS limited with
ℓ
- returns a
cutoff
subtree/subgraph.
Pseudocode
function DEPTH-LIMITED-SEARCH(problem, limit) returns a solution, or failure/cutoff
return RECURSIVE-DLS(MAKE-NODE(problem.INITIAL-STATE), problem, limit)function RECURSIVE-DLS(node, problem, limit) returns a solution, or failure/cutoff
if problem.GOAL-TEST(node.STATE) then return SOLUTION(node)
else if limit = 0 then return cutoff
else
cutoff occurred? ← false
for each action in problem.ACTIONS(node.STATE) do
child ← CHILD-NODE(problem, node, action)
result ← RECURSIVE-DLS(child, problem, limit − 1)
if result = cutoff then cutoff occurred? ← true
else if result != failure then return result
if cutoff occurred? then return cutoff else return failure
completeness
No - May not terminate (even for finite search space)
time complexityO(bℓ)
space complexityO(bℓ)
solution optimality
No
Iterative deepening search IDS
Iteratively increasing
ℓ
in DLS to gain completeness.
Pseudocode
function ITERATIVE-DEEPENING-SEARCH(problem) returns a solution, or failure
for depth = 0 to ∞ do
result ← DEPTH-LIMITED-SEARCH(problem, depth)
if result 6= cutoff then return result
completeness
Yes - if
b
is finite
time complexityO(bd)
in depth
Only
b−1b
times more inefficient than BFS therefore
O(bd)
The total number of nodes generated in the worst case is:
(d)b+(d−1)b+...+(1)b=O(db)
Most of the nodes are in the bottom level, so it does not matter much that the upper levels are
generated multiple times. In IDS, the nodes on the bottom level (depth
d
) are generated once, those on the next-to-bottom level are generated twice, and so on, up to the
children of the root, which are generated
d
times.
Therefore asymptotically the same as DFS.
solution optimality
Yes, if step cost are identical
Overview
under the conditions:
α-
if
b
is finite
β-
if step costs
≥ε
for positive
ε
γ-
optimal with identical step costs
Does BFS expand as many nodes as DFS?
No - they have different frontier expansion strategies
but in some cases this can be true (as it depends on the graph).
But BFS expands nodes in the same tree level first while DFS expands all children of the same node until there aren't any left.
Is IDS optimal for limited tree depth?
No - it is only optimal with with identical step costs.
Does BFS expand at least as often as it has nodes?
BFS can goal check:
At expansion time - expands as often as it has nodes
at most
At generation time (more efficient - expands less than it has nodes)
Is BFS a special case of A* search?
If we set the heuristic to
h(n)=0
for every node and
g(n)=depth(n)
then A* acts as BFS:
f(n)=depth(n)
Choosing function with the lowest depth in the tree first.
Informed Search
consistency:
Admissible heuristics have a problem with graph search. Which one is it? How can this problem be solved?
Implies that
f
-value is
non-decreasing on every path
.
For every node
n
and its successor
n′
:
h(n)≤c(n,a,n′)+h(n′)
consistent
h(n)
for graph search is optimal
If
h(n)
decreases during optimal path to goal it is discarded by
graph-search
.
(But in tree search it is not a problem since there is only a single path to the optimal goal).
Solutions to problem:
consistency of
h
(non decreasing
f
on every path)
additional book-keeping
Given admissible heuristics
(h1,h2,…,hn)
. Which one is the best?
The heuristic that dominates the others:
For two admissible heuristics, we say
h2
dominates
h1
, if:
∀n:h2(n)≥h1(n)
Then
h2
is better for search.
admissibility
Optimistic, never overestimating, never negative.
