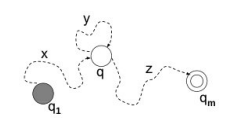
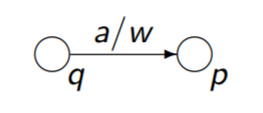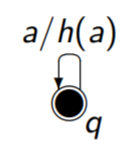DEA erzeugen wobei Endzustände und Nicht-Endzustände vertauscht wurden
Spiegelung
EA erzeugen, wobei Start und Endzustand vertauscht wurden
Homomorphismen
regulärer Ausdruck wo alle
a
mit
h(a)
ersetzt wurden
Homomorphismus
h(L)={h(w)∣w∈L}
h:Σ⟼Γ∗
h(ε)=ε
∀w∈Σ∗,a∈Σ:h(wa)=h(w)h(a)
Reguläre Sprachen sind rekursive Probleme
P={w∣w∈L}(Wortproblem)
Gehört
w
der Sprache
L
an?
Lösung: DEA für
L
erzeugen und
δ∗(q0,w)∈F
prüfen.
P={w∣w∈{}}
Ist
w
leer?
Lösung: DEA für
L
erzeugen und
∃w:δ∗(q0,w)∈F
prüfen.
Ist
L
endlich oder unendlich?
Lösung: Minimale DEA für
L
erzeugen. Falls sie abgesehen von Falle einen Zyklus enthält ist sie unendlich.
Ist
L=L′
?
Lösung: Überprüfen ob
L−L′=L−L′=∅
Endlicher Automat zur regulären Sprache
Zu jeder regulären Sprache
L
gibt es einen endlichen Automaten
A
, sodass
L=L(A)
.
Minimalautomat
Reguläre Sprache
↦
eindeutiger DEA mit minimaler Anzahl an Zuständen
Kann mit dem
Minimierungsalgorithmus von Brozozowski
erhalten werden.
Pumping Lemma für reguläre Sprachen
Nicht-reguläre Sprachen
Wenn es keine DEA für
L
gibt.
Wenn die Sprache unbeschränkten Speicher braucht.
zb wenn wir unbegrenzt viele Zustände brauchen um eine Anzahl zu merken.
L={0n1n∣n≥0}
A={w∣w entha¨lt gleich viele 0 wie 1}
Schubfachprinzip (Pigeonhole principle)
(Teil des Beweises dass Sprache nicht regulär ist)
n+1
Gegenstände auf
n
Schubfächer
⇒
in einem Schubfach müssten 2 Gegenstände sein.
DEA
A
hat
m
Zustände, Wort aus
w
Sprache hat mehr:
∣w∣≥m
Ein Zustand muss mehrfach durchlaufen werden.
Algorithmus:
Zerlege
w
in
xyz
(Abschnitt-1, Schleife, Abschnitt-2)
Alle wörter
xyiz
werden ebenfalls von
A
akzeptiert.
Pumping Lemma für reguläre Sprachen
In unendlichen regulären Sprachen
L
enthält jedes Wort
w∈L
ab einer bestimmten Länge
∣w∣≥m
einen Abschnitt, dass beliebig wiederholt werden kann und trotzdem von der Sprache akzeptiert wenn:
w=xyz
∣xy∣≤m
∣y∣>0
Dann gilt:
∀i≥0:wi=xyiz∈L
Beispiel: Beweis dass Sprache nicht regulär ist
L={anbn∣n≥0}
Beweis durch widerspruch:
Angenommen
L
sei regulär.
Wir wählen irgendein beliebiges
m
und
w∈L
sodass
ambm=w
Daraus folgt
∣w∣≥m
da
∣w∣=2⋅m
Wir wählen irgendeine beliebige Zerlegung
xyz=w
unter den Bedingungen
∣xy∣≤m(für dasmdass vorher bestimmt wurde)
∣y∣>0
xy
kann nur aus Symbol
a
bestehen.
Wir wählen ein einziges beliebiges
i
zB
i=2
Dann müsste wenn
L
regulär wäre, auch
xy2z=am+∣
y
∣bm∈L
Das ist nicht der Fall.
Kontextfreie Sprachen
Kontextfrei bedeutet dass die Ableitungs-Art keine Rolle spielt und man immer mit der kontextfreien Grammatik die selbe Sprache erzeugt.
