MPI
CLI commands for compiling
On batch systems:
slurm srun,sbatchmpicc, mpif77, mpif90 – like cc, f77, f90 mpirun –np <procs> <program> … <program options> // -np means only one nodeStarts
<procs>number of MPI processes executing same<program>on available resources (processors, cores, threads, ...)<program>executes:MPI_Init(&argc,&argv); // sets up internal data structures, incl: ... MPI_Comm_size(MPI_COMM_WORLD,&size);
https://hpc-tutorials.llnl.gov/mpi/
https://curc.readthedocs.io/en/latest/programming/MPI-C.html
Models
Message-passing model
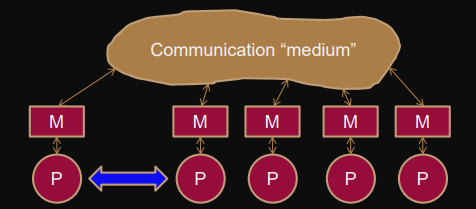
Message-passing parallel abstraction / programming model
“Message passing paradigm”
“shared-nothing programming model”
Finite set of processes with local memory, program (no shared memory).
Explicit communication: Sending, receiving messages.
- Fully connected network: all processes are connected and can communicate.
- Communication can be one-sided (otherwise always both parties are involved).
- We abstract over medium (physical network properties = communication network) and routing algorithm.
No implicit synchronization between processes (nothing else is shared).
Advantages
All data exchange is explicit, deterministic
We known: when, what, where
Reasoning about correctness, no race conditions
Performance model
Communication = expensive (do it rarely and with large messages)
Local computation = cheap
MPI model
Message passing interface MPI
Library
Standard for parallel programming in given model (no performance model).
Used for distributed applications with non-trivial algorithms that require communication.
Implemented efficiently and can coexist with other parallel interfaces (OpenMP, threads, ...)
communication inside library isolated from communication outside library.
support SPMD, MIMD
= loosely synchronous, all processes run the same program, processes distinguish themselves by their rank (process ID)
MIMD consists of application with different compiled programs.
(In this lecture only SPMD)
MPI programming model
Physical processors can run multiple MPI processes (but usually only one, therefore static).
Binding processes to processors is not part of the MPI.
- Processes with rank in communication domain, can communicate.
- ≥1 communication domains possible (created relative to default domain).
- Processes operate only on local data - all communication explicit (and also reliable, ordered).
-
Three basic communication models:
- Point-to-point communication
- One-sided communication
- Collective operations
- Communication domains can reflect physical topology of network
- No communication cost model
MPI communication models
-
Point-to-point communication (different modes)
non-local and local completion
-
One-sided communication (different synchronization mechanisms)
local completion
-
Collective operations (can be non-blocking)
non-local completion
-
Other operations (not in this lecture)
parallel I/O, spawning processes, virtual topologies, ...
Rule:
All messages sent must be received, else
MPI_Finalize()
may not terminate because there are pending communications.
Deadlocks in MPI
Possible forms:
- All processes waiting for event that can not happen
-
Process
waiting for
,
waiting for
-
Process
waiting for
,
waiting for ,
Unsafe programs in MPI
An MPI program is
unsafe
if termination depends on implementation of library (ie. buffering of
MPI_Send
), concrete context (ie. processes and communication).
It may or may not deadlock.
Not portable (different libraries implemented differently).
MPI Concepts
Communicator objectcomm(= communication domain)
Communicators are static objects that cannot change.
Processes cannot be moved around in them - we can only create new comms from old ones (and free them after the usage).
Predefined communicators:
MPI_COMM_WORLD
= Initial communicator, contains set of processes that all can communicate with eachother, communication context.
MPI_COMM_SELF
= Singleton communicator with only process (itself)
MPI_COMM_NULL
= No or invalid communicator
Rules:
- Communication in MPI is always relative to comm
- Process ranks = id + communicator they are in
Handle
special MPI typedef.
Handles are opaque (not transparent) - the internal datastructures can only be accessed through the operations defined on them.
TL;DR: they are the prefixes of library routines.
ie.MPI_COMM_WORLDhas handleMPI_Command is used to access the current comm of a process and perform operations on it.
MPI handles
MPI_Comm- communicators (global)
can be manipulated with collective operations (ie.
MPI_Comm_split
,
MPI_Comm_dup
, ...)
MPI_Group- process groups (local)
ordered set of processes used for one-sided communication
can be manipulated locally
MPI_Group_union MPI_Group_intersection MPI_Group_incl, MPI_Group_excl MPI_Group_translate_ranks MPI_Group_compare ...
MPI_Win- windows for one-sided communication (distributed)
MPI_Datatype- Description of data layouts
describe unit of communication.
MPI_Op- Binary operations
MPI_Request- Request handle for point-to-point
MPI_Status- Communication status
Information on what was received.
MPI_Errhandler
Basic library routines
Function arguments
OUT arguments pointers
IN arguments pointers, values
Handles special MPI typedef’s
Example
int MPI_Reduce( void *sendbuf, // IN void *recvbuf, // OUT int count, // IN MPI_Datatype datatype, // IN (handle) MPI_Op op, // IN (handle) int root, // IN MPI_Comm comm // IN (handle) );
Error-status
Good practice: checking error status
err = MPI_<some MPI function>(…); // returns ie. MPI_SUCCESSList of all error codes
One can also define new ones.
MPI_SUCCESS MPI_ERR_BUFFER MPI_ERR_COUNT MPI_ERR_TYPE MPI_ERR_TAG MPI_ERR_COUNT MPI_ERR_RANK … MPI_ERR_UNKNOWN MPI_ERR_TRUNCATE // sometimes returned for point-to-point … MPI_ERR_WIN MPI_ERR_LASTCODE
Calling with try-catch similar function
errhandle
: handle to function that will be called on error (but usually it doesn’t work and the function will just abort)
MPI_Comm_set_errhandler(comm,errhandle)First and last coll of MPI in application (only called once)
MPI_Init(&argc,&argv);
MPI_Finalize();Size of communicator and process rank
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);Example: Check rank and size of communicator
#include <mpi.h>int main(int argc, char *argv[]) { int rank, size; MPI_Init(&argc, &argv); // first call, performed by all -> MPI_Initialized(flag)MPI_Comm_size(MPI_COMM_WORLD, &size); MPI_Comm_rank(MPI_COMM_WORLD, &rank); // Who am I?fprintf(stdout,"Here is %d out of %d\n", rank, size);MPI_Finalize(); // last call, performed by all -> MPI_Finalized(flag) return 0; }
Example: Assign task to processor
MPI_Comm_size(MPI_COMM_WORLD,&size); MPI_Comm_rank(MPI_COMM_WORLD,&rank);if (size<10 || size>1000000) MPI_Abort(comm,errcode);if (rank==0) { // code for rank 0; may be special } else if (rank%2==0) { // remainder even ranks } else if (rank==7) { // another special one } else { // all other (odd) processes… }
Benchmarking
MPI_Barrier(MPI_COMM_WORLD); // synchronize processes (semantically)
double point_in_time = MPI_Wtime(); // get timeFreeing memory for communicators
Frees any allocated communicator after use.
MPI_Comm_free(&comm);(MPI_COMM_WORLD,MPI_COMM_SELFcan not be freed)
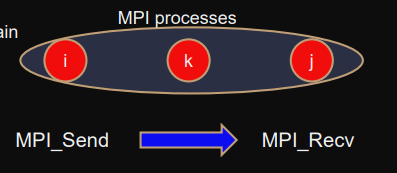
Point-to-point communication
Point-to-point communication
Two processes communicate explicitly.
Both involved as: sender, receiver.