h(n)≤f∗(n)
h(n)≥0
∀g
goals:
h(g)=0(follows from the above)
Prove: If the heuristic is consistent and
n′
is the neighbour of
n
, then
f(n′)≥f(n)
f(n′)=g(n′)+h(n′)=g(n)+c(n,a,n′)+h(n′)
f(n′)=g(n)+c(n,a,n′)+h(n′)≥g(n)+h(n)=f(n)(because of consistency)
f(n′)≥f(n)
Prove:
h(n)
is consistent for all consistent heuristics
h1,h2
if:
h(n):=max{h1(n),h2(n)}
h(n)=max{h1(n),h2(n)}
We know that
h1
and
h2
are consistent and therefore:
h1(n)≤c(n,a,n′)+h1(n′)
h2(n)≤c(n,a,n′)+h2(n′)
This means that:
h(n)=max{h1(n),h2(n)}≤max{c(n,a,n′)+h1(n′),h2(n)≤c(n,a,n′)+h2(n′)}≤
h
(
n
)max{
h
1
(
n
′
)
,
h
2
(
n
′
)}
+c(n,a,n′)
Which proves the consistency of
h(n)
.
Local Search
local beam search and its advantages / disadvantages
Idea
keep
k
states instead of just
1
to start searching from
Not running
k
searches in parallel: Searches that find good states recruit other searches to join them
choose top
k
of all their successors
Problem
often, all
k
states end up on same local hill
Solution
choose
k
successors randomly, biased towards good ones
Is local beam search a modification of the generic algorithm with cross-over?
yes - the genetic algorithm = stochastic local beam search + successors from pairs of states
hill climbing algorithm - how do we deal with its weaknesses?