Beispiele
Wohlgeformte Klammerausdrücke WKA
G=⟨{A},{(,)},{A→ε∣(A)∣AA},A⟩
Palindrome über
{a,b}
G=⟨S,{a,b}{S→ε∣a∣b∣aSa∣bSb},S⟩
Wichtig:
{wwr∣w∈{a,b}∗}
ist nicht dasselbe wie
{w∈{a,b}∗∣w=wr}
(Entscheidungs-)Probleme die über kontextfreie SprachenLdefiniert werden:
Rekursiv
Ist
L
leer / endlich / unendlich?
w∈L
? (Wortproblem)
Nicht rekursiv
L=Σ∗
?
L1=L2
? (Äquivalenzproblem)
L1⊆L2
?
L1∩L2={}
?
Ist
L
regulär?
Ist
L1∩L2
kontextfrei?
Ist
Σ∗−L
kontextfrei?
Satz von Chomsky-Schützenberger
Dyck-Sprachen
Alphabet bestehend aus den Klammerpaaren
1
bis
n
:
Γn={(1,)1,…,(n,)n}
Dn
über das Alphabet
Γn
ist die kleinste Menge für die gilt:
ε∈Dn
v∈Dn⟹(iv)i∈Dn,1≤i≤n
v1,v2∈Dn⟹v1⋅v2∈Dn
Satz von Chomsky-Schützenberger
Jede kontextfreie Sprache ist ein homomorphes Bild von dem Durschschnitt
von einer regulären Sprache mit einer Dyck-Sprache
Sprache
L
ist kontextfrei wenn zu einem
n≥0
es ein
h:Γn∗⟼Σ∗
gibt, sodass:
L=h(Dn∩R)
Wobei
R
eine reguläre Sprache und
Dn
eine Dyck-Sprache über
Γn
ist.
Beispiel
L={anbn∣n≥0}
ist kontextfrei
L=h(D1∩{(}∗{)}∗)
Wir haben als Definitionsmenge für die Homomorphismus-Funktion den Durchschnitt zwischen
D1=()
und
{(}∗{)}∗
.
Die Dyck-Sprache beinhaltet nicht nur nested brackets sondern auch die Konkatenation wie
()()
.
Kontextfreie Sprachen über 1-Element-Alphabet
Jede kontexfreie Sprache über einem einelementigen Alphabet ist regulär.
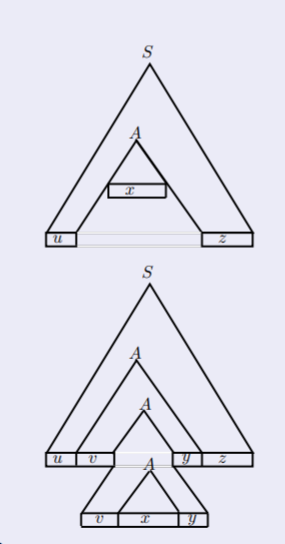
Pumping Lemma für kontextfreie Sprachen
Lemma
Sei
L
eine unendliche kontextfreie Sprache.
∀w∈L:
wenn
∣w∣≥m>0
dann existiert eine Zerlegung
w=uvxyz
∣vxy∣≤m
∣vy∣≥1
Und
∀i≥0:
wi=uvixyiz∈L
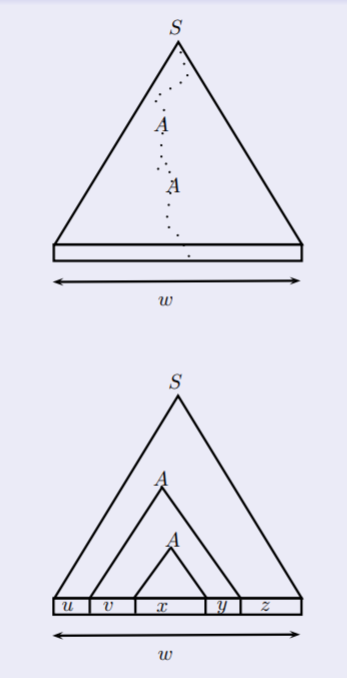
Beweis
Wir wollen beweisen, dass das obige Lemma für kontextfreie Sprachen gilt.
Bei regulären Sprachen argumentiert man mit Zuständen in Pfaden von DEA, hier mit Anzahl der Nonterminale in Pfaden von binären
Ableitungsbäumen (in der Chomsky NF).
Sei
G
eine kontextfreie Grammatik in Chomsky NF.
Der längste Pfad im Ableitungsbaum von
G
hat
kNonterminale
.
Wähle beliebiges
w∈L(G)
mit
∣w∣≥2k=m
Die Konkatenation von allen Terminalen, die an der Front erreicht wurden ist das abgeleitete Wort
Daraus folgt:
Baum muss
≥2
k
Leafs
haben.