General properties
Deadlock free Message is eventually received (with matching operations)
Non-overtaking Messages sent to the same destination arrive there in sent order.
Different order can be enforced with tags.
Reliable Messages don’t get lost, content can be trusted.
Sending
Sender
Completion is non-local:
Call return may depend on receiving rank having initiated receive operation.
The local completion depends on implementation (can be done so that the sender returns fast).
Operation is blocking:
MPI_Send
returns back to caller of function, when
sendbuf
is safe to be reused again (not necessarily when message is received).
Operation is non-overtaking:
Messages sent to the same destination arrive there in sent order.
MPI_Send(
void *sendbuf, // pointer to data to be sent
int count, // number of units to be sent
MPI_Datatype datatype, // datatype of unit (unchecked, programmers responsibility)
int dest, // rank of receiver
int tag, // type of message
MPI_Comm comm // communicator (in which both are placed)
);Convention: Buffer size must be divisible by 3.
Multiple implementations in library
MPI_Send
standard - returns when buffer can be used
MPI_Ssend
synchronous - returns when buffer can be used and recipient received
MPI_Bsend
buffered - returns immediately (also copies data to immediate buffer)
MPI_Rsend
ready - precondition: receive must have been posted (acknowledgement)
MPI_Isend
immediate - returns immediately
Receiving
Recipient
Operation is blocking:
MPI_Recv
returns back to caller of function, when message has been received (Can take forever → deadlock).
Then stores status in given pointer (ie. status is
MPI_ERR_TRUNCATE
if buffer of receiver is not large enough).
MPI_Recv(
// ... same as above
MPI_Status *status // status of received message
);Wildcards:
Can accept message from any rank with
MPI_ANY_SOURCE
and any tag with
MPI_ANY_TAG
(but leads to non-determinism).
Convention: Buffer size must be divisible by 3.
Multiple implementations in library
MPI_Rece
Standard - blocking
MPI_IRecv
Immediate - nonblocking
Counting received data
MPI_Get_count(status,datatype,count);
MPI_Get_elements(status,datatype,count);
Both are equivalent for basic datatypes such as
MPI_INT
, ...
Example
#include <assert.h>int recvbuf[600]; // large enough count = 600; // equal or larger to what is being sentMPI_Status status; success = MPI_Recv(recvbuf,count,MPI_INT,2,THISMSG,comm,&status);int realcount; MPI_Get_count(status,MPI_INT,&realcount); // possibly realcount<count; assert(realcount<=count);
Sources of non-determinism
Deterministic messages are non-overtaking (messages sent arrive at destination in same order).
-
Wildcards
MPI_Recv(..., MPI_ANY_SOURCE, MPI_ANY_TAG, ...);Any message, from any sender at any time
-
Probe
MPI_Probe(source,tag,comm,&status); // blocking MPI_Iprobe(source,tag,comm,&flag,&status); // nonblockingStops blocking, when message with given source, and tag in comm have arrived and is ready for reception (
MPI_Recv()then can be called without blocking) .flag == 1means message with source and tag ready for reception in comm (thenstatusis also updated).Example
#include <assert.h>MPI_Status status; int tag = 777;MPI_Probe(MPI_ANY_SOURCE,tag,comm,&status); // blocking call - returns when message with tag 777 has arrived assert(status.MPI_TAG==tag);int source = status.MPI_SOURCE; int count; MPI_Get_count(status,MPI_INT,&count); // get count recvbuf = (int*)malloc(count*sizeof(int)); // allocate MPI_Recv(recvbuf,count,MPI_INT,source,tag,comm,MPI_STATUS_IGNORE);
Examples
Examples
Example: Sending double and integer
int a[N]; float area; MPI_Send(a,N,MPI_INT,j,TAG1,MPI_COMM_WORLD); // send a MPI_Send(&area,1,MPI_FLOAT,j,TAG2,MPI_COMM_WORLD); // send area
int a[N]; float area; MPI_Recv(a,N,MPI_INT,j,TAG1,MPI_COMM_WORLD); // receive a MPI_Recv(&area,1,MPI_FLOAT,j,TAG2,MPI_COMM_WORLD); // receive area
Example: Sending 500 integers
Process2 -500 integers → Process500
int THISMSGTAG = 777; // message TAG int count = 500;if (rank==2) { int sendbuf[500] = {<500 integers>}; MPI_Send(sendbuf,count,MPI_INT,4,THISMSGTAG,comm);} else if (rank==4) { int recvbuf[count + 100]; // equal or larger than what is being sent MPI_Status status; success = MPI_Recv(recvbuf,count,MPI_INT,2,THISMSGTAG,comm,&status);}“Start reception of message
THISMSGTAGfrom rank 2 incomm, store result inrecvbuf, at most 600 consecutive integers (otherwisesuccess==MPI_ERR_TRUNCATE)
Example: Non matching types
Here the types dont match.
Communication would take place but its bad practice.
Type could be lost → Processors could have different endianness.
double a; MPI_Send(&a,1,MPI_DOUBLE,j,1111,MPI_COMM_WORLD);
double a; MPI_Recv(a,sizeof(double),MPI_BYTE,i,1111,MPI_COMM_WORLD,MPI_STATUS_IGNORE);
Synchronization with 0-count message
Example: One sided synchronization
MPI processes are not synchronized - messages can be used.
Receiving process cannnot proceed before message arrives.
MPI_Send(NULL,0,MPI_INT,dest,tag,comm); // 0 count message ↓ MPI_Recv(NULL,0,MPI_INT,source,tag,comm,&status);
Example: Pairwise synchronization
MPI_Ssend(NULL,0,MPI_INT,dest,tag,comm); // blocks until message received ↓ MPI_Recv(NULL,0,MPI_INT,source,tag,comm,&stat);
Safe programming
Unsafe programming
It’s possible that the program does not lead to a deadlock if multiple processors MPI_Send() to eachother simultaniously.
The exact conditions of local-completion depend on the implementation in the library.
Example: 2d, 5-point stencil algorithm (unsafe)
Given matrix :
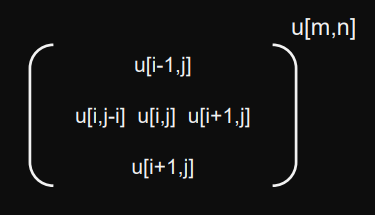
Special conditions on borders:
i=0,i=m-1,j=0,j=n-1Sequential solution:
per iteration
Parallelization
We split the matrix into equal sized submatrices and perform each locally.
Borders of each matrix must read values from other submatrices → use messages.
Work: per process
update is.
two messages offor columns
two messages offor rows
Parallel algorithm
Assume we are looking at view of rank .
-
“Halo-exchange of depth 1”
- Receive rows and columns of 4 neighbour-processes.
- Send rows and columns to 4 neighbour-processes.
- Parallel stencil computation
If first receiving, then sending → deadlock
Each receive blocks until send operation starts (this never happens if multiple interdependent blocks receive simultaniously)
If first sending, then receiving → unsafe
Deadlock only based on message size and library implementation.