Advantage: able of escaping shoulders
Disadvantage: getting stuck in loop at local maximum
Solution: Random-restart hill climbing = restart after step
Decision Trees
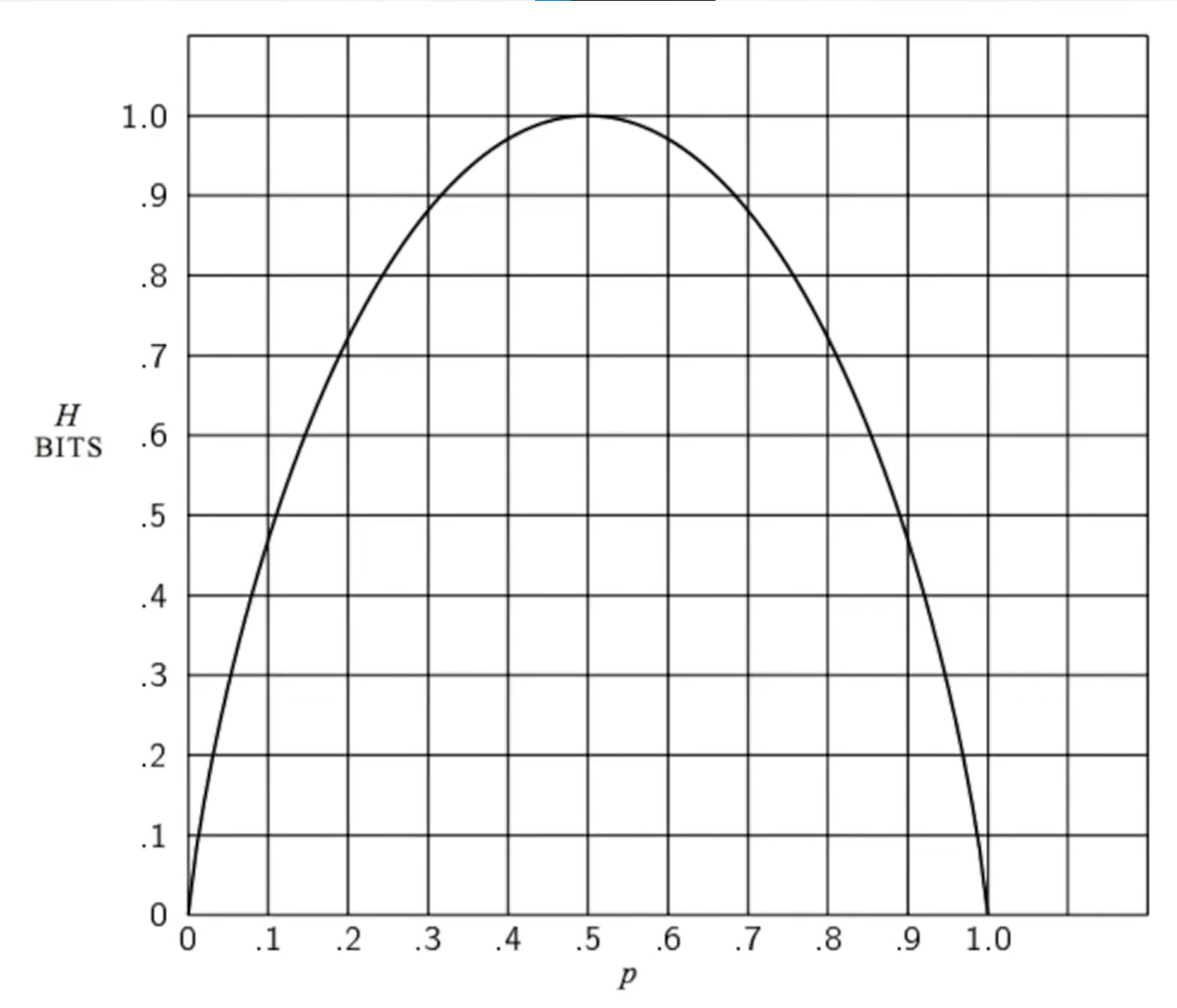
Why is entropy relevant for decision trees? How is
H(p1,p2)
defined?
We use entropy to determine the importance of attributes.
A lower entropy is better because it means
we have to ask less questions
(less testing = shallower tree) to reach a decison.
Information gain measured with entropy
Entropy measures uncertainty of the occurence of a random variable in [shannon] or [bit].
Entropy of a random variable
A
with values
v
k
each with probability
P(v
k
)
is defined as:
Wherew
j
,
k
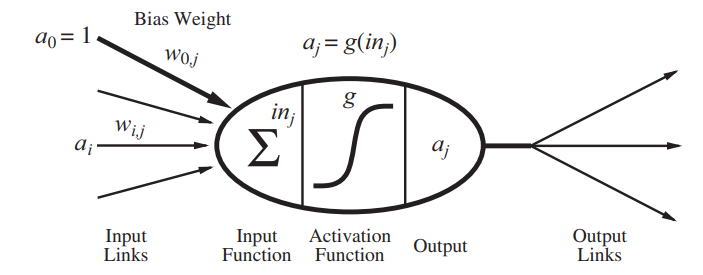
stands for the weight between the nodesjandk.
The idea is that the hidden nodejis "responsible" for some fraction of the errorΔ
k
in each of the output nodes to which it connects.
Thus, theΔ
k
values are divided according to thestrength
of the connection between the hidden node and the output node and are propagated back to provide the
Δ
j
values for the hidden layer.
hidden nodes: Back-propagation
We back propagate the errors from the output to the hidden layers.
