Able to represent any continuous function with arbitrary accuracy
Above we see a nested non-linear function as the solution to the output.
With the sigmoid function as
g
and a hidden layer, each output unit computes a soft-thresholded linear combination of several sigmoid functions.
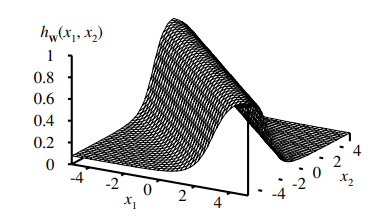
For example, by adding two opposite-facing soft threshold functions and thresholding the result, we can obtain a "ridge"
function.
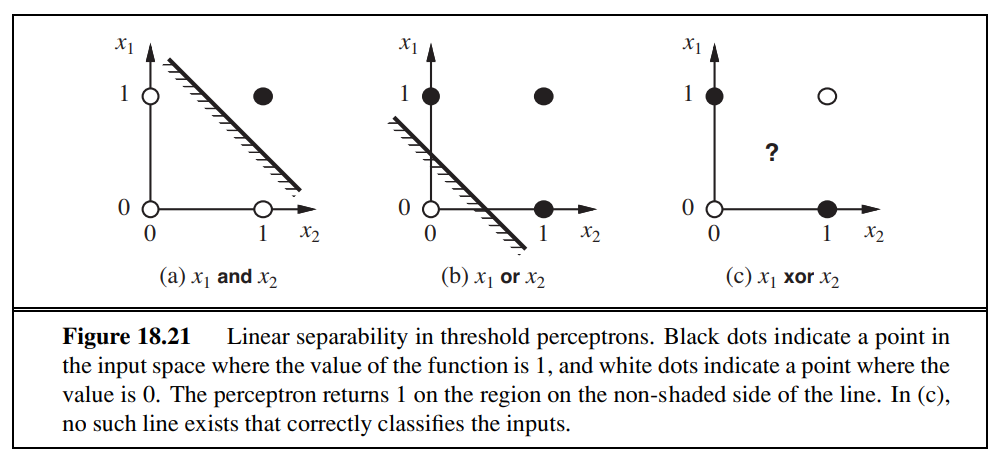
1 layer (no hidden layer): all linearly seperable functions
2 layers: all continuous function, can be as precise as one wants
3 layers: all functions
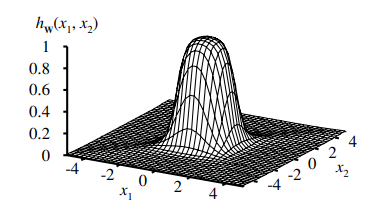
Combining two such ridges at right angles to each other (i.e., combining the outputs from four hidden units), we obtain a
"bump".
With more hidden units, we can produce more bumps of different sizes in more places.
In fact, with a single, sufficiently large hidden layer, it is possible to represent any continuous function of the inputs with
arbitrary accuracy. With two layers, even discontinuous functions can be represented.
Unfortunately, for any
particular
network structure, it is harder to characterize exactly which functions can be represented and which ones cannot.
Multi-Layer Perceptron Learning
💡
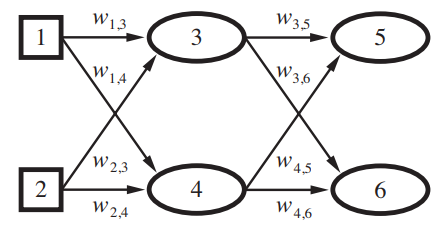
The index
k
ranges over nodes in the output layer. The index
j
ranges over nodes in the hidden layer.
We want to learn the function
inputx=(x1,x2,…,xn)
outputhw(x)=(ak,ak+1,…an)
We have a training set with examples
(x,y)
.
x=(x1,x2,…,xn)
y=(y1,y2,…,yn)
We want to minimize the loss (= the sum of gradient losses for all output nodes).
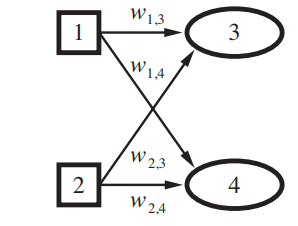
Wherewj,kstands for the weight between the nodesjandk.
The idea is that the hidden nodejis "responsible" for some fraction of the errorΔkin each of the output nodes to which it connects.
Thus, theΔkvalues are divided according to thestrengthof the connection between the hidden node and the output node and are propagated back to provide theΔjvalues for the hidden layer.
hidden nodes: Back-propagation
We back propagate the errors from the output to the hidden layers.
What is the ideal network structure for each problem?
The usual approach is to try several and keep the best. → "cross-validation"
big networks will memotize all examples and form a large lookup table but wont generalize well to unseen inputs. (It has been observed
that very large networks do generalize well as long as the weights are kept small.)
Networks are subject to overfitting when there are too many parameters in the model
If we want to consider networks that are not fully connected, then we need to find some effective search method through the very large space
of possible connection topologies.
optimal brain damage algorithm
Begins with a fully connected network and removes connections (or units) from it.
The network is then retrained, and if its performance has not decreased then the process is repeated.
tiling
growing a larger network from a smaller one.
Applications of Neural Networks
Prediction of stock developments
Prediction of air pollution (e.g., ozone concentration)
(better than physical/chemical, statistical models)
Prediction of electric power prizes
Desulfurization in steel making
Pattern recognition (e.g., handwriting)
Face recognition
Speech recognition
Handwritten Digit Recognition (OCR)
Different learning strategy performances:
3-nearest-neighbor classification: 2.4% error
2 layer MLP (400–300–10 units): 1.6% error
LeNet (1989;1995+): 0.9% error, using specialized neural net family
current/recent best: ≈ 0.23% error, multi-col. convoluted deep NNs
Deep Learning
Hierarchical structure learning: NNs with many layers
Feature extraction and learning (un)supervised
Problem: requires lots of data
Push for hardware (GPUs, designated chips): “Data-Driven” vs. “Model-Driven” computing
Advantages and Disadvantages of Neural Networks
Pros
Less need for determining relevant input factors
Inherent parallelism
Easier to develop than statistical methods
Capability to learn and improve
Useful for complex pattern recognition tasks, "unstructured" and "difficult" input (e.g., images)
Fault tolerance
Cons
Choice of parameters (layers, units) requires skill
Requires sufficient training material
Resulting hypotheses cannot be understood easily
Knowledge implicit (subsymbolic representation)
Verification, behavior prediction difficult (if not impossible)