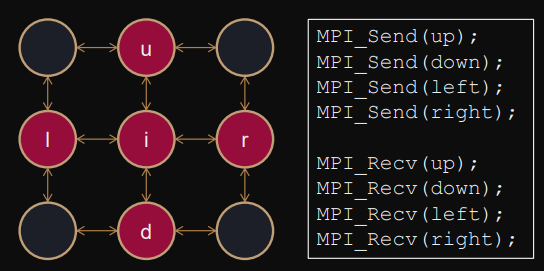
-
“Halo-exchange of depth 1”
Example: 1d-stencil (unsafe)
Arrays
aandbdistributed in blocks over MPI processesfor (i=n[j]; i<n[j+1]; i++) { b[i] = a[i-1]+a[i]+a[i+1]; }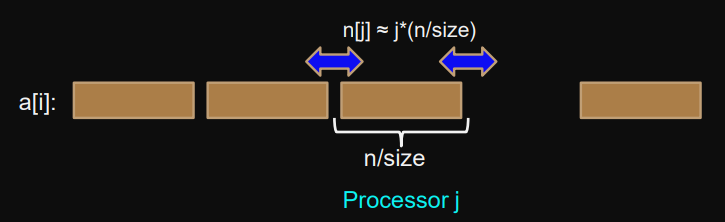
-
Receiving before sending
float *a = malloc((n/p+2)*sizeof(float)); a += 1; // offset, such that -1 and n/p can b addressed// step 1 [1; size-1] if (rank>0) { MPI_Recv(&a[-1],1,MPI_FLOAT,rank-1,999,comm,&status); // <-- DEADLOCK MPI_Send(&a[0],1,MPI_FLOAT,rank-1,999,comm); }// step 2 [0; size-2] if (rank<size-1) { MPI_Recv(&a[n/p],1,MPI_FLOAT,rank+1,999,comm,&status); // <-- DEADLOCK MPI_Send(&a[n/p-1],1,MPI_FLOAT,rank+1,999,comm; }for (i=0; i<n/p; i++) { b[i] = a[i-1]+a[i]+a[i+1]; }Deadlock: Processes try to receive without sending blocks.
-
Sending before receiving
Is possible without deadlocks based on the implementation :
We don’t have to wait until the message was received but until the buffer is safe to use again.
Unsafe programming.
-
Receiving before sending
Safe programming
A) symmetry breaking (scheduling)
Problem: can lead to serialization, difficult with odd number of processes.
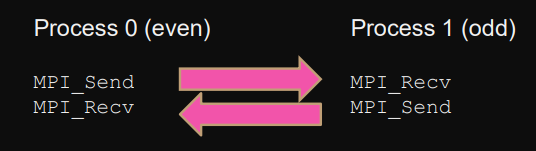
B) usingMPI_Sendrecvto combine sending and receiving.
Performance advantage: utilitzes fully bidirectional communication network.
MPI_Sendrecv(
// send
void *sendbuf, int sendcount, MPI_Datatype sendtype, int dest, int sendtag,
// receive
void *recvbuf, int recvcount, MPI_Datatype recvtype, int source, int recvtag,
MPI_Comm comm, MPI_Status *status
);In depth
Is equivalent to
// immediate send MPI_Request request; MPI_Irecv(recvbuf,recvcount,recvtype,source,recvtag,comm,&request);// receive (wait until received) MPI_Send(sendbuf,sendcount,sendtype,dest,sendtag,comm);// wait (until sent message received) MPI_Wait(&request,status);
Example: 1d-stencil (safe)
Arrays
aandbdistributed in blocks over MPI processesfor (i=n[j]; i<n[j+1]; i++) { b[i] = a[i-1]+a[i]+a[i+1]; }float *a = malloc((n/p+2)*sizeof(float)); a += 1; // offset, such that -1 and n/p can b addressed// step 1 [1; size-1] if (rank>0) { MPI_Sendrecv(…,rank+1,…,rank-1,…); }// step 2 [0; size-2] if (rank<size-1) { MPI_Sendrecv(…,rank-1,…,rank+1,…); }for (i=0; i<n/p; i++) { b[i] = a[i-1]+a[i]+a[i+1]; }
Example: Hillis-Steele prefix sums algorithm (safe)
Round , each process :
- receives partial sum from
- sends partial result to
MPI_Sendrecv(…, rank+2^k, …, rank-2^k, …);

C) Immediate operationsMPI_Isend,MPI_Irecv(nonblocking operations)
Immediate, non-blocking, local completion.
Returns immediately (but initiates operation).
Can be used to prevent deadlocks and improve performance (overlapping communication with computation).
Sending
MPI_Isend(sendbuf,…,rank,tag,comm,request);sendbuf
can not be reused until completion has been checked.
In depth
MPI_Status status; MPI_Request request; MPI_Isend(sendbuf,…,comm,&request);// check progress information MPI_Test(&request,flag,&status);If
flag == 1then operation has completed.MPI_Isend(sendbuf,…,comm,&request); MPI_Wait(&request,&status);Is equivalent to
MPI_Send();
Receiving
MPI_Irecv(recvbuf,…,rank,tag,comm,request);Messages are received after completion.
Example: 2d, 5-point stencil algorithm (safe)
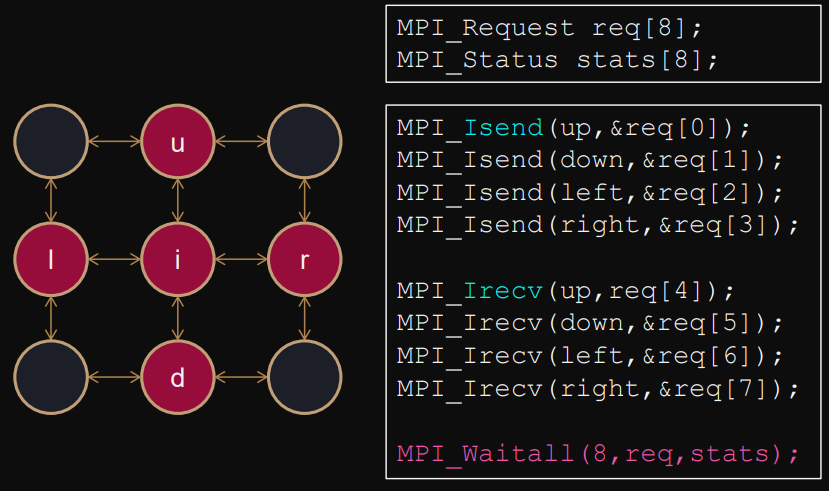
Test and completion calls
MPI_Test(&request,flag,&status); // update status in flag (boolean)
MPI_Wait(&request,&status); // completion non-localMPI_Waitall(number,array_of_requests,array_of_statuses)
MPI_TestallMPI_Waitany
MPI_TestanyMPI_Waitsome
MPI_TestsomeDatatypes
basetype *sendbuf;
sendbuf = malloc(count*extent*sizeof(basetype));
MPI_Send(sendbuf,count,datatype,dest,tag,comm);Goal: Not communicating elements one after the other with multiple small messages but loading data into large consecutive buffer.
Datatypes
Describe unit of communication.
They have a size, extent (footprint), internal structure and order.
New types can also be derived.
MPI_Type_get_extent(datatype,&lb,&extent); // difference between first and last byte
MPI_Type_size(datatype,&bytes); // number of bytes occupiedMPI_Type_contiguous(count,basetype,&newtype);
MPI_Type_vector(count,blocksize,stride,basetype,&newtype);
MPI_Type_create_indexed_block(count,block,displs,basetype,&newtype);
MPI_Type_indexed(count,blocks,displs,basetype,&newtype);
MPI_Type_create_struct(count,blocks,displs,etypes,&newtype); // complicated
...MPI_Type_commit(&newtype); // sets newtype as new datatype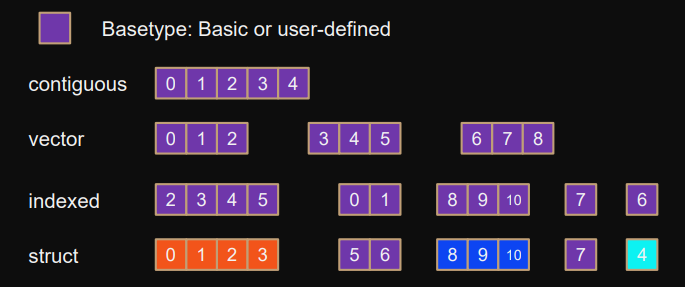
One-sided communication
One-sided communication
Only one process is explicitly involved.