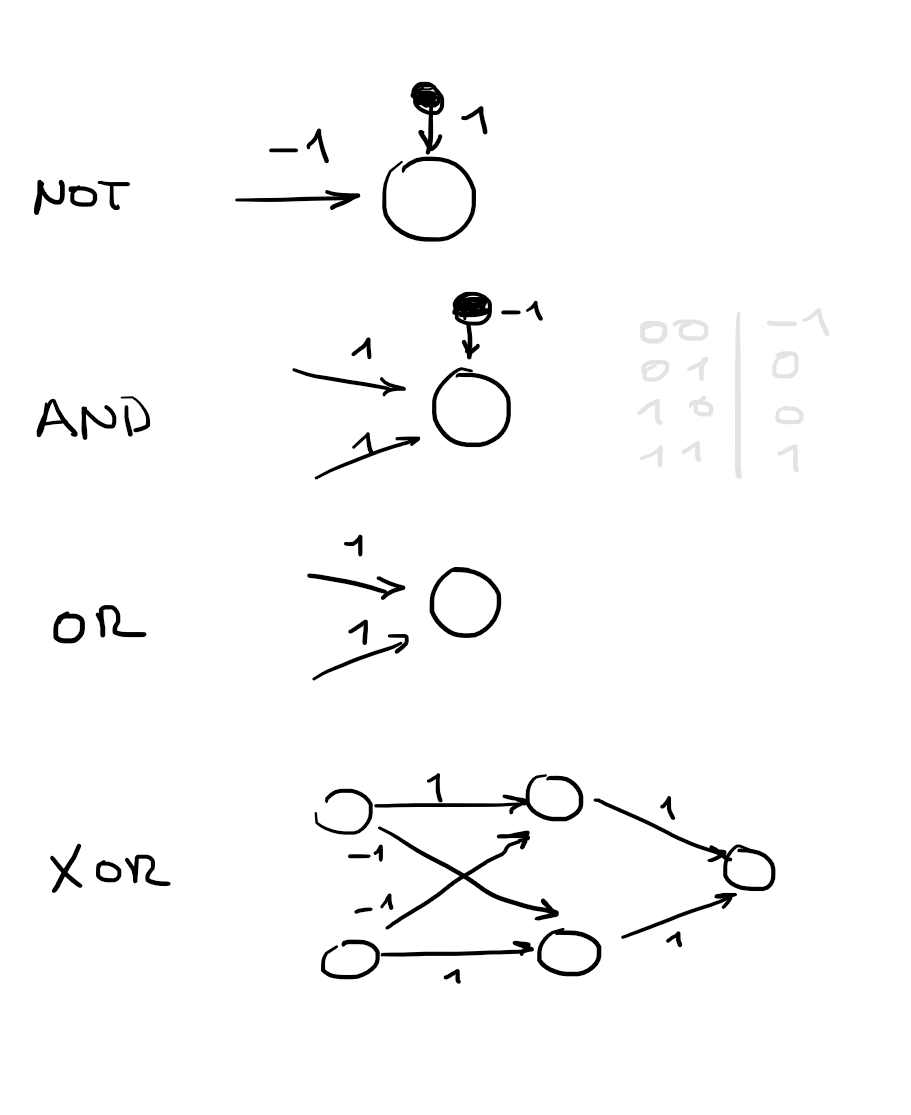
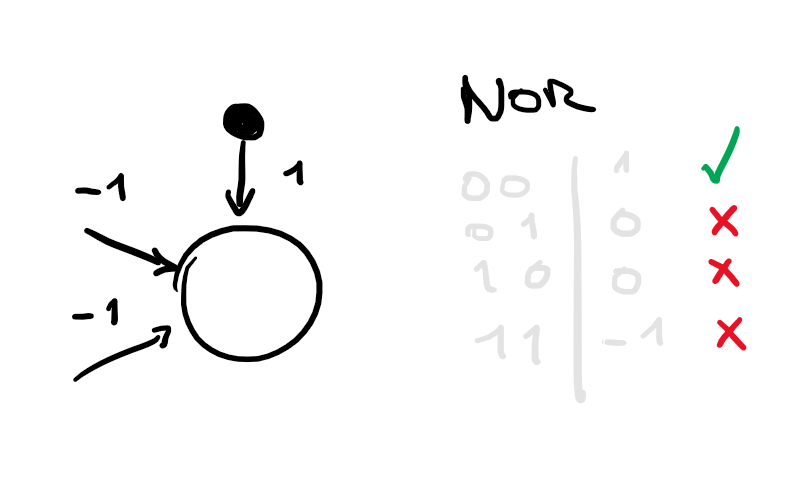
No hidden layers: Always represents a linear separator in the input space - therefore can not represent the XOR function.
Multilayer feed-forward neural networks
With a single, sufficiently large hidden layer (2 layers in total), it is possible to represent any continuous function of the
inputs with arbitrary accuracy.
in depth
Above we see a nested non-linear function as the solution to the output.
With the sigmoid function as
g
and a hidden layer, each output unit computes a soft-thresholded linear combination of several sigmoid
functions.
For example, by adding two opposite-facing soft threshold functions and thresholding the result, we can obtain a
"ridge" function.