Die leafs bestimmen die depth von
lo
g2(2k)=k
.
Es muss einen
Pfad der Länge≥k+1
(inklusive Startsymbol) geben.
Es müssen sich am Pfad
≥k+1
Nonterminale befinden (obwohl wir nur
k
Nonterminale haben.)
Ein Nonterminal muss mindestens doppelt vorkommen.
Es werden Abschnitte im Baum wiederverwendet.
Binärbaum + letzter Ableitungsschritt.
Wir betrachten die Teilwörter für die, die Node / das Nonterminal
A
mehrfach im Pfad vorkommt.
Wir wählen 2 sich wiederholende Abschnitte.
w=u2
v
1
x
y
z
Da das obere
A
, zuständig für Abschnitt 2 nicht leer sein kann, dürfen
v,y
nicht leer sein.
Alternative Möglichkeiten
uxz=uv0xy0z∈L(G)
uvvxyyz=uv2xy2z∈L(G)
Allgemein gilt für jeden Baum
∀i≥0:uvixyiz∈L(G)
Folgerung: Pumping Lemma Kollorar
Für alle Sprachen
L⊆{a}∗
L={a
f
(n)∣n≥0}
mit streng monoton wachsender Funktion
f
in
N
und bijektiver Abbildung
n(k)
für jedes
k
sodass
f(n(k+1))−f(n(k))≥k
gilt,
L
ist nicht kontextfrei.
Beispiele
{ap∣p ist eine Primzahl }
{a2
n
∣n≥0}
Pumping Lemma - Beispiel
L={anbncn∣n≥0}
ist nicht kontextfrei.
Beweis
Angenommen
L
wäre kontextfrei, wählen wir
m
:
w=ambmcm
∀w∈L:∣w∣a=∣w∣b=∣w∣c
∣w∣=3m>m
Wir zerlegen
w
in:
w=uvxyz
u
muss immer das Symbol
a
enthalten,
z
immer das Symbol
c
∣vxy∣≤m
Wir stellen uns diesen Abschnitt wie einen Rahmen vor, den wir über Teilwörter von
w
schieben können.
∣vy∣≥1
Daraus folgt, dass
vxy
nicht gleichzeitig alle 3 Symbole
a,b,c
umfassen kann.
Entweder
∣vxy∣a=0
oder
∣vxy∣c=0
weil sie zu weit auseinander liegen.
Wir untersuchen alle möglichen Fälle:
Fall 1:∣vxy∣c=0
∣vxy∣c=0∧∣vy∣≥1⟹∣vy∣a+∣vy∣b>0
Wir wählen ein beliebiges
i=0
.
w0=uv0xy0z=uxz
Dem pumping Lemma zufolge müsste
w0∈L
Für
uxz
gilt:
∣uxz∣a<∣w∣a
∣uxz∣b<∣w∣b
∣uxz∣c=∣uvxyz∣c=∣w∣c
Das widerspricht
∣uxz∣a=∣uxz∣b=∣uxz∣c
und daraus folgt
uxz=w0∈/L
.
Fall 2:∣vxy∣c>0
∣vxy∣c>0∧∣vy∣≥1⟹∣vxy∣a=0∧∣vy∣b+∣vy∣c>0
Wir wählen ein beliebiges
i=0
.
w0=uv0xy0z=uxz
Für
uxz
gilt:
∣uxz∣a=∣uvxyz∣a=∣w∣a
∣uxz∣b<∣w∣b
∣uxz∣c<∣w∣c
Das widerspricht
∣uxz∣a=∣uxz∣b=∣uxz∣c
und daraus folgt
uxz∈/L
.
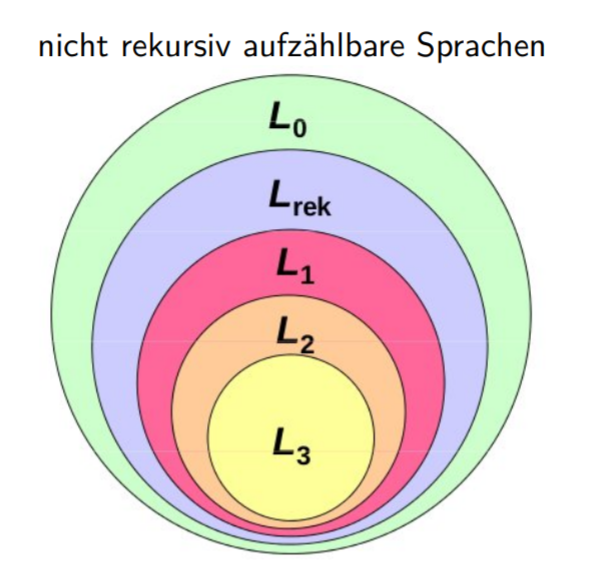
Sprachfamilien
Sprachfamilien
Die Menge aller formalen Sprachen
L⊆Σ∗
die von einer Typ-
i∈{0,1,2,3}
Grammatik erzeugt werden können nennt man
Li(Σ)
.