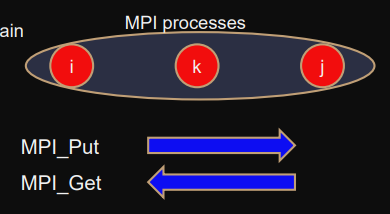
General properties
non-blocking, local-completion
data on target is exposed in communication-window and is addressed with “relative displacement”.
Window, Epoch model
Communication window
global objects, memory processes accessed in one-sided communication.
The target address of origin and target must be different (to disallow race conditions).
MPI_Win_create(
base, // given by communicator
size,
dispunit, // displacement unit
info, // special (key,value) that can influence properties -> set MPI_INFO_NULL
comm, // communicator
&win // address of window
);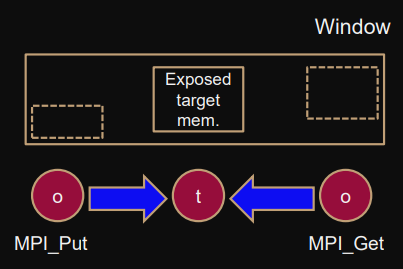
Origin, Target
Origin
Initiates communication, provides arguments (alone).
MPI_Put(
obuf, // buffer
ocount,
otype,
target,
tdisp, // displacement = base + targetdispunit * targetdisp
tcount,
ttype,
win
);Target
Not involved in communication.
MPI_Get(
obuf,
ocount,
target,
tdisp,
tcount,
ttype,
win
);MPI_Accumulate( // atomic operation, concurrency allowed
obuf,ocount,
otype,
target,tdisp,tcount,ttype,
op,
win
);Examples
Example: Binary search
l = -1; // lower boundary u = n; // upper boundarydo { m = (l+u)/2; // half if (x<A[m]) { u = m; // upper <- half } else { l = m; // lower <- half } } while (l+1<u);i = l;Value found in sorted array in steps.
Note: binary search can’t be sped up significantly by parallel processing.
Each process gets a block of size in .
All processes make their block accessible to others in communication window
int p; int r; // rank MPI_Comm_size(comm,&p); MPI_Comm_rank(comm,&r);// create window for other processes A = (int*)malloc(n/p*sizeof(int)); … // init block (see later) MPI_Win_create(A,(n/p)*sizeof(int),sizeof(int),MPI_INFO_NULL,comm,&win);l = -1; // lower boundary u = n; // upper boundary mA; // equivalent of A[m] in this process' blockdo { m = (l+u)/2; // halfMPI_Win_fence(MPI_NO_PRECEDE,win); t = m/p; // target process tix = m%p; // index at target MPI_Get(&mA,1,MPI_INT,t,tix,1,MPI_INT,win); MPI_Win_fence(MPI_NO_SUCCEED,win);if (x<mA) { u = m; // upper <- half } else { l = m; // lower <- half } } while (l+1<u);i = l;Alternatively, instead of fences one could use:
MPI_Win_lock(MPI_LOCK_SHARED,t,0,win); tix = m%p; // index at target MPI_Get(&mA,1,MPI_INT,t,tix,1,MPI_INT,win); MPI_Win_unlock(t,win);
Example: Merge
merge(A,n,B,m,C)Sorted arrays distributed in evenly sized blocks .
Elements in process are than process .
Each process stores a block of
Cof size .Algorithm:
-
Use co-ranking algorithm.
All processes co-rank in parallel.
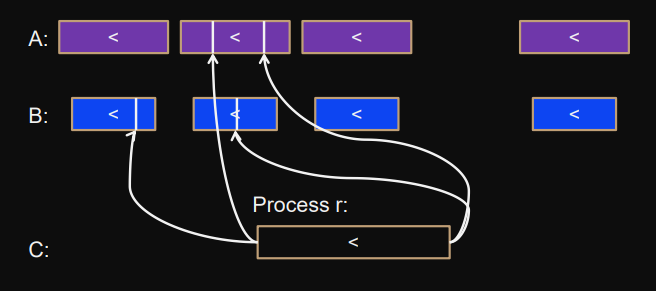
-
Copy partial blocks into intermediate
C’array.One-sided communication (partial block can read elements from other processes).
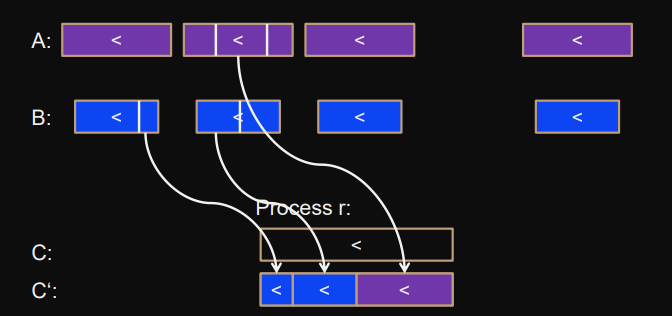
-
Local sequential merge of
C'array intoCblock.
-
Use co-ranking algorithm.
Epoch model, synchronization
Epoch model
Access epoch Origin has access to target
Exposure epoch Target must expose memory
Open epoch start of access or exposure
Close epoch synchronization, communication operations become visible
End of epoch Access and exposure completed (data arrived at target)
Synchronization in epochs
Active (global) synchronization
Active global synchronization (involves origin and target).
Closes previous epoch, opens a new one.
Collective operation, called by all processes in comm of win.
MPI_Win_fence(assert,win);Example
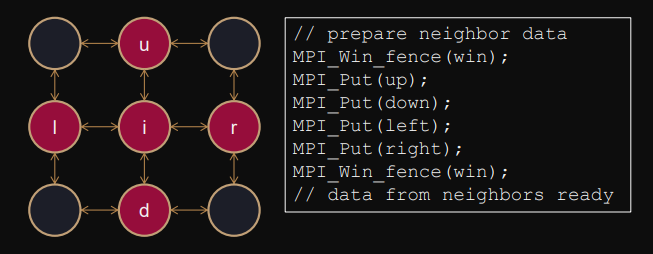
Active (dedicated) synchronization
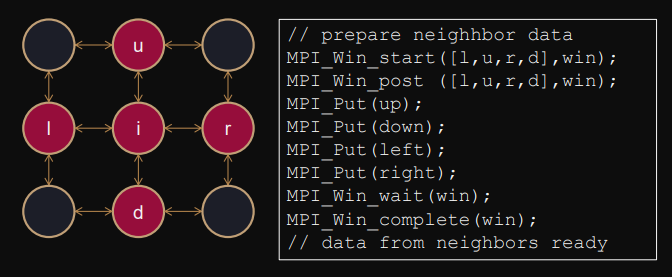
Active global synchronization (involves origin and target).
Pairwise synchronization.
// open/close access epoch (targets)
MPI_Win_start(…,group);
MPI_Win_complete();// open/close exposure epoch (origin)
MPI_Win_post(…,group);
MPI_Win_wait();Example
Passive synchronization
Only origin process involved.
Not a lock (critical section)
difficult to use for mutual exclusion, weak mechanism
// open/close exposure epoch (origin)
MPI_Win_lock(locktype,target,assertion,win);
MPI_Win_unlock(target,win);Collective communication
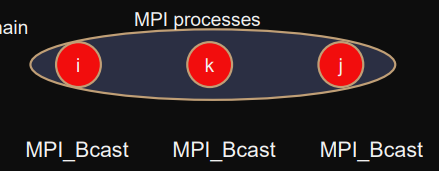
Collective communication
Collective operations = all processes in comm must call given function (all are explicitly involved and must call the same collective communication operation).