Combining two such ridges at right angles to each other (i.e., combining the outputs from four hidden units), we
obtain a "bump".
With more hidden units, we can produce more bumps of different sizes in more places.
With two hidden layers, even discontinuous functions can be represented.
CSP
Cryptographic puzzle as a CSP
E G G
+ O I L
-------
M A Y O
Defined as a constraint satisfaction problem:
X={E,G,O,I,L,A,Y,X1,X2,X3}
D={0,1,2,3,4,5,6,7,8,9}
Constraints:
Each letter stands for a different digit:
Alldiff(E,G,O,I,L,A,Y)
G+L=O+10⋅
X
1
X
1+G+I=Y+10⋅
X
2,
X
2+E+O=A+10⋅
X
3,
X
3=M
The
X1,X2,X3
variables stand for the digit that gets carried over into the next column by the addition. Therefore
X1
stands for
10
in our unknown numeric system,
X2
stands for
100
,
X3
stands for
1000
.
Explain Backtracking Search for CSPs - why isn't it efficient?
CSPs as standard search problems
If we do not consider commutativity we have
n!dn
leafs else we have
dn
leafs.
The order of the assignments has no effect on the outcome. - Choosing a single variable variable in each tree level.
Backtracking search algorithm
Uninformed search algorithm (not effective for large trees).
Depth-first search:
chooses values for one unassigned variable at a time - does not matter which one because of commutativity.
tries all values in the domain of that variable
backtracks when a variable has no legal values left to assign.
Because its ineffective we use heuristics / General-purpose methods for backtracking search.
backtracking heuristics for choosing variables and values
Variable ordering: fail first
Minimum remaining values MRV
degree heuristic - (used as a tie breaker)
Value ordering: fail last
least-constraining-value - a value that rules out the fewest choices for the neighbouring variables in the constraint
graph.
Does a CSP with
n
variables and
d
values in its domain have
O(dn)
possible assignemnts?
Yes - this is because we are considering the commutativity of operatins and pick a single variable to assign for each tree
level.
Classical Planning
STRIPS vs. ADL
STRIPS
only positive literals in states
closed-world-assumption: unmentioned literals are false
Effect
P∧¬Q
means add
P
and delete
Q
only ground atoms in goals
Effects are conjunctions
No support for equality or types
ADL
positive and negative literals in states
open-world-assumption: unmentioned literals are unknown
Effect
P∧¬Q
means add
P
and
¬Q
delete
Q
and
¬P
goals contain
∃
quantor
goals allow conjunction and disjunction
conditional effects are allowed:
P:E
means
E
is only an effect if
P
is satisfied
Means
p
must remain
true
from time of action
A
to the time of action
B
.
else there is a
conflictC
.
ie:RightSock⟶RightSockOnRightShoe
open preconditions set
Minimizing open preconditions (= preconditions not achieved by an action in the plan)
Algorithm
Defines execution order of plan by searching in the space of partial-order plans.
Returns a
consistent plan
: without cycles in the ordering constraints and conflicts in the casual links.
Initiating empty plan
only contains the actions:
Start
no preconditions, effect has all literals, all preconditions are open
Finish
no open preconditions, effect has no literals.
ordering constraint:
Start≺Finish
no casual links
Searching
2.1 successor function: repeatedly choosing next possible state.
Chooses an open precondition
p
of action
B
and generates a successor plan (subtree) for every consistent way of choosing an action
A
that achieves
p
.
2.2 enforce consistency by defining new casual links in the plan:
A⟶pB,A≺B
IfAis new:Start≺A≺Finish
2.3 resolve conflicts
add
(B≺C)∧(C≺A)
2.4 goal test
because only consistent plans are generated - just check if preconditions are open.
Yes - because only consistent plans are generated the goal test is checking if any preconditions are open. If the goal is not
reached it adds successor states.
all types of state space search algorithms
Totally ordered plan searches
in strictly linear order.
The state space is finite without function symbols - any graph search algorithm can be used.