Die Familie nennt man
Li
.
Typ-0:A→b,A→BC,AD→BC,b∈T∪{ε}Typ-1:A→b,A→BC,AD→BC,b∈TTyp-2:A→b,A→BC,b∈TTyp-3:A→b,A→bC,b∈T\begin{array}{lll} \text { Typ-0: } & A \rightarrow b, \quad A \rightarrow B C, \quad A D \rightarrow B C, & b \in T \cup\{\varepsilon\} \\ \text { Typ-1: } & A \rightarrow b, \quad A \rightarrow B C, \quad A D \rightarrow B C, & b \in T \\ \text { Typ-2: } & A \rightarrow b, \quad A \rightarrow B C, & b \in T \\ \text { Typ-3: } & A \rightarrow b, \quad A \rightarrow b C, & b \in T \end{array}Typ-0:Typ-1:Typ-2:Typ-3:A→b,A→BC,AD→BC,A→b,A→BC,AD→BC,A→b,A→BC,A→b,A→bC,b∈T∪{ε}b∈Tb∈Tb∈T
Für
1,2,3
ist
S→ε
erlaubt wenn
S
nicht auf rechten Seite der Produktion ist.
L0
rekursiv aufzählbar
L1
kontextsensitiv
L2
kontextfrei
L3
regulär
Rekursive SprachenLrec (Σ)
L∈L0(Σ)
ist rekursiv,
wenn
Σ∗−L=Lˉ∈L0(Σ)
ist.
Wortproblem
Das Problem
w∈L
ist für rekursive Sprachen entscheidbar.
Beweis
Berechne schrittweise alle möglichen Wörter in
n
Ableitungsschritten in Grammatik
G
bzw
G′
für das Komplement der Sprache.
Abschlusseigenschaften
L3L2L1L0VereinigungjajajajaKonkatenationjajajajaKleenescher SternjajajajaKomplementjaneinjaneinDurchschnittjaneinjajaDurchschnitt mit reg. MengenjajajajaHomomorphismenjajaneinjaε-freie Homomorphismenjajajajainverse Homomorphismenjajajajagsm-Abbildungenjajaneinjaε-freie gsm-Abbildungenjajajaja\small \begin{array}{|l|l|l|l|l|}\hline & \mathcal{L}_{3} & \mathcal{L}_{2} & \mathcal{L}_{1} & \mathcal{L}_{0} \\\hline \text { Vereinigung } & \text { ja } & \text { ja } & \text { ja } & \text { ja } \\\hline \text { Konkatenation } & \text { ja } & \text { ja } & \text { ja } & \text { ja } \\\hline \text { Kleenescher Stern } & \text { ja } & \text { ja } & \text { ja } & \text { ja } \\\hline \text { Komplement } & \text { ja } & \text { nein } & \text { ja } & \text { nein } \\\hline \text { Durchschnitt } & \text { ja } & \text { nein } & \text { ja } & \text { ja } \\\hline \text { Durchschnitt mit reg. Mengen } & \text { ja } & \text { ja } & \text { ja } & \text { ja } \\\hline \text { Homomorphismen } & \text { ja } & \text { ja } & \text { nein } & \text { ja } \\\hline \varepsilon \text {-freie Homomorphismen } & \text { ja } & \text { ja } & \text { ja } & \text { ja } \\\hline \text { inverse Homomorphismen } & \text { ja } & \text { ja } & \text { ja } & \text { ja } \\\hline \text { gsm-Abbildungen } & \text { ja } & \text { ja } & \text { nein } & \text { ja } \\\hline \varepsilon \text {-freie gsm-Abbildungen } & \text { ja } & \text { ja } & \text { ja } & \text { ja } \\\hline\end{array}VereinigungKonkatenationKleenescher SternKomplementDurchschnittDurchschnitt mit reg. MengenHomomorphismenε-freie Homomorphismeninverse Homomorphismengsm-Abbildungenε-freie gsm-AbbildungenL3jajajajajajajajajajajaL2jajajaneinneinjajajajajajaL1jajajajajajaneinjajaneinjaL0jajajaneinjajajajajajaja