Requirements: If a process calls collective operation on comm then all other included processes must also call the same operation and
- no other collective in between
- same root (else it deadlocks)
- consistent arguments (same size and types)
General properties
Collective operations are:
- safe won’t interfere with one another
- blocking completion is non-local and must be fully completed to return
-
not synchronizing any process can return independent of other processes
(except
MPI_Barrier(&com))
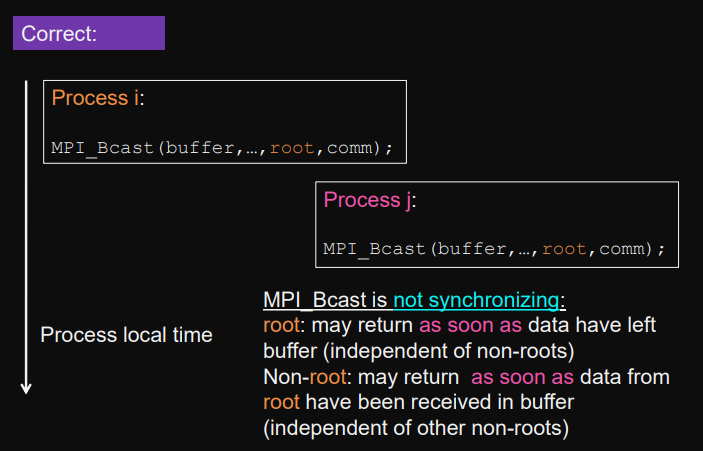
Example:
MPI_BcastBcastsends data from root → all.-
blocking
root: doesn’t return untill data has left buffer
non-root: doesn’t return until data has been received in buffer
-
not synchronizing
any process can return independent of other processes
-
blocking
Example: Safe vs. Unsafe
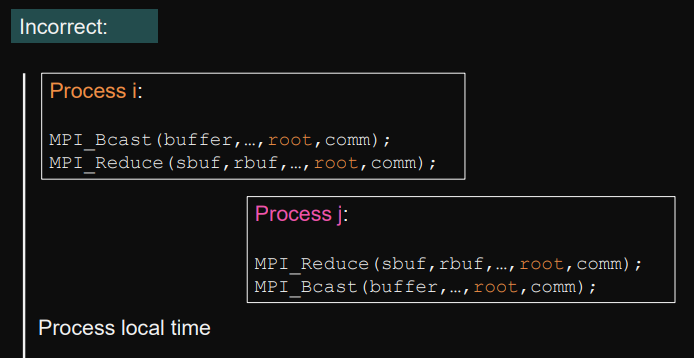
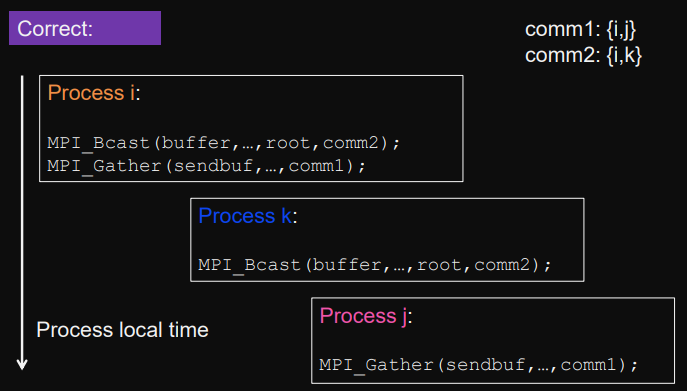
look at comm1/comm2argument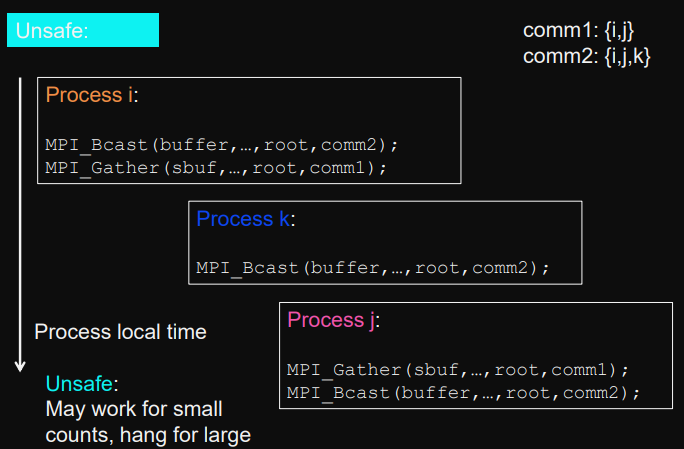
look at comm1/comm2argument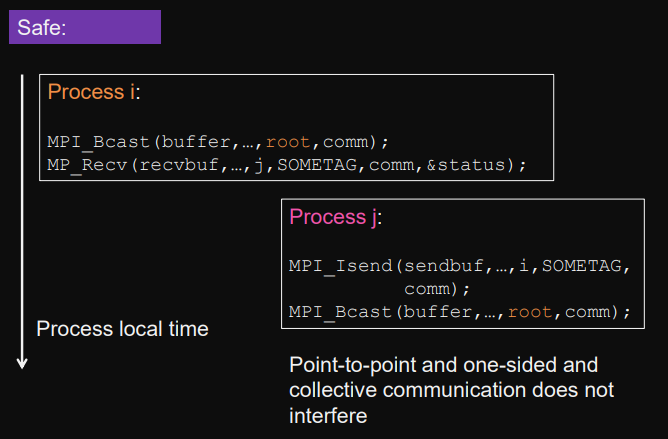
Symmetric vs. Non-symmetric
Symmetric = All processes have the same role
Non-symmetric = Some process (ie. root) is special
Regular vs. irregular
Regular = All processes exchange (send/receive) the same amount of data (segments with the same size and data type)
Irregular, vector, v-collective = Some pairs exchange (send/receive) different amounts of data (different data-types: different sizes, displacements relative to start address).
Examples:
MPI_Gatherv
,
MPI_Scatterv
,
MPI_Allgatherv
,
MPI_Alltoallv
,
MPI_Alltoallw
Differences with point-to-point communication
-
No
tagargument
- Amount of data for sender and receiver must be equal
-
Buffers of size 0 don’t have to be sent
Example: Implementing
no-opwith collective operations“Nothing broadcast”
MPI_Bcast(buffer,0,MPI_CHAR,…,root,comm);MPI_Bcast(buffer,0,MPI_CHAR,…,root,comm);
Example: Implementing
no-opwithSendandRecvMPI_Send(buffer,0,MPI_CHAR,j,TAG,comm);MPI_Recv(buffer,10,MPI_CHAR,j,TAG,comm,&status); // size can be larger
Overview
Collective patterns, operations in MPI
Distributing data
MPI_Bcast
: root → all
MPI_Scatter
: root → all (
personalized
data)
MPI_Gather
: all → root
MPI_Alltoall
: all → all, “transpose” (
personalized
data)
MPI_Allgather
: all → all, “transpose”
Applying associative function (ie. “+”) to data from each process
MPI_Reduce
: result at root
MPI_Allreduce
: result to all
MPI_Reduce_scatter
: result scattered/distributed
MPI_Scan
: prefix-sums
Synchronization
MPI_Barrier
: (semantic) Synchronization
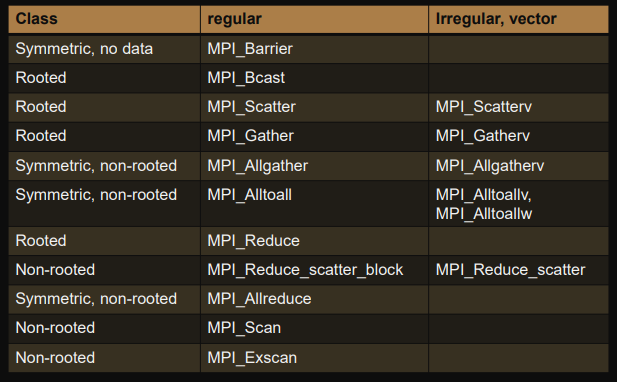
Operations
Duplicating communicators
Duplicates communicator: Same processes, but also copied to different comms.