Variants:
progression planing: initial state
→
goal
regression planing: initial state
←
goal
(possible because of declarative representation of PDDL and strips)
Partial-order Planning
Order is not specified: can place to actions into a plan without specifying which one comes first.
Search in space of partial-order-plans.
consistent plans (in partial order planning) and solutions
solutionto a declared planning-problem= a plan
Any action sequence that when executed in the initial state - results in a state that satisfies the goal.
Every action sequence that maintains the partial order is a solution.
(The in POP algorithm the goal is therefore only defined by not having open preconditions)
Consistent actions
Chosen actions should not undo the progress made.
Consistent plans (in partial order planning)
Must be free of
contradictions / cycles
in the
ordering constraint set
:
(A≺B)∧(B≺A)
Must be free of
conflicts
in the
casual links set
: precondition
p
must remain
true
if
A⟶pB
.
order constraint and when does it lead to problems?
A≺B
Action
A
must be executed before action
B
.
Must be free of
contradictions/cycles
:
(A≺B)∧(B≺A)
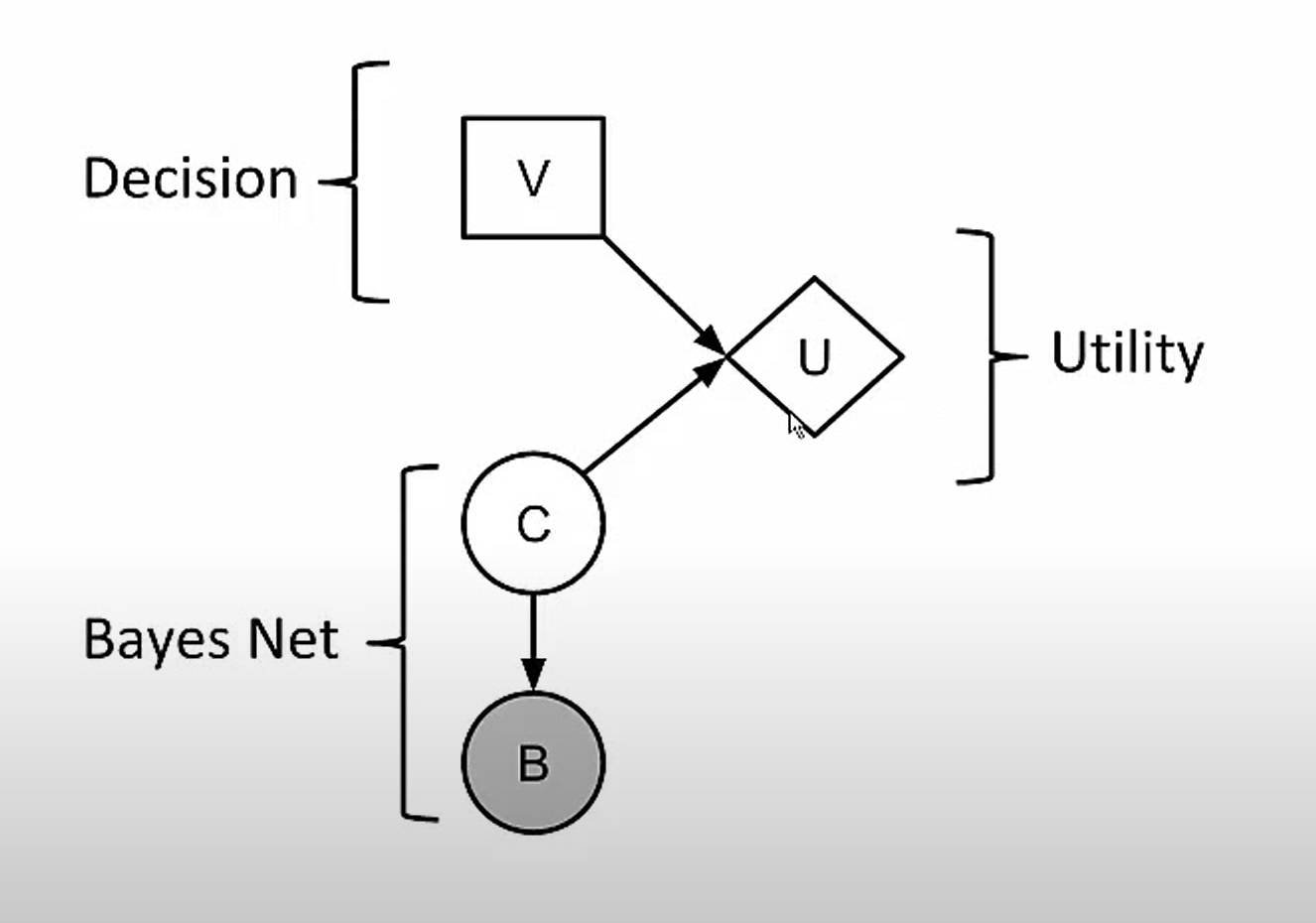
Utility
risk aversion: What would the risk averse agent prefer
U(L)
or
U(SEMV(L))
?