MPI_Comm_dup(comm, &comm1);comm
can not interfere with
comm1
Example: Usage in libraries
Good practice when writing libraries: here the library uses
libcommand there is no interference.int my_library_init(comm, &libcomm) { MPI_Comm_dup(comm, &libcomm); // store somewhere ... }
Splitting communicators
Partition processes into disjoint sets with independent comms.
MPI_Comm_split(comm1,color,key,&comm2);
MPI_Comm_create(comm1,group,&comm2);
color defines subset in
comm2
key defines relative order in
comm2(for each color)
group
MPI_Group
of ordered processes
Example: Even-odd split
Used in divide and conquer algorithms.
MPI_Comm_rank(comm1,&rank); // get rank in comm1int color = rank%2; int key = 0; MPI_Comm_split(comm1,color,key,&comm2); // split by color// find process' new rank in comm2 MPI_Comm_size(comm2,&newsize); MPI_Comm_rank(comm2,&newrank);if rank even:
color == 0incomm2if rank odd:
color == 1incomm2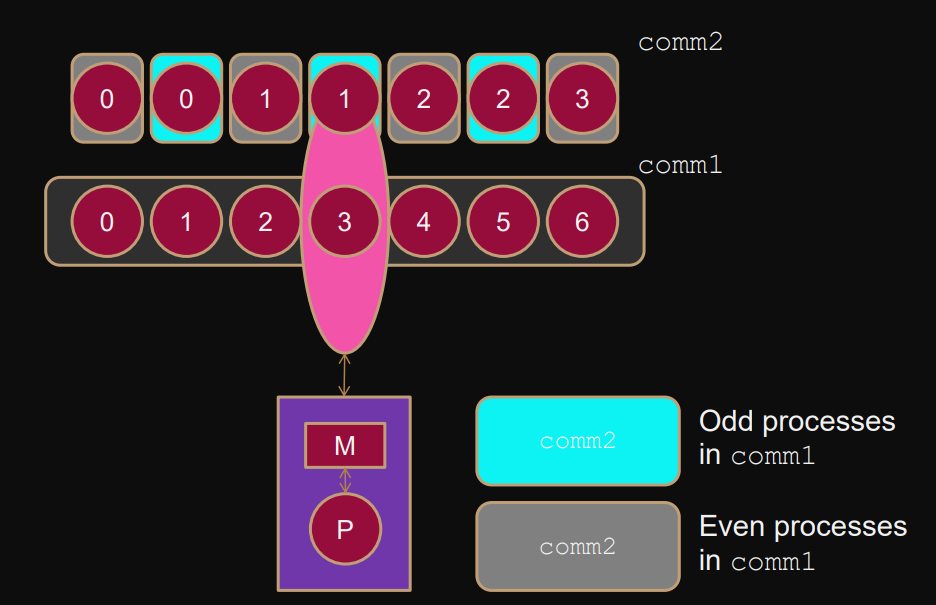
Example: Master-worker pattern (non-scalable)
master gives workers their work, receives result
worker synchronize independently of master
If workers use
MPI_Barrier(comm),MPI_Allgather(comm)and master is doing something else it causes a deadlock. Therefore they have to use the split communicator (only for workers).A) Splitting
int color = (rank>0 ? 1 : 0); int key = 0; MPI_Comm_split(comm,color,key,&workers); // workers for rank>0 in comm: all workers // workers for rank==0 in comm: only master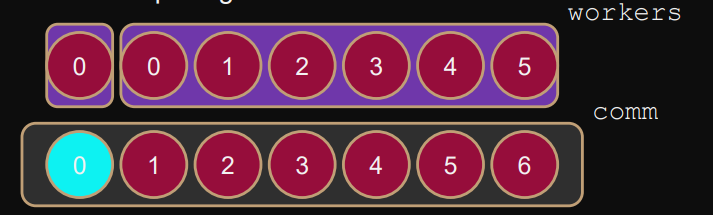
B) Processing groups
MPI_Comm_group(comm,&group); // get processes in comm// exclude rank 0 ranklist[0] = 0; MPI_Group_excl(group,1,ranklist,&workgroup); // group operationMPI_Comm_create(comm,workgroup,&workers); // rank 0 (in comm) not in workers // workers==MPI_COMM_NULL for rank 0 in comm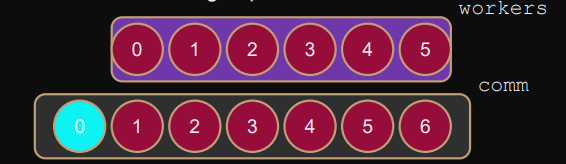
Barrier
(Is the only synchronizing operator)
MPI_Barrier(comm);
Calling process waits for all other processes in
comm
to enter barrier and can only return when they have done so.
Explicit
MPI_Barrier
calls should never be needed for correctness of MPI programs (there is always a way to program without them).
Example: Timing a function
MPI_Barrier(comm); // processes hopefully now synchronizeddouble start = MPI_Wtime(); <something to be timed> double stop = MPI_Wtime();double local_time = stop-start; double spent_time; // time for slowest process MPI_Allreduce(&local_time,&spent_time,1,MPI_DOUBLE,MPI_MAX,comm);
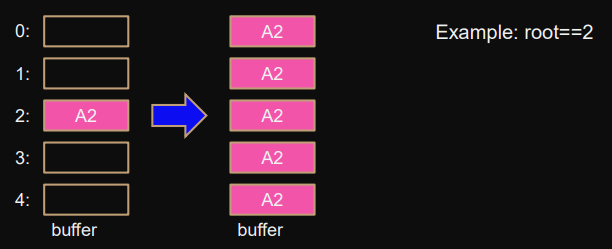
Bcast
distributes data: root → all
MPI_Bcast(buffer,count,datatype,root,comm); // root stays the same for allRoot sends data to all other non-root processes.
Any process can be the root.
Example: Different sizes (unsafe)
int matrixdims[3]; // 3 dimensional matrixif (rank==0) { MPI_Bcast(matrixdims,3,MPI_INT,0,comm); // different sizes: 3 } else { MPI_Bcast(matrixdims,2,MPI_INT,0,comm); // different sizes: 2 }The implementation above probably works, but it’s unsafe
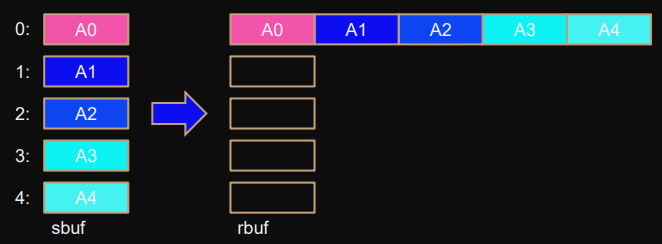
Gather
gathers data: all → root
MPI_Gather(
sbuf,scount,stype, // sender
rbuf,rcount,rtype, // receiver
root,comm
);Alternative
The implementation is much more efficient.
// root if (rank==root) { // receive from others for (…i!=root…) { MPI_Recv(rbuf+i*rcount*extent(rtype),rcount,rtype,i,GATTAG,comm,MPI_STATUS_IGNORE); } // send and receive from self MPI_Sendrecv( sbuf,…,root,…, rbuf+root*rcount*extent(rtype),…,root,… );// others } else { // send MPI_Send(sbuf,scount,stype,root,GATTAG,comm); }
Each process contributes to block of data at buffer
rbuf
in root:
block from process
i
stored at:
rbuf+i*rcount*extent(rtype)
where:
rcountis count of one block, not the wholerbuf
extent(rtype)is the size in bytes spanned by MPI typesie.
extent(MPI_INT) == sizeof(int)
Root also gathers from itself.
can be prevented with
MPI_IN_PLACE
argument for
sbuf
.
this means: result from root is already in place
Scatter
distributes data: root → all (but processes get different blocks)
MPI_Scatter(
sbuf,scount,stype, // send
rbuf,rcount,rtype, // receive
root,comm
);Root sends different block from its buffer to each process.
Blocks stored in rank order at root:
sbuf+i*scount*extent(stype)
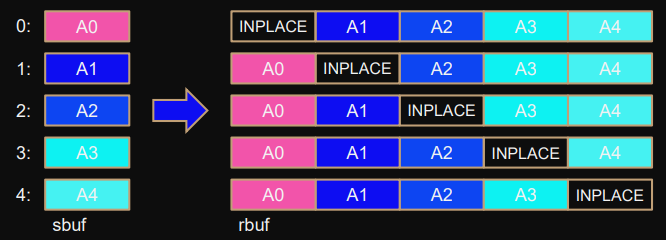
Root also scatters to itself:
can be prevented with
MPI_IN_PLACE
argument for
sbuf
.
this means: result from root is already in place.
Example: Scatter-Gather pattern
Distribute data with
MPI_Scatter(A,...)of size , then collect results withMPI_Gather(B,...).int root = 0; MPI_Comm_size(comm,&p); MPI_Comm_rank(comm,&r); assert(n%p==0); // else use MPI_Scatterv (irregular collective)// allocate a,c and initialize a with values if (rank==root) { int *a = (int*)malloc(n*sizeof(int)); // a: root -> all int *c = (int*)malloc(n*sizeof(int)); // c: root <- all for (i=0; i<n; i++) a[i] = <init>; }// allocate b int *b = (int*)malloc((n/p)*sizeof(int)); // a -> b block -> cMPI_Scatter( // root: a -> b a,n/p,MPI_INT, b,n/p,MPI_INT, root,comm ); ... // compute on b: all processes MPI_Gather( // root: b -> c b,n/p,MPI_INT, c,n/p,MPI_INT, root,comm );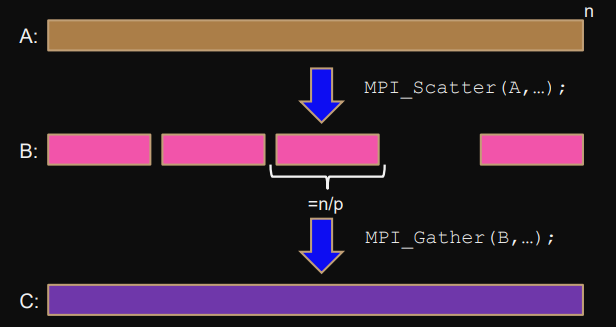
Example: barrier (unsafe)
May have better performance than
send-recvsince we don’t actually send empty messages (but it depends on the implementation → unsafe)MPI_Gather(NULL,0,MPI_BYTE,NULL,0,MPI_BYTE,0,comm); MPI_Scatter(NULL,0,MPI_BYTE,NULL,0,MPI_BYTE,0,comm);


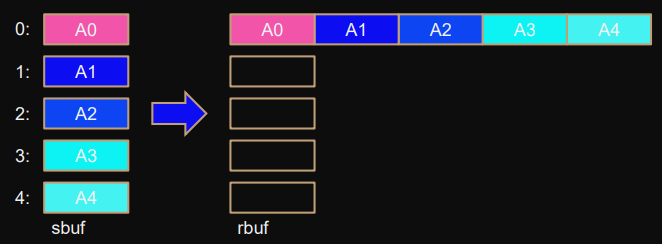
Allgather
MPI_Allgather(
sbuf,scount,stype, // send
rbuf,rcount,rtype, // receive
comm
);Alternative
MPI_Gather(sbuf,…,rbuf,…,0,comm); MPI_Bcast(rbuf,size*rcount,rtype,…,0,comm);for (i) { // all-to-all broadcast if (i==rank) MPI_Bcast(sbuf,…,i,comm); else MPI_Bcast(rbuf+i*rcount*extent(rtype),…,i,comm); } memcpy(rbuf+rank*rcount*extent(rtype),sbuf,…);but performance of library is much better-
It always performs better than
Gather+Bcast.
Each process sends block to
rbuf
of all other processes.
Ends up storing other blocks aswell in order
rbuf+i*rcount*extent(rtype)
Process also sends block to itself: can be prevented with
MPI_IN_PLACE
argument for
sbuf
(must be set for all processes).
Data gets “transposed” (see graphics below).

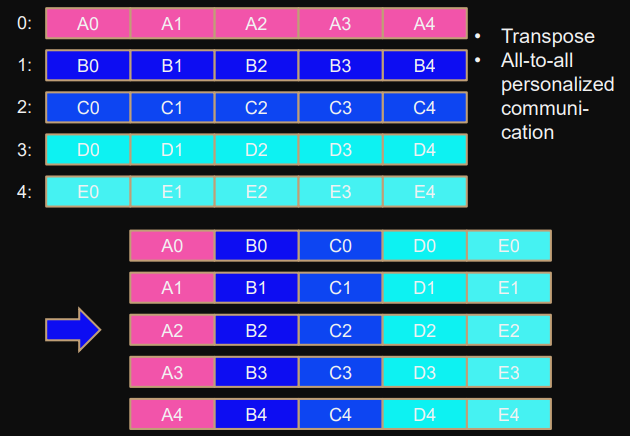
Alltoall
Same as
Allgather
but blocks sent are different for each process.
MPI_Alltoall(
sbuf,scount,stype, // send
rbuf,rcount,rtype, // receive
comm
);Data gets “transposed” (see graphics below).
Each processor contributes to different block of data in other processes.
Block
to
process
i
is stored at:
sbuf+i*scount*extent(stype)
Block
from
process
i
is stored at:
rbuf+i*rcount*extent(rtype)
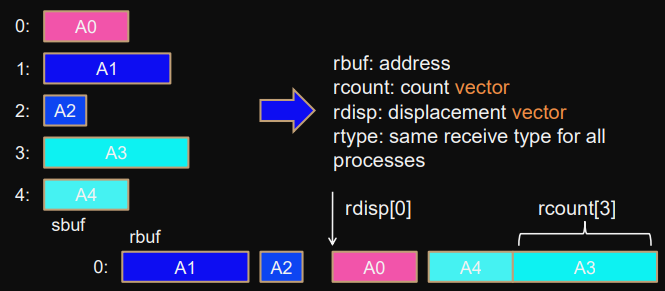
Gatherv
Same as gather but with irregular data.
MPI_Gatherv(
sbuf,scount,stype, // send
rbuf,rcount,rdisp,rtype, // receive (address, count, displacement, type)
root,comm
)Data must not overlap.