as we gain more money, its utility does not rise proportionally.
The Utility for getting your first million dollars is very high, but the utility for the additional million is smaller.
For the risk averse agent:
U(L)<U(S
EM
V
(L))
the utility of being faced with that lottery
<
than the utility of being handed the expected monetary value of the lottery with absolute certainty
expected utility, maximum estimated utility
Expected Utility (average)
Its impicit that
s′
can follow from the current state
s
.
EU(a∣e)=
∑
s′P(RESULT(a)=s′∣a,e)⋅U(s′)
Sum of: Probability of state occuring after action times its utility
Principle of maximum expected utility MEU
rational agent should choose the action that maximizes the agents expected utility
action =aargmaxEU(a∣e)
The axioms of utility theory
Constraints on rational
preferences
of an agent
Notation:
A≻B
agent prefers state
A
over state
B
A∼B
agent is indifferent between state
A
and state
B
A≿B
one of the above
Constraints
Orderability
The agent must have a preference.
(A≻B)xor(B≻A)xor(A≿B)
Transivity
(A≻B)∧(B≻C)⇒(A≻C)
Continuity
A≻B≻C⇒∃p:[p,A;1−p,C]∼B
Substitutability
If agent is indifferent to
A
and
B
then agent is indifferent to complex lotteries with same probabilities.
A∼B⇒[p,A;1−p,C]∼[p,B;1−p,C]
Monotonicity
Agent prefers a higher probability of the state that it prefers.
A≻B⇒(p>q⇔[p,A;1−p,B]≻[q,A;1−q,B])
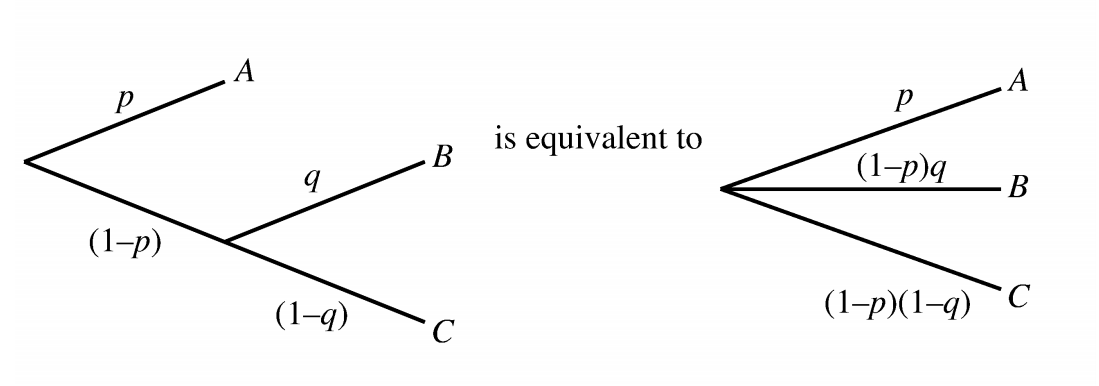
Decomposability
Compound lotteries can be reduced to simpler ones.