Block from process
i
is stored at:
rbuf+disp[i]*extent(rtype)
Example: Root gathers initially unknown amount of data from all processes
scountandrcounts[i]must match.Won’t work if root doesn’t know
scountof other processes.if (rank==root) { MPI_Gatherv(sbuf,…rbuf,rcounts,rdisp,…,comm); // rcounts as array } else { MPI_Gatherv(sbuf,scount,…,comm); // scount }Here we use regular gather to gather the
rcountsarray from all processes.if (rank==root) { MPI_Gather(scount,1,MPI_INT,rcounts,1,MPI_INT,comm); // compute displacements MPI_Gatherv(sbuf,…rbuf,rcounts,rdisp,…,comm); } else { MPI_Gather(scount,1,MPI_INT,rcounts,1,MPI_INT,comm); MPI_Gatherv(sbuf,scount,…,comm); }
Reduction collectives
About reduction collectives
- Each process has vector of data (same size, same type)
-
Associative operation
(built in MPI or user defined)
for element wise reduction
associative means brackets don’t influence result
commutativity can also be exploited
-
stored in
MPI_ReducerootMPI_Allreduceall processesMPI_Allreducescattered in blocks
Operators
One can also register user defined operators
MPI_Op_create(MPI_User_function *function, int commutative, MPI_Op *op);
MPI_Op_free(MPI_Op *op); // free after usage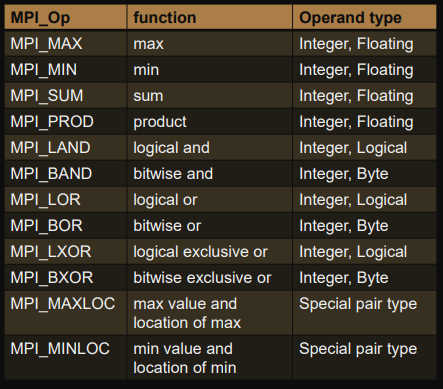
Reduce
MPI_Reduce(sbuf,rbuf,count,type,op,root,comm);MPI_Reduce(
void *sendbuf, void *recvbuf,
int count, // input per processor is a vector
MPI_Datatype datatype,
MPI_Op op, // associative operators (can be user defined)
int root,
MPI_Comm comm
);
Elementwise result stored in
rbuf
at root.
If
MPI_IN_PLACE
as argument for
sbuf
, then input is taken from
rbuf
.
Example: Single scalar
if (rank==root) { x = rank; MPI_Reduce(&x,&y,1,MPI_INT,MPI_SUM,root,comm); if (y!=(size*(size-1))/2) printf("Error!\n"); // y significant at root only } else { x = rank; MPI_Reduce(&x,&y,1,MPI_INT,MPI_SUM,root,comm); }
Example: Ring
Root passes vector to next process ... and so on ... until it reaches root again.
Idea
Creates a binomial tree
Root node is active in every communication round.
Time complexity:
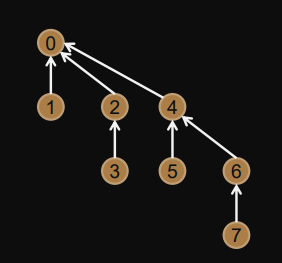
total levels =
Number of nodes at level where :
Algorithm
bit = 0x1;while ((rank&bit)==0x0 & bit<size) { <receive from rank|bit> // bit set bit <<= 1; // shift right } <send to rank | (~bit)> // mask out bit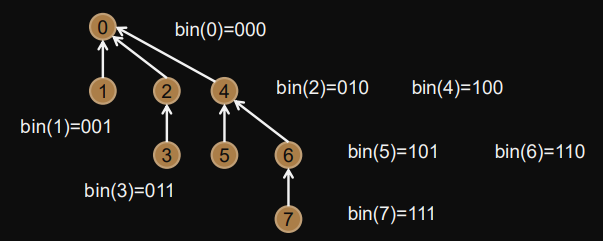
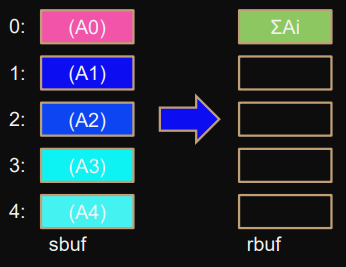
Allreduce
MPI_Allreduce(sbuf,rbuf,count,type,op,comm);
Elementwise result stored in
rbuf
in every process.
If
MPI_IN_PLACE
as argument for
sbuf
, then input is taken from
rbuf
.
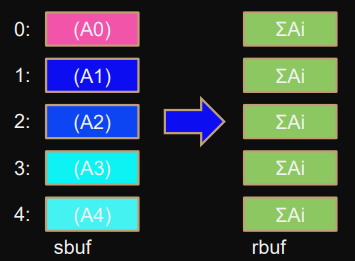
Reduce_scatter_block
MPI_Reduce_scatter_block(sbuf,rbuf,count,type,op,comm);Alternative
Can also be expressed through
Reduce_scatterHere we took an arbitrary size for the counts.
MPI_Reduce_scatter_block(partial,result,n/p,MPI_FLOAT,MPI_SUM,comm);for (i=0; i<p; i++) counts[i] = n/p; MPI_Reduce_scatter(partial,result,counts,MPI_FLOAT,MPI_SUM,comm);
Elementwise result is scattered in same sized blocks, stored in
rbuf
for every process.
If
MPI_IN_PLACE
as argument for
sbuf
, then input is taken from
rbuf
.
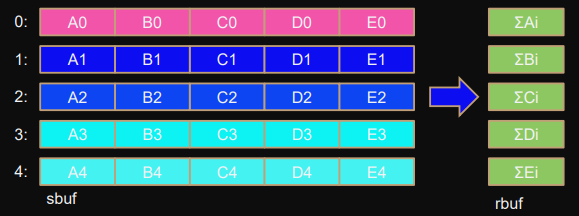
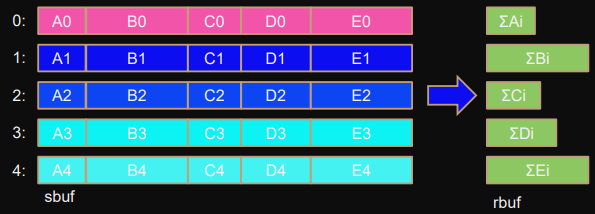
Reduce_scatter
MPI_Reduce_scatter(sbuf,rbuf,counts,type,op,comm);
Same as
Reduce_scatter_block
but the block-sizes can differ.
All processes must have the same
counts[]
.
If
MPI_IN_PLACE
as argument for
sbuf
, then input is taken from
rbuf
.
Scan collectives
About scan collectives
- Each process has vector of data (same size, same type)
-
Associative operation
(built in MPI or user defined)
for element wise calculation of prefix sums
associative means brackets don’t influence result
-
stored in
MPI_Scan at rank MPI_Exscan at rank (undefined for rank )
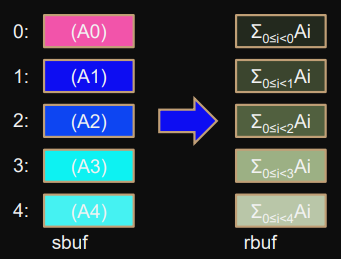
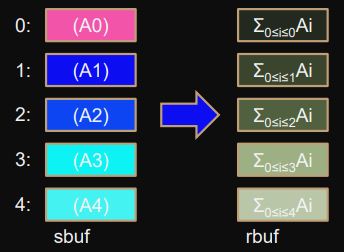
Scan (inclusive prefix sum)
MPI_Scan(sbuf,rbuf,count,type,op,comm);
Elementwise prefix sums over
sbuf
vectors.
Rank
i
stores sum from rank 0 to i (included).
Exscan (exclusive prefix sum)
MPI_Exscan(sbuf,rbuf,count,type,op,comm);
Elementwise prefix sums over
sbuf
vectors.
Rank
i
stores sum from rank 0 to i